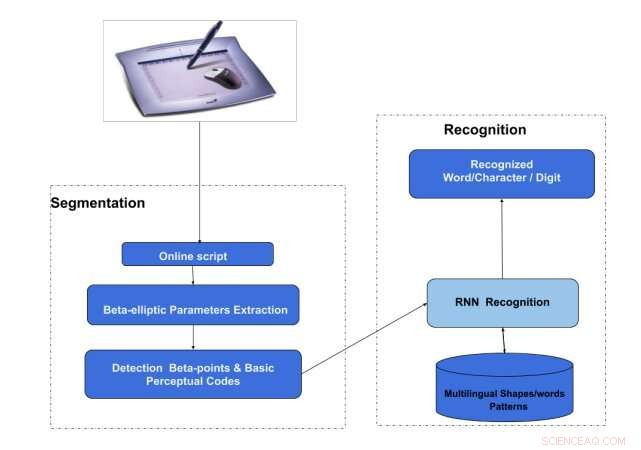
L'architecture de l'OnHS-LSTM. Crédit :Akouaydi et al.
Chercheurs de l'Université de Sfax, en Tunisie, ont récemment développé une nouvelle méthode pour reconnaître les caractères et symboles manuscrits dans les scripts en ligne. Leur technique, présenté dans un article pré-publié sur arXiv, a déjà réalisé des performances remarquables sur des textes écrits en alphabet latin et arabe.
Dans les années récentes, les chercheurs ont créé des architectures basées sur les réseaux de neurones qui peuvent s'attaquer à une variété de tâches, y compris la classification des images, reconnaissance de visage, traitement du langage naturel (TAL), et beaucoup plus. Les systèmes de reconnaissance de l'écriture manuscrite sont des outils informatiques spécialement conçus pour reconnaître les caractères et autres symboles manuscrits de la même manière que les humains.
Dans leurs premières années de vie, En réalité, les êtres humains développent de manière innée la capacité de comprendre différents types d'écriture manuscrite en identifiant des caractères spécifiques à la fois individuellement et lorsqu'ils sont regroupés. Au cours de la dernière décennie, de nombreuses études ont tenté de reproduire cette capacité dans les systèmes informatiques, car cela permettrait à terme des analyses plus avancées et automatiques des textes manuscrits.
« Notre article traite du problème de la reconnaissance de scripts manuscrits en ligne sur la base d'un système de fonctionnalités d'extraction et d'un système d'approche approfondie pour la classification des séquences, ", écrivent les chercheurs dans leur article. "Nous avons utilisé une méthode existante combinée à de nouveaux classificateurs afin d'obtenir un système flexible."
Dans leur papier, les chercheurs de l'Université de Sfax présentent deux systèmes basés sur des réseaux de neurones profonds :un système de segmentation et de reconnaissance d'écriture manuscrite en ligne qui utilise un réseau de mémoire à long court terme (OnHSR-LSTM) et un système de reconnaissance d'écriture manuscrite en ligne composé d'un long short-court convolutif. réseau de mémoire à terme (OnHR-covLSTM).
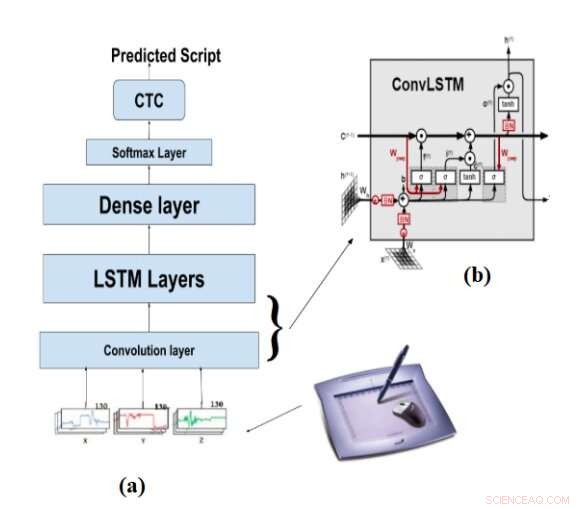
L'architecture de (a) OnHR-convLSTM, (b) la cellule convLSTM. Crédit :Akouaydi et al.
Leur premier modèle, surnommé OnHSR-LSTM, est basé sur une théorie qui décrit le système perceptif humain comme un moyen de transformer le langage des marques graphiques en représentations symboliques. Il fonctionne en détectant les propriétés communes des symboles ou des caractères, puis en les organisant selon des lois perceptives spécifiques, par exemple, basé sur la proximité, similarité, etc.
"Finalement, il [le modèle] tente de construire une représentation de la forme manuscrite basée sur l'hypothèse que la perception de la forme est l'identification des caractéristiques de base qui sont arrangées jusqu'à ce que nous identifions un objet, " les chercheurs ont expliqué dans leur article. " Par conséquent, la représentation de l'écriture manuscrite est une combinaison de traits primitifs. L'écriture manuscrite est une séquence de codes de base qui sont regroupés pour définir un caractère ou une forme."
La première technique proposée par les chercheurs divise essentiellement une écriture manuscrite en traits elliptiques individuels à l'aide d'un modèle de génération d'écriture manuscrite. Ensuite, ces traits sont classés en codes primitifs, qui sont utilisés par l'architecture neuronale pour reconnaître les mots dans les scripts manuscrits en ligne.
Le deuxième système proposé par les chercheurs, OnHR-convLSTM, est un modèle génératif qui utilise le signal en ligne d'un script comme entrée et est entraîné pour prédire à la fois les caractères et les mots. Cette seconde technique est particulièrement utile pour les tâches d'apprentissage de séquences (c'est-à-dire les tâches qui impliquent le traitement et la classification de longues séquences de caractères et de symboles).
Les chercheurs ont formé et évalué leurs deux systèmes à l'aide de cinq bases de données différentes contenant des écritures manuscrites dans les alphabets arabe et latin. Leurs tests ont donné des résultats remarquables, avec les deux systèmes atteignant des taux de reconnaissance de plus de 98 pour cent. De façon intéressante, les chercheurs ont découvert que les performances des deux techniques sont comparables à celles généralement obtenues par des sujets humains dans des tâches similaires.
« Nous prévoyons maintenant de développer et de tester nos systèmes de reconnaissance proposés sur une base de données à grande échelle et d'autres scripts, ", ont écrit les chercheurs.
© 2019 Réseau Science X