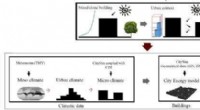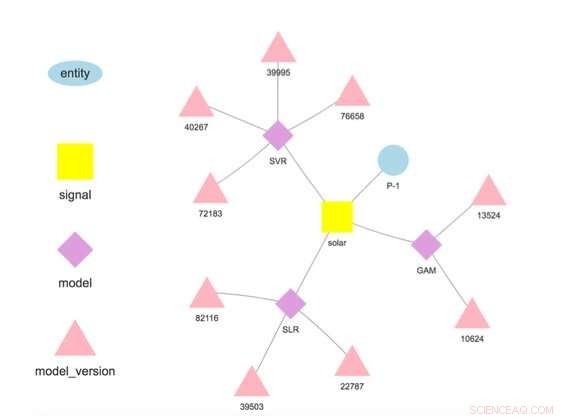
Figure 1. Hiérarchie du modèle pour une entité et un signal sélectionnés. Crédit :IBM
Cette semaine à la Conférence internationale sur l'exploration de données, Le scientifique d'IBM Research-Irlande, Francesco Fusco, a fait la démonstration d'IBM Research Castor, un système de gestion des données de séries chronologiques et des modèles à l'échelle et sur le cloud. Les entreprises d'aujourd'hui fonctionnent sur des prévisions. Qu'il s'agisse d'une intuition de ce que nous pensons qui va arriver ou du produit d'une analyse soigneusement affinée, nous avons une image de ce qui va se passer et nous agissons en conséquence. IBM Research Castor est destiné aux entreprises axées sur l'IoT qui ont besoin de centaines ou de milliers de prévisions différentes pour les séries chronologiques. Bien que le modèle d'une prévision individuelle puisse être petit, suivre la provenance et les performances de ce nombre de modèles peut être un défi. Contrairement aux cas pilotés par l'IA utilisant un petit nombre de grands modèles pour le traitement d'images ou le langage naturel, ce travail vise les applications IoT nécessitant un grand nombre de modèles plus petits.
Notre système fournit un ensemble riche mais sélectif de capacités pour les données et les modèles de séries chronologiques. Il ingère des données provenant d'appareils IoT ou d'autres sources. Il donne accès aux données à l'aide de la sémantique, permettant aux utilisateurs de récupérer des données comme ceci :getTimeseries( myServer, "Magasin1234", « revenu horaire »).
Il stocke des modèles écrits en R ou Python pour l'entraînement et la notation. Chaque modèle est associé à une entité décrivant l'origine des données, comme "Store1234" ci-dessus, et un signal décrivant ce qui est mesuré, comme "revenu horaire". Les modèles sont entraînés et notés à des fréquences définies par l'utilisateur, et contrairement à de nombreuses autres offres, les prévisions sont stockées automatiquement.
Les data scientists déploient des modèles en mettant en œuvre un workflow en quatre étapes :
Une fois le modèle déployé, le système effectue la formation et la notation, stocker automatiquement le modèle entraîné et les résultats des prévisions. Les données utilisées dans la formation et la notation n'ont pas besoin de provenir de la plate-forme, permettant aux modèles d'utiliser des données provenant de plusieurs sources. En réalité, il s'agit d'une motivation clé pour notre travail :faire des prévisions à valeur ajoutée basées sur de multiples sources de données. Par exemple, une entreprise peut combiner certaines de ses propres données avec des données achetées auprès d'un tiers, comme les prévisions météorologiques, pour prédire une quantité d'intérêt.
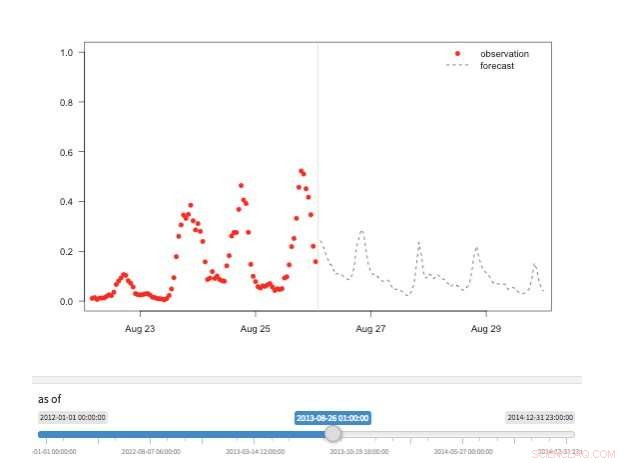
Figure 2. Vue « machine à remonter le temps » montrant les observations et prévisions disponibles pour différents points de l'histoire. Crédit :IBM
Notre système stocke les modèles séparément des paramètres de configuration et d'exécution. Cette séparation permet de changer certains détails d'un modèle, comme la clé API pour accéder aux données tierces ou la fréquence de scoring, sans redéploiement. Plusieurs modèles pour la même variable cible sont pris en charge et encouragés pour permettre des comparaisons de prévisions de différents algorithmes. Les modèles peuvent être enchaînés de sorte que la sortie d'un modèle forme l'entrée d'un autre comme dans un ensemble. Un modèle formé sur un jeu de données spécifique représente une version de modèle, qui est également suivi. Ainsi, il est possible d'établir la provenance des modèles et des prévisions (Figure 1).
Plusieurs vues sont disponibles pour explorer les valeurs de prévision. Bien sûr, les valeurs elles-mêmes peuvent être récupérées et visualisées. Nous prenons également en charge une vue « machine à remonter le temps » montrant les dernières prévisions et les dernières observations (Figure 2). Dans cette vue interactive, l'utilisateur peut sélectionner différents points de l'historique et voir quelles informations étaient disponibles à ce moment-là. Nous soutenons également une vue de l'évolution des prévisions montrant des prévisions successives pour le même point dans le temps (Figure 3). De cette façon, les utilisateurs peuvent voir comment les prévisions ont changé à mesure que l'heure cible se rapprochait.
Sous la capuche, IBM Research Castor fait un usage intensif de l'informatique sans serveur pour offrir une élasticité des ressources et un contrôle des coûts. Les déploiements typiques voient des modèles formés chaque semaine ou chaque mois et notés toutes les heures. Au moment de l'entraînement ou de la notation, une fonction serverless est créée pour chaque modèle, permettant à des centaines de modèles de s'entraîner ou de marquer en parallèle au moment souhaité. Une fois ce travail terminé, la ressource informatique disparaît jusqu'à ce qu'on en ait à nouveau besoin. Dans un flux de travail plus conventionnel, les machines virtuelles ou les conteneurs cloud sont inactifs lorsqu'ils ne sont pas utilisés mais continuent d'attirer des coûts.
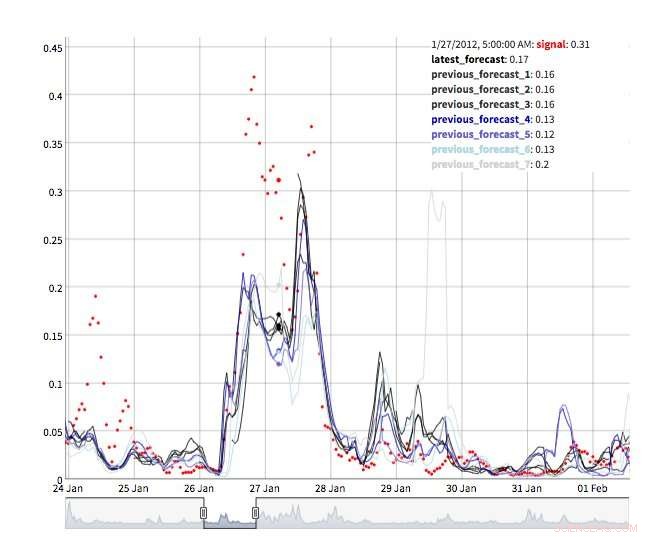
Figure 3. Évolution des prévisions. Crédit :IBM
IBM Research Castor se déploie nativement sur IBM Cloud en utilisant les derniers services tels que DashDB d'IBM, Composer, Fonctions Cloud, et Kubernetes pour fournir un système robuste et fiable. Avec un compte autorisé sur IBM Cloud, IBM Research Castor se déploie en quelques minutes, ce qui le rend idéal pour les projets de validation de principe ainsi que pour les projets à plus long terme. Des packages clients / SDK pour Python et R sont fournis afin que les scientifiques des données puissent être rapidement opérationnels dans un environnement familier et que les équipes de visualisation puissent tirer parti de frameworks familiers tels que Django et Shiny. Si ceux-ci ne conviennent pas à votre application, l'API de messagerie basée sur JSON est également disponible.
Cette histoire est republiée avec l'aimable autorisation d'IBM Research. Lisez l'histoire originale ici.