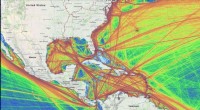
Les chercheurs du MIT constatent que la pratique croissante consistant à compiler des ensembles de données massifs sur les schémas de mouvement des personnes pour la recherche sur la planification et le développement urbains peut, En réalité, mettre en danger les données privées des personnes, même si ces données sont anonymisées. Crédit :Massachusetts Institute of Technology
Une nouvelle étude menée par des chercheurs du MIT révèle que la pratique croissante de la compilation massive, les ensembles de données anonymisés sur les schémas de mouvement des personnes sont une arme à double tranchant :bien qu'ils puissent fournir des informations approfondies sur le comportement humain pour la recherche, cela pourrait également mettre en danger les données privées des personnes.
Entreprises, des chercheurs, et d'autres entités commencent à collecter, boutique, et traiter des données anonymisées contenant des « timbres de localisation » (coordonnées géographiques et horodatages) des utilisateurs. Les données peuvent être extraites des enregistrements de téléphones portables, opérations par carte de crédit, cartes à puce pour les transports en commun, comptes Twitter, et applications mobiles. La fusion de ces ensembles de données pourrait fournir des informations riches sur la façon dont les humains voyagent, par exemple, optimiser les transports et l'urbanisme, entre autres.
Mais les mégadonnées entraînent de gros problèmes de confidentialité :les tampons de localisation sont extrêmement spécifiques aux individus et peuvent être utilisés à des fins malveillantes. Des recherches récentes ont montré que, étant donné que quelques points choisis au hasard dans les ensembles de données de mobilité, quelqu'un pourrait identifier et apprendre des informations sensibles sur des individus. Avec des ensembles de données de mobilité fusionnés, cela devient encore plus facile :un agent pourrait potentiellement faire correspondre les trajectoires des utilisateurs dans les données anonymisées d'un ensemble de données, avec des données déanonymisées dans un autre, pour démasquer les données anonymisées.
Dans un article publié aujourd'hui dans Transactions IEEE sur le Big Data , les chercheurs du MIT montrent comment cela peut se produire dans la toute première analyse de la soi-disant « compatibilité » des utilisateurs dans deux ensembles de données à grande échelle de Singapour, un d'un opérateur de réseau mobile et un d'un système de transport local.
Les chercheurs utilisent un modèle statistique qui suit les marques de localisation des utilisateurs dans les deux ensembles de données et fournit une probabilité que les points de données dans les deux ensembles proviennent de la même personne. Dans les expériences, les chercheurs ont découvert que le modèle pouvait correspondre à environ 17% des individus en une semaine de données, et plus de 55% des individus après un mois de collecte de données. Le travail démontre une efficacité, un moyen évolutif de faire correspondre les trajectoires de mobilité dans les ensembles de données, ce qui peut être une aubaine pour la recherche. Mais, avertissent les chercheurs, de tels processus peuvent augmenter la possibilité de désanonymiser les données réelles des utilisateurs.
« En tant que chercheurs, nous pensons que travailler avec des ensembles de données à grande échelle peut permettre de découvrir des informations sans précédent sur la société humaine et la mobilité, nous permettant de mieux planifier les villes. Néanmoins, il est important de montrer si l'identification est possible, afin que les gens puissent être conscients des risques potentiels liés au partage des données de mobilité, " dit Daniel Kondor, un post-doctorat dans le Future Urban Mobility Group de l'Alliance Singapour-MIT pour la recherche et la technologie.
"En publiant les résultats—et, en particulier, les conséquences de la désanonymisation des données :nous nous sentions un peu comme des hackers « chapeaux blancs » ou « éthiques », " ajoute le co-auteur Carlo Ratti, professeur de pratique au Département d'études urbaines et de planification du MIT et directeur du Senseable City Lab du MIT. "Nous avons estimé qu'il était important d'avertir les gens de ces nouvelles possibilités [de fusion de données] et [d'examiner] comment nous pourrions les réglementer."
Les co-auteurs de l'étude sont Behrooz Hashemian, un post-doctorat au Senseable City Lab, et Yves-Alexandre de Mondjoye du Department of Computing and Data Science Institute de l'Imperial College de Londres.
Éliminer les faux positifs
Pour comprendre le fonctionnement de la correspondance des cachets de localisation et de la désanonymisation potentielle, Considérez ce scénario :« J'étais sur l'île de Sentosa à Singapour il y a deux jours, est venu à l'aéroport de Dubaï hier, et je suis sur la plage de Jumeirah à Dubaï aujourd'hui. Il est très peu probable que la trajectoire d'une autre personne soit exactement la même. En bref, si quelqu'un a mes informations de carte de crédit anonymisées, et peut-être mes données de localisation ouvertes de Twitter, ils pourraient alors désanonymiser mes données de carte de crédit, " dit Ratti.
Des modèles similaires existent pour évaluer la désanonymisation des données. Mais ceux-ci utilisent des approches informatiques intensives pour la ré-identification, ce qui signifie fusionner des données anonymes avec des données publiques pour identifier des individus spécifiques. Ces modèles n'ont fonctionné que sur des ensembles de données limités. Les chercheurs du MIT ont plutôt utilisé une approche statistique plus simple, en mesurant la probabilité de faux positifs, pour prédire efficacement la correspondance entre les scores d'utilisateurs dans des ensembles de données massifs.
Dans leur travail, les chercheurs ont compilé deux ensembles de données anonymisées « à faible densité » (quelques enregistrements par jour) sur l'utilisation du téléphone portable et les transports personnels à Singapour, enregistrées sur une semaine en 2011. Les données mobiles provenaient d'un grand opérateur de réseau mobile et comprenaient des horodatages et des coordonnées géographiques dans plus de 485 millions d'enregistrements provenant de plus de 2 millions d'utilisateurs. Les données sur les transports contenaient plus de 70 millions d'enregistrements avec des horodatages pour les personnes se déplaçant dans la ville.
La probabilité qu'un utilisateur donné possède des enregistrements dans les deux ensembles de données augmentera avec la taille des ensembles de données fusionnés, mais il en sera de même de la probabilité de faux positifs. Le modèle des chercheurs sélectionne un utilisateur dans un ensemble de données et trouve un utilisateur dans l'autre ensemble de données avec un nombre élevé de cachets de localisation correspondants. Tout simplement, à mesure que le nombre de points correspondants augmente, la probabilité d'une correspondance faussement positive diminue. Après avoir fait correspondre un certain nombre de points le long d'une trajectoire, le modèle exclut la possibilité que la correspondance soit un faux positif.
En se concentrant sur les utilisateurs typiques, ils ont estimé un taux de réussite de correspondance de 17% sur une semaine de données compilées, et environ 55 pour cent pendant quatre semaines. Cette estimation grimpe à environ 95% avec des données compilées sur 11 semaines.
Les chercheurs ont également estimé la quantité d'activité nécessaire pour correspondre à la plupart des utilisateurs sur une semaine. En regardant les utilisateurs avec entre 30 et 49 dossiers de transport personnel, et environ 1, 000 enregistrements mobiles, ils ont estimé plus de 90 pour cent de succès avec une semaine de données compilées. En outre, en combinant les deux ensembles de données avec des traces GPS - collectées régulièrement de manière active et passive par des applications pour smartphones - les chercheurs ont estimé qu'ils pourraient correspondre à 95 % des trajectoires individuelles, utilisant moins d'une semaine de données.
Meilleure confidentialité
Avec leur étude, les chercheurs espèrent accroître la sensibilisation du public et promouvoir des réglementations plus strictes pour le partage des données des consommateurs. "Toutes les données avec des tampons de localisation (qui sont la plupart des données collectées aujourd'hui) sont potentiellement très sensibles et nous devrions tous prendre des décisions plus éclairées sur les personnes avec qui nous les partageons, " dit Ratti. " Nous devons continuer à réfléchir aux défis du traitement des données à grande échelle, sur les individus, et la bonne manière de fournir des garanties adéquates pour préserver la vie privée. »
À cette fin, Ratti, Kondor, et d'autres chercheurs ont beaucoup travaillé sur les questions éthiques et morales des mégadonnées. En 2013, le Senseable City Lab du MIT a lancé une initiative intitulée « Engaging Data, " qui implique les dirigeants du gouvernement, groupes de défense des droits à la vie privée, universitaire, et affaires, qui étudient comment les données de mobilité peuvent et doivent être utilisées par les entreprises de collecte de données d'aujourd'hui.
"Le monde d'aujourd'hui est inondé de mégadonnées, ", dit Kondor. "En 2015, l'humanité a produit autant d'informations que dans toutes les années précédentes de la civilisation humaine. Bien que les données signifient une meilleure connaissance de l'environnement urbain, actuellement, une grande partie de cette mine d'informations est détenue par quelques entreprises et institutions publiques qui en savent beaucoup sur nous, alors que nous en savons si peu sur eux. Nous devons veiller à éviter les monopoles et les abus de données."
Cette histoire est republiée avec l'aimable autorisation de MIT News (web.mit.edu/newsoffice/), un site populaire qui couvre l'actualité de la recherche du MIT, innovation et enseignement.