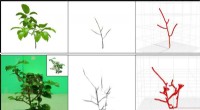
Crédit :Prasad, Das &Bhowmick.
Des chercheurs du groupe Systèmes embarqués et robotique de TCS Research &Innovation ont récemment développé un réseau de profondeur à deux vues pour déduire la profondeur et le mouvement de l'ego à partir de séquences monoculaires consécutives. Leur approche, présenté dans un article pré-publié sur arXiv, intègre également des contraintes épipolaires, qui améliorent la compréhension géométrique du réseau.
"Notre idée principale était d'essayer de prédire la profondeur au niveau des pixels et le mouvement de la caméra directement à partir de séquences d'images uniques, " Dr Brojeshwar Bhowmick, l'un des chercheurs qui a mené l'étude, a déclaré TechXplore. "Traditionnellement, la structure des algorithmes de reconstruction basés sur le mouvement fournit des sorties de profondeur éparses pour les points d'intérêt saillants de l'image, qui sont suivis sur plusieurs images à l'aide d'une géométrie multi-vues. Avec l'apprentissage en profondeur qui gagne en popularité dans les tâches de vision par ordinateur, nous avons pensé à tirer parti des méthodes existantes pour aider notre cause en abordant le problème d'une manière plus fondamentale en utilisant une combinaison de concepts de géométrie épipolaire et d'apprentissage en profondeur."
La plupart des approches d'apprentissage en profondeur existantes pour prédire la profondeur monoculaire et le mouvement de l'ego optimisent la cohérence photométrique dans les séquences d'images en déformant une vue dans une autre. En inférant la profondeur à partir d'une seule vue, cependant, ces méthodes peuvent échouer à capturer la relation entre les pixels et donc à fournir des correspondances de pixels appropriées.
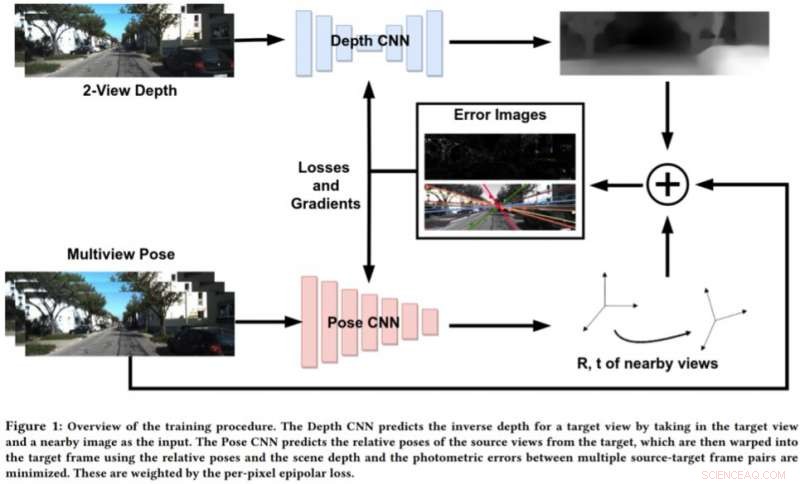
Pour pallier les limites de ces approches, Bhowmick et ses collègues ont développé une nouvelle approche qui combine la vision géométrique par ordinateur et les paradigmes d'apprentissage en profondeur. Leur approche utilise deux réseaux de neurones, une pour prédire la profondeur d'une vue de référence unique et une pour prédire les poses relatives d'un ensemble de vues par rapport à la vue de référence.

Crédit :Prasad, Das &Bhowmick.
"La scène de l'image cible peut être reconstruite à partir de l'une des poses données en les déformant en fonction de la profondeur et des poses relatives, " expliqua Bhowmick. " Compte tenu de cette image reconstruite et de l'image de référence, on calcule l'erreur dans les intensités des pixels, qui agit comme notre principale perte. Nous ajoutons la nouveauté d'utiliser la perte épipolaire par pixel, un concept de géométrie multi-vues, dans la perte globale, ce qui assure de meilleures correspondances et a l'avantage supplémentaire de ne pas tenir compte des objets en mouvement dans la scène qui pourraient autrement détériorer l'apprentissage."
Plutôt que de prédire la profondeur en analysant une seule image, cette nouvelle approche fonctionne en analysant une paire d'images d'une vidéo et en apprenant les relations inter-pixels pour prédire la profondeur. Cela ressemble un peu aux algorithmes SLAM/SfM traditionnels, qui peut observer les mouvements des pixels au fil du temps.
"Les résultats les plus significatifs de notre étude sont que l'utilisation de deux vues pour prédire la profondeur fonctionne mieux qu'une seule image, et que même une faible application des correspondances au niveau des pixels via des contraintes épipolaires fonctionne bien, " a déclaré Bhowmick. " Une fois que ces méthodes mûrissent et améliorent leur généralisabilité, on pourrait les appliquer pour la perception sur les drones, où l'on voudrait extraire un maximum d'informations sensorielles en consommant le moins d'énergie possible, ce qui peut être réalisé en utilisant une seule caméra."
Dans les évaluations préliminaires, les chercheurs ont découvert que leur méthode pouvait prédire la profondeur avec une plus grande précision que les approches existantes, produisant des estimations de profondeur plus précises et des estimations de pose améliorées. Cependant, actuellement, leur approche ne peut effectuer que des inférences au niveau des pixels. Des travaux futurs pourraient remédier à cette limitation en intégrant la sémantique de la scène dans le modèle, ce qui pourrait conduire à de meilleures corrélations entre les objets de la scène et les estimations de la profondeur et du mouvement de l'ego.
"Nous approfondissons la généralisation de cette méthode et d'autres méthodes similaires sur diverses scènes, aussi bien à l'intérieur qu'à l'extérieur, " dit Bhowmick. " Actuellement, la plupart des travaux fonctionnent bien sur les données extérieures, telles que les données de conduite, mais fonctionnent très mal sur des séquences en intérieur avec des mouvements arbitraires."
© 2019 Réseau Science X