Un modèle élaboré par des chercheurs du MIT et de Microsoft identifie les cas où les voitures autonomes ont « appris » à partir d'exemples de formation qui ne correspondent pas à ce qui se passe réellement sur la route, qui peut être utilisé pour identifier les actions apprises qui pourraient provoquer des erreurs dans le monde réel. Crédit :Nouvelles du MIT
Un nouveau modèle développé par les chercheurs du MIT et de Microsoft identifie les cas dans lesquels les systèmes autonomes ont « appris » à partir d'exemples de formation qui ne correspondent pas à ce qui se passe réellement dans le monde réel. Les ingénieurs pourraient utiliser ce modèle pour améliorer la sécurité des systèmes d'intelligence artificielle, tels que les véhicules sans conducteur et les robots autonomes.
Les systèmes d'IA alimentant les voitures sans conducteur, par exemple, sont largement formés aux simulations virtuelles pour préparer le véhicule à presque tous les événements sur la route. Mais parfois la voiture fait une erreur inattendue dans le monde réel parce qu'un événement se produit qui devrait, mais ne le fait pas, modifier le comportement de la voiture.
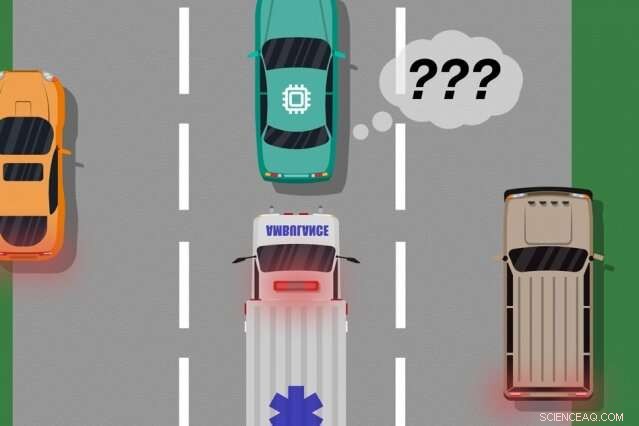
Considérez une voiture sans conducteur qui n'a pas été formée, et surtout n'a pas les capteurs nécessaires, faire la différence entre des scénarios nettement différents, comme grand, voitures blanches et ambulances avec du rouge, feux clignotants sur la route. Si la voiture roule sur l'autoroute et qu'une ambulance actionne ses sirènes, la voiture peut ne pas savoir ralentir et s'arrêter, car il ne perçoit pas l'ambulance comme différente d'une grosse voiture blanche.
Dans deux articles présentés lors de la conférence Autonomous Agents and Multiagent Systems de l'année dernière et de la prochaine conférence de l'Association for the Advancement of Artificial Intelligence, les chercheurs décrivent un modèle qui utilise l'apport humain pour découvrir ces "angles morts" de formation.
Comme pour les approches traditionnelles, les chercheurs ont soumis un système d'IA à une formation par simulation. Mais alors, un humain surveille de près les actions du système lorsqu'il agit dans le monde réel, fournir des commentaires lorsque le système a fait, ou était sur le point de faire, toutes les erreurs. Les chercheurs combinent ensuite les données d'entraînement avec les données de rétroaction humaine, et utiliser des techniques d'apprentissage automatique pour produire un modèle qui identifie les situations où le système a probablement besoin de plus d'informations sur la façon d'agir correctement.
Les chercheurs ont validé leur méthode à l'aide de jeux vidéo, avec un humain simulé corrigeant le chemin appris d'un personnage à l'écran. Mais la prochaine étape consiste à incorporer le modèle aux approches traditionnelles de formation et de test pour les voitures autonomes et les robots avec rétroaction humaine.
"Le modèle aide les systèmes autonomes à mieux savoir ce qu'ils ne savent pas, " dit le premier auteur Ramya Ramakrishnan, un étudiant diplômé du Laboratoire d'informatique et d'intelligence artificielle. "À plusieurs reprises, lorsque ces systèmes sont déployés, leurs simulations entraînées ne correspondent pas au cadre du monde réel [et] ils pourraient faire des erreurs, comme entrer dans des accidents. L'idée est d'utiliser des humains pour combler ce fossé entre la simulation et le monde réel, en toute sécurité, afin que nous puissions réduire certaines de ces erreurs."
Les co-auteurs des deux articles sont :Julie Shah, professeur agrégé au Département d'aéronautique et d'astronautique et chef du Groupe de robotique interactive du CSAIL; et Ece Kamar, Debadeepta Dey, et Eric Horvitz, tous de Microsoft Research. Besmira Nushi est un co-auteur supplémentaire du prochain article.
Prendre des commentaires
Certaines méthodes d'entraînement traditionnelles fournissent un retour d'information humain lors des tests en conditions réelles, mais uniquement pour mettre à jour les actions du système. Ces approches n'identifient pas les angles morts, ce qui pourrait être utile pour une exécution plus sûre dans le monde réel.
L'approche des chercheurs soumet d'abord un système d'IA à une formation par simulation, où il produira une "politique" qui mappe essentiellement chaque situation à la meilleure action qu'il peut prendre dans les simulations. Puis, le système sera déployé dans le monde réel, où les humains fournissent des signaux d'erreur dans les régions où les actions du système sont inacceptables.
Les humains peuvent fournir des données de plusieurs manières, comme par le biais de « démonstrations » et de « corrections ». Dans les manifestations, les actes humains dans le monde réel, tandis que le système observe et compare les actions de l'humain à ce qu'il aurait fait dans cette situation. Pour les voitures sans conducteur, par exemple, un humain contrôlerait manuellement la voiture pendant que le système produit un signal si son comportement prévu s'écarte du comportement de l'humain. Les correspondances et les discordances avec les actions humaines fournissent des indications bruyantes de l'endroit où le système pourrait agir de manière acceptable ou inacceptable.
Alternativement, l'humain peut apporter des corrections, avec l'humain qui surveille le système tel qu'il agit dans le monde réel. Un humain pourrait s'asseoir dans le siège du conducteur pendant que la voiture autonome suit son itinéraire prévu. Si les actions de la voiture sont correctes, l'humain ne fait rien. Si les actions de la voiture sont incorrectes, cependant, l'humain peut prendre le volant, qui envoie un signal que le système n'agissait pas de manière inacceptable dans cette situation spécifique.
Une fois les données de rétroaction de l'humain compilées, le système a essentiellement une liste de situations et, pour chaque situation, plusieurs étiquettes disant que ses actions étaient acceptables ou inacceptables. Une même situation peut recevoir de nombreux signaux différents, parce que le système perçoit de nombreuses situations comme identiques. Par exemple, une voiture autonome peut avoir roulé plusieurs fois à côté d'une grosse voiture sans ralentir ni s'arrêter. Mais, dans un seul cas, une ambulance, qui apparaît exactement le même au système, croisières par. La voiture autonome ne s'arrête pas et reçoit un signal de retour indiquant que le système a effectué une action inacceptable.
"À ce moment, le système a reçu de multiples signaux contradictoires d'un humain :certains avec une grosse voiture à côté, et ça marchait bien, et un où il y avait une ambulance exactement au même endroit, mais ce n'était pas bien. Le système fait une petite note qu'il a fait quelque chose de mal, mais il ne sait pas pourquoi, " dit Ramakrishnan. " Parce que l'agent reçoit tous ces signaux contradictoires, la prochaine étape consiste à compiler les informations à demander, « Quelle est la probabilité que je fasse une erreur dans cette situation où j'ai reçu ces signaux mitigés ? »"
Agrégation intelligente
L'objectif final est d'étiqueter ces situations ambiguës comme des angles morts. Mais cela va au-delà du simple décompte des actions acceptables et inacceptables pour chaque situation. Si le système a effectué des actions correctes neuf fois sur 10 dans la situation d'ambulance, par exemple, un vote à la majorité simple qualifierait cette situation de sûre.
"Mais parce que les actions inacceptables sont beaucoup plus rares que les actions acceptables, le système finira par apprendre à prédire toutes les situations comme sûres, ce qui peut être extrêmement dangereux, " dit Ramakrishnan.
À cette fin, les chercheurs ont utilisé l'algorithme de Dawid-Skene, une méthode d'apprentissage automatique couramment utilisée pour le crowdsourcing pour gérer le bruit des étiquettes. L'algorithme prend en entrée une liste de situations, chacun ayant un ensemble d'étiquettes "acceptables" et "inacceptables" bruyantes. Ensuite, il agrège toutes les données et utilise des calculs de probabilité pour identifier des modèles dans les étiquettes des angles morts prédits et des modèles pour les situations de sécurité prévues. En utilisant ces informations, il génère une seule étiquette « sûre » ou « angle mort » agrégée pour chaque situation ainsi qu'un niveau de confiance dans cette étiquette. Notamment, l'algorithme peut apprendre dans une situation où il peut avoir, par exemple, exécuté de manière acceptable 90 % du temps, la situation est encore suffisamment ambiguë pour mériter un « angle mort ».
À la fin, l'algorithme produit un type de "carte thermique, " où chaque situation de la formation initiale du système se voit attribuer une probabilité faible à élevée d'être un angle mort pour le système.
« Lorsque le système est déployé dans le monde réel, il peut utiliser ce modèle appris pour agir avec plus de prudence et d'intelligence. Si le modèle appris prédit qu'un état est un angle mort avec une forte probabilité, le système peut interroger un humain pour l'action acceptable, permettant une exécution plus sûre, " dit Ramakrishnan.
Cette histoire est republiée avec l'aimable autorisation de MIT News (web.mit.edu/newsoffice/), un site populaire qui couvre l'actualité de la recherche du MIT, innovation et enseignement.