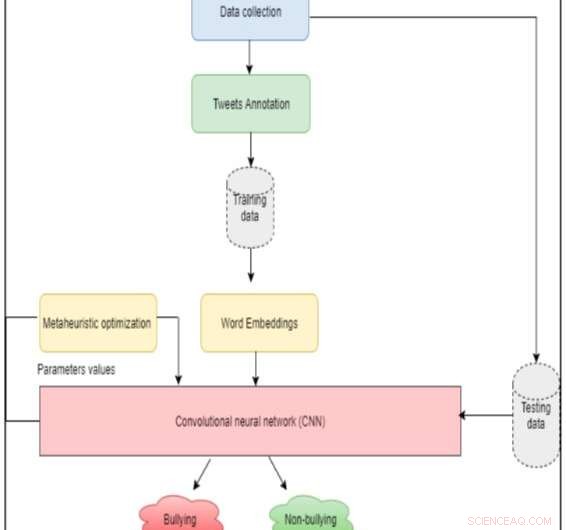
L'architecture du système. Crédit :Al-Ajlan &Ykhlef.
Chercheurs de l'Université King Saud, en Arabie Saoudite, ont développé une nouvelle approche pour détecter la cyberintimidation sur Twitter en utilisant l'apprentissage en profondeur appelé OCDD. Contrairement à d'autres approches d'apprentissage en profondeur, qui extraient les caractéristiques des tweets et les transmettent à un classificateur, leur méthode représente un tweet comme un ensemble de vecteurs de mots.
Dans les années récentes, la cyberintimidation sur les réseaux sociaux est devenue un problème énorme et largement débattu. La cyberintimidation implique l'utilisation de canaux de communication en ligne pour intimider d'autres utilisateurs en envoyant des messages intimidants, messages menaçants ou abusifs. Cela peut avoir des conséquences psychologiques et parfois mortelles pour les victimes.
Des chercheurs du monde entier ont essayé de développer de nouvelles façons de détecter la cyberintimidation, le gérer et réduire sa prévalence sur les réseaux sociaux. De nombreuses approches d'apprentissage en profondeur pour identifier le travail de cyberintimidation en analysant les caractéristiques textuelles et utilisateur. Cependant, ces techniques présentent plusieurs limitations, ce qui peut réduire considérablement leurs performances.
Par exemple, certaines de ces approches tentent d'améliorer la détection en introduisant de nouvelles fonctionnalités. Pourtant, augmenter le nombre de fonctionnalités peut compliquer les phases d'extraction et de sélection des fonctionnalités. De plus, ces approches ne considèrent pas que certaines données utilisateur, comme l'âge et la date de naissance, peut être facilement fabriqué. Pour remédier aux limites des méthodes existantes de détection de la cyberintimidation, Monirah A. Al-Ajlan et Mourad Ykhlef, deux chercheurs de l'Université King Saud, a proposé une nouvelle approche appelée détection optimisée de la cyberintimidation sur Twitter (OCDD).
"Contrairement aux travaux antérieurs dans ce domaine, OCDD n'extrait pas les caractéristiques des tweets et ne les transmet pas à un classificateur :plutôt, il représente un tweet comme un ensemble de vecteurs de mots, " expliquent les chercheurs dans leur article, publié sur IEEE Explore et présenté au 21 st Conférence nationale sur l'informatique de la société saoudienne d'informatique (NCC). "De cette façon, la sémantique des mots est préservée, et les phases d'extraction et de sélection des caractéristiques peuvent être éliminées."
Al-Ajlan et Ykhlef ont construit leur approche sur des données d'apprentissage étiquetées et ont généré des intégrations de mots pour des mots individuels à l'aide de GloVe, un algorithme d'apprentissage non supervisé qui peut obtenir des représentations vectorielles pour les mots. Ces inclusions de mots sont ensuite transmises à un réseau de neurones convolutifs (CNN) pour détecter s'ils pourraient être associés à la cyberintimidation.
Les algorithmes CNN se composent généralement d'une couche d'entrée et de sortie, ainsi que plusieurs autres couches. La définition manuelle des paramètres pour chacune de ces couches peut être une tâche longue et difficile. Les chercheurs ont donc décidé d'intégrer un algorithme d'optimisation métaheuristique dans leur modèle, qui peut faciliter ce processus en identifiant les valeurs optimales ou quasi optimales à utiliser pour la classification.
« OCDD fait progresser l'état actuel de la détection de la cyberintimidation en éliminant la tâche difficile d'extraction/sélection de fonctionnalités et en la remplaçant par des vecteurs de mots qui capturent la sémantique des mots et CNN qui classe les tweets de manière plus intelligente que les algorithmes de classification traditionnels, " écrivent les chercheurs dans leur article.
Lorsqu'il est testé sur des tâches d'exploration de texte, OCDD a obtenu des résultats très prometteurs. Cependant, il doit encore être mis en œuvre et évalué dans des contextes de détection de cyberintimidation. Les chercheurs envisagent maintenant d'adapter leur approche afin qu'elle puisse également analyser des textes en arabe.
© 2019 Réseau Science X