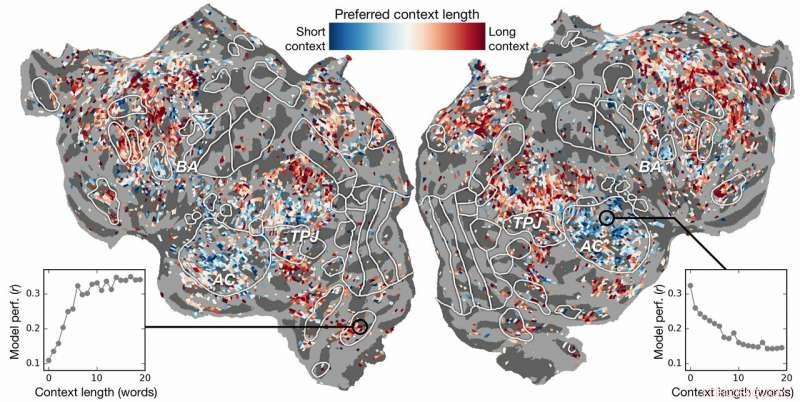
Préférence de longueur de contexte à travers le cortex. Un indice de préférence de longueur de contexte est calculé pour chaque voxel chez un sujet et projeté sur la surface corticale de ce sujet. Les voxels affichés en bleu sont mieux modélisés en utilisant un contexte court, tandis que les voxels rouges sont mieux modélisés avec un contexte long. Crédit :Huth lab, UT Austin
L'intelligence artificielle (IA) peut-elle nous aider à comprendre comment le cerveau comprend le langage ? Les neurosciences peuvent-elles nous aider à comprendre pourquoi l'IA et les réseaux de neurones sont efficaces pour prédire la perception humaine ?
Les recherches d'Alexander Huth et de Shailee Jain de l'Université du Texas à Austin (UT Austin) suggèrent que les deux sont possibles.
Dans un article présenté à la Conférence 2018 sur les systèmes de traitement de l'information neuronale (NeurIPS), les chercheurs ont décrit les résultats d'expériences utilisant des réseaux de neurones artificiels pour prédire avec plus de précision que jamais comment différentes zones du cerveau réagissent à des mots spécifiques.
"Alors que les mots nous viennent à l'esprit, nous nous faisons des idées sur ce que quelqu'un nous dit, et nous voulons comprendre comment cela nous vient à l'intérieur du cerveau, " dit Huth, professeur adjoint de neurosciences et d'informatique à l'UT Austin. "Il semble qu'il devrait y avoir des systèmes pour cela, mais pratiquement, ce n'est pas comme ça que le langage fonctionne. Comme tout en biologie, il est très difficile de réduire à un simple ensemble d'équations."
Le travail a utilisé un type de réseau neuronal récurrent appelé mémoire à long court terme (LSTM) qui inclut dans ses calculs les relations de chaque mot avec ce qui l'a précédé pour mieux préserver le contexte.
« Si un mot a plusieurs sens, vous déduisez le sens de ce mot pour cette phrase particulière en fonction de ce qui a été dit plus tôt, " dit Jaïn, un doctorat étudiant dans le laboratoire de Huth à UT Austin. "Notre hypothèse est que cela conduirait à de meilleures prédictions de l'activité cérébrale parce que le cerveau se soucie du contexte."
Cela semble évident, mais pendant des décennies, les expériences en neurosciences ont considéré la réponse du cerveau à des mots individuels sans avoir le sens de leur lien avec des chaînes de mots ou de phrases. (Huth décrit l'importance de faire des « neurosciences du monde réel » dans un article de mars 2019 dans le Journal des neurosciences cognitives .)
Dans leur travail, les chercheurs ont mené des expériences pour tester, et finalement prédire, comment différentes zones du cerveau réagiraient en écoutant des histoires (en particulier, l'heure de la radio des mites). Ils ont utilisé des données collectées à partir de machines IRMf (imagerie par résonance magnétique fonctionnelle) qui capturent les changements du niveau d'oxygénation du sang dans le cerveau en fonction de l'activité des groupes de neurones. Cela sert de correspondant pour l'endroit où les concepts du langage sont « représentés » dans le cerveau.
En utilisant de puissants supercalculateurs au Texas Advanced Computing Center (TACC), ils ont formé un modèle de langage à l'aide de la méthode LSTM afin qu'il puisse prédire efficacement quel mot viendrait ensuite - une tâche semblable aux recherches de saisie semi-automatique de Google, auquel l'esprit humain est particulièrement habile.
"En essayant de prédire le mot suivant, ce modèle doit implicitement apprendre toutes ces autres choses sur le fonctionnement du langage, " dit Huth, "comme quels mots ont tendance à suivre d'autres mots, sans jamais accéder réellement au cerveau ou à des données sur le cerveau."
Sur la base à la fois du modèle de langage et des données d'IRMf, ils ont formé un système capable de prédire comment le cerveau réagirait lorsqu'il entendrait pour la première fois chaque mot d'une nouvelle histoire.
Les efforts passés avaient montré qu'il est possible de localiser efficacement les réponses linguistiques dans le cerveau. Cependant, la nouvelle recherche a montré que l'ajout de l'élément contextuel (dans ce cas jusqu'à 20 mots précédents) améliorait considérablement les prédictions de l'activité cérébrale. Ils ont constaté que leurs prédictions s'amélioraient même lorsque le moins de contexte était utilisé. Plus le contexte fourni, meilleure est la précision de leurs prédictions.
"Notre analyse a montré que si le LSTM incorpore plus de mots, alors il s'améliore pour prédire le mot suivant, " dit Jaïn, "ce qui signifie qu'il doit inclure des informations de tous les mots du passé."
La recherche est allée plus loin. Il a exploré quelles parties du cerveau étaient plus sensibles à la quantité de contexte inclus. Ils ont trouvé, par exemple, que les concepts qui semblent être localisés dans le cortex auditif étaient moins dépendants du contexte.
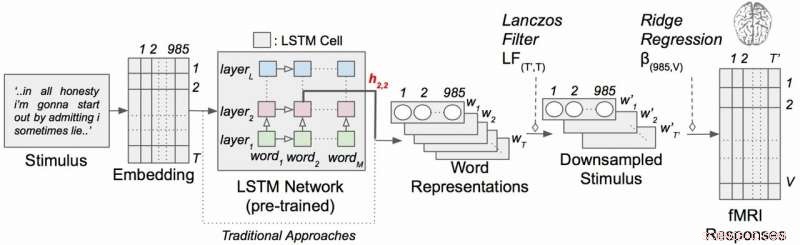
Modèle d'encodage de langage contextuel avec des stimuli narratifs. Chaque mot de l'histoire est d'abord projeté dans un espace d'intégration de 985 dimensions. Des séquences de représentations de mots sont ensuite introduites dans un réseau LSTM qui a été pré-entraîné en tant que modèle de langage. Crédit :Huth lab, UT Austin
« Si vous entendez le mot chien, cette zone ne se soucie pas de ce qu'étaient les 10 mots avant cela, il va juste répondre au son du mot chien", expliqua Huth.
D'autre part, les zones du cerveau qui traitent de la pensée de niveau supérieur étaient plus faciles à identifier lorsque plus de contexte était inclus. Cela soutient les théories de l'esprit et la compréhension du langage.
"Il y avait une très belle correspondance entre la hiérarchie du réseau artificiel et la hiérarchie du cerveau, que nous avons trouvé intéressant, " dit Huth.
Le traitement du langage naturel (ou PNL) a fait de grands progrès ces dernières années. Mais quand il s'agit de répondre aux questions, avoir des conversations naturelles, ou analyser les sentiments dans des textes écrits, La PNL a encore un long chemin à parcourir. Les chercheurs pensent que leur modèle de langage développé par LSTM peut aider dans ces domaines.
Le LSTM (et les réseaux de neurones en général) fonctionne en attribuant des valeurs dans un espace de grande dimension à des composants individuels (ici, mots) afin que chaque composant puisse être défini par ses milliers de relations disparates avec beaucoup d'autres choses.
Les chercheurs ont formé le modèle de langage en le nourrissant de dizaines de millions de mots tirés de publications Reddit. Leur système a ensuite fait des prédictions sur la façon dont des milliers de voxels (pixels tridimensionnels) dans le cerveau de six sujets réagiraient à une deuxième série d'histoires que ni le modèle ni les individus n'avaient entendues auparavant. Parce qu'ils s'intéressaient aux effets de la longueur du contexte et à l'effet des couches individuelles dans le réseau de neurones, ils ont essentiellement testé 60 facteurs différents (20 longueurs de rétention de contexte et trois dimensions de couches différentes) pour chaque sujet.
Tout cela conduit à des problèmes de calcul à une échelle énorme, nécessitant des quantités massives de puissance de calcul, Mémoire, espace de rangement, et la récupération des données. Les ressources de la TACC étaient bien adaptées au problème. Les chercheurs ont utilisé le supercalculateur Maverick, qui contient à la fois des GPU et des CPU pour les tâches de calcul, et Corral, une ressource de stockage et de gestion des données, conserver et diffuser les données. En parallélisant le problème sur de nombreux processeurs, ils ont pu exécuter l'expérience de calcul en semaines plutôt qu'en années.
« Pour développer efficacement ces modèles, vous avez besoin de beaucoup de données d'entraînement, " Huth a déclaré. "Cela signifie que vous devez passer par l'ensemble de votre ensemble de données chaque fois que vous souhaitez mettre à jour les poids. Et c'est intrinsèquement très lent si vous n'utilisez pas de ressources parallèles comme celles de TACC."
Si cela semble complexe, et bien ça l'est.
Cela conduit Huth et Jain à envisager une version plus rationalisée du système, où au lieu de développer un modèle de prédiction du langage puis de l'appliquer au cerveau, ils développent un modèle qui prédit directement la réponse cérébrale. Ils appellent cela un système de bout en bout et c'est là que Huth et Jain espèrent aller dans leurs futures recherches. Un tel modèle améliorerait ses performances directement sur les réponses cérébrales. Une prédiction erronée de l'activité cérébrale entraînerait un retour d'information dans le modèle et stimulerait des améliorations.
« Si cela fonctionne, alors il est possible que ce réseau puisse apprendre à lire le texte ou la langue d'admission de la même manière que notre cerveau le fait, " dit Huth. " Imaginez Google Translate, mais il comprend ce que tu dis, au lieu de simplement apprendre un ensemble de règles."
Avec un tel système en place, Huth pense que ce n'est qu'une question de temps jusqu'à ce qu'un système de lecture mentale capable de traduire l'activité cérébrale en langage soit réalisable. En attendant, ils acquièrent des connaissances à la fois sur les neurosciences et l'intelligence artificielle grâce à leurs expériences.
"Le cerveau est une machine de calcul très efficace et le but de l'intelligence artificielle est de construire des machines qui sont vraiment douées pour toutes les tâches qu'un cerveau peut accomplir, " dit Jain. " Mais, nous ne comprenons pas grand-chose au cerveau. Donc, nous essayons d'utiliser l'intelligence artificielle pour d'abord questionner le fonctionnement du cerveau, puis, sur la base des connaissances acquises grâce à cette méthode d'interrogation, et grâce aux neurosciences théoriques, nous utilisons ces résultats pour développer une meilleure intelligence artificielle.
"L'idée est de comprendre les systèmes cognitifs, à la fois biologique et artificiel, et de les utiliser en tandem pour comprendre et construire de meilleures machines."