Brookhaven Lab a collaboré avec l'Université de Columbia, Université d'Édimbourg, et Intel pour optimiser les performances d'un ordinateur parallèle à 144 nœuds construit à partir des processeurs Xeon Phi d'Intel et du réseau de communication à haut débit Omni-Path. L'ordinateur est installé au centre de données scientifiques et de calcul de Brookhaven, comme vu ci-dessus avec l'ingénieur en technologie Costin Caramarcu. Crédit :Laboratoire national de Brookhaven
Le calcul haute performance (HPC) - l'utilisation de superordinateurs et de techniques de traitement parallèle pour résoudre de grands problèmes de calcul - est d'une grande utilité dans la communauté scientifique. Par exemple, Les scientifiques du laboratoire national de Brookhaven du département de l'Énergie des États-Unis (DOE) s'appuient sur le HPC pour analyser les données qu'ils collectent dans les installations expérimentales à grande échelle sur place et pour modéliser des processus complexes qui seraient trop coûteux ou impossibles à démontrer expérimentalement.
Applications scientifiques modernes, comme la simulation d'interactions de particules, nécessitent souvent une combinaison de puissance de calcul agrégée, réseaux à haut débit pour le transfert de données, grande quantité de mémoire, et des capacités de stockage de grande capacité. Des progrès dans le matériel et les logiciels HPC sont nécessaires pour répondre à ces exigences. Les informaticiens et informaticiens et les mathématiciens de la Computational Science Initiative (CSI) de Brookhaven Lab collaborent avec des physiciens, biologistes, et d'autres scientifiques du domaine pour comprendre leurs besoins en analyse de données et fournir des solutions pour accélérer le processus de découverte scientifique.
Un leader de l'industrie HPC
Depuis des décennies, Intel Corporation a été l'un des leaders dans le développement de technologies HPC. En 2016, la société a sorti les processeurs Intel Xeon PhiTM (anciennement nommés "Knights Landing"), son architecture HPC de deuxième génération qui intègre de nombreuses unités de traitement (cœurs) par puce. La même année, Intel a lancé le réseau de communication à haut débit Intel Omni-Path Architecture. Pour le 5, 000 à 100, 000 ordinateurs individuels, ou des nœuds, dans les supercalculateurs modernes pour travailler ensemble pour résoudre un problème, ils doivent pouvoir communiquer rapidement entre eux tout en minimisant les délais du réseau.
Peu de temps après ces sorties, Laboratoire de Brookhaven et RIKEN, La plus grande institution de recherche complète du Japon, ont mis leurs ressources en commun pour acheter un petit ordinateur parallèle à 144 nœuds construit à partir de processeurs Xeon Phi et de deux connexions réseau indépendantes, ou des rails, en utilisant l'architecture Omni-Path d'Intel. L'ordinateur a été installé au centre de données et de calcul scientifique de Brookhaven Lab, qui fait partie de CSI.
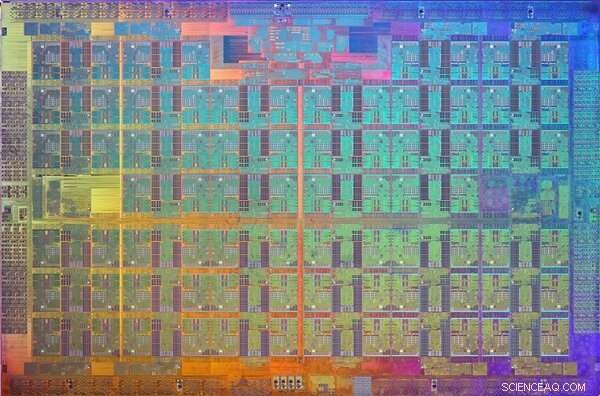
Une image de la matrice du processeur Xeon Phi Knights Landing. Un dé est un motif sur une plaquette de matériau semi-conducteur qui contient les circuits électroniques pour exécuter une fonction particulière. Crédit :Intel
Une fois l'installation terminée, le physicien Chulwoo Jung et le informaticien Meifeng Lin du Brookhaven Lab; le physicien théoricien Christoph Lehner, une personne nommée conjointement au Brookhaven Lab et à l'Université de Ratisbonne en Allemagne ; Christ normand, le professeur Ephraim Gildor de physique théorique computationnelle à l'Université Columbia; et le physicien théorique des particules Peter Boyle de l'Université d'Édimbourg ont travaillé en étroite collaboration avec les ingénieurs logiciels d'Intel pour optimiser le logiciel de réseau pour deux applications scientifiques :la physique des particules et l'apprentissage automatique.
« CSI s'était beaucoup intéressé à l'architecture Intel Omni-Path depuis son annonce en 2015, " a déclaré Lin. " L'expertise des ingénieurs d'Intel a été essentielle à la mise en œuvre des optimisations logicielles qui nous ont permis de tirer pleinement parti de ce réseau de communication hautes performances pour nos besoins applicatifs spécifiques. "
Exigences de réseau pour les applications scientifiques
Pour de nombreuses applications scientifiques, exécuter un rang (une valeur qui distingue un processus d'un autre) ou éventuellement quelques rangs par nœud sur un ordinateur parallèle est beaucoup plus efficace que d'exécuter plusieurs rangs par nœud. Chaque rang s'exécute généralement en tant que processus indépendant qui communique avec les autres rangs à l'aide d'un protocole standard connu sous le nom de Message Passing Interface (MPI).
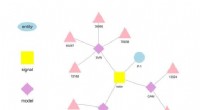
Par exemple, les physiciens cherchant à comprendre comment l'univers primitif s'est formé exécutent des simulations numériques complexes d'interactions de particules basées sur la théorie de la chromodynamique quantique (QCD). Cette théorie explique comment les particules élémentaires appelées quarks et gluons interagissent pour former les particules que nous observons directement, comme les protons et les neutrons. Les physiciens modélisent ces interactions en utilisant des superordinateurs qui représentent les trois dimensions de l'espace et la dimension du temps dans un réseau à quatre dimensions (4-D) de points également espacés, semblable à celui d'un cristal. Le réseau est divisé en sous-volumes identiques plus petits. Pour les calculs QCD sur réseau, les données doivent être échangées aux frontières entre les différents sous-volumes. S'il y a plusieurs rangs par nœud, chaque rang héberge un sous-volume 4-D différent. Ainsi, le fractionnement des sous-volumes crée plus de frontières où les données doivent être échangées et donc des transferts de données inutiles qui ralentissent les calculs.
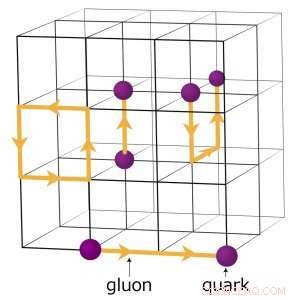
Un schéma du réseau pour les calculs de chromodynamique quantique. Les points d'intersection sur la grille représentent les valeurs des quarks, tandis que les lignes entre elles représentent les valeurs de gluons. Crédit :Laboratoire national de Brookhaven
Optimisations logicielles pour faire avancer la science
Pour optimiser le logiciel de réseau pour une application scientifique aussi intensive en calculs, l'équipe s'est concentrée sur l'amélioration de la vitesse d'un seul rang.
« Nous avons accéléré l'exécution du code pour un seul rang MPI afin qu'une prolifération de rangs MPI ne soit pas nécessaire pour gérer la charge de communication importante présente pour chaque nœud, " expliqua le Christ.
Le logiciel de rang MPI exploite le parallélisme threadé disponible sur les nœuds Xeon Phi. Le parallélisme threadé fait référence à l'exécution simultanée de plusieurs processus, ou des fils, qui suivent les mêmes instructions tout en partageant certaines ressources informatiques. Avec le logiciel optimisé, l'équipe a été en mesure de créer plusieurs canaux de communication sur un seul rang et de piloter ces canaux à l'aide de différents fils.
Le logiciel MPI était désormais configuré pour que les applications scientifiques s'exécutent plus rapidement et tirent pleinement parti du matériel de communication Intel Omni-Path. Mais après avoir implémenté le logiciel, les membres de l'équipe ont rencontré un autre défi :à chaque course, quelques nœuds communiqueraient inévitablement lentement et retiendraient les autres.
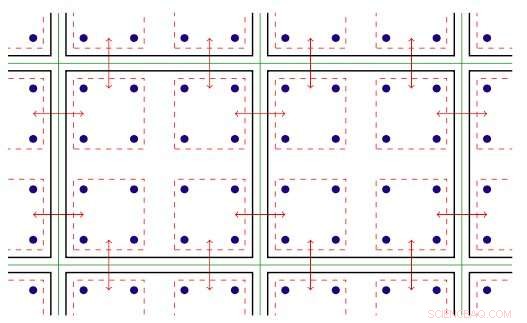
Illustration en deux dimensions du parallélisme fileté. Légende :les lignes vertes séparent les nœuds de calcul physiques ; des lignes noires séparent les rangs MPI ; les lignes rouges sont les contextes de communication, avec les flèches indiquant la communication entre les nœuds ou la copie mémoire au sein d'un nœud via le matériel Intel Omni-Path. Crédit :Laboratoire national de Brookhaven
Ils ont attribué ce problème à la façon dont Linux, le système d'exploitation utilisé par la majorité des plates-formes HPC, gère la mémoire. Dans son mode par défaut, Linux divise la mémoire en petits morceaux appelés pages. En reconfigurant Linux pour utiliser de grandes pages mémoire ("énormes"), ils ont résolu le problème. L'augmentation de la taille de la page signifie que moins de pages sont nécessaires pour mapper l'espace d'adressage virtuel qu'une application utilise. Par conséquent, la mémoire est accessible beaucoup plus rapidement.
Avec les améliorations logicielles, les membres de l'équipe ont analysé les performances des nœuds de calcul Intel Omni-Path Architecture et Intel Xeon Phi installés sur le cluster à double rail "Diamond" d'Intel et le cluster à rail unique DiRAC (Distributed Research Using Advanced Computing) au Royaume-Uni. Pour leur analyse, ils ont utilisé deux classes différentes d'applications scientifiques :la physique des particules et l'apprentissage automatique. Pour les deux codes d'application, ils ont atteint des performances proches de la vitesse filaire, le taux maximum théorique de transfert de données. Cette amélioration représente une augmentation des performances du réseau qui est entre quatre et dix fois celle des codes d'origine.
"En raison de l'étroite collaboration entre Brookhaven, Edinbourg, et Intel, ces optimisations ont été rendues disponibles dans le monde entier dans une nouvelle version de l'implémentation Intel Omni-Path MPI et un protocole de bonnes pratiques pour configurer la gestion de la mémoire Linux, " dit Christ. " L'accélération du facteur cinq dans l'exécution du code de physique sur l'ordinateur Xeon Phi du Brookhaven Lab—et sur le nouvel ordinateur de l'Université d'Édimbourg, un ordinateur « hypercube » Hewlett Packard Enterprise, encore plus gros, à 800 nœuds, est maintenant utilisé à bon escient dans les études en cours sur les questions fondamentales de la physique des particules.