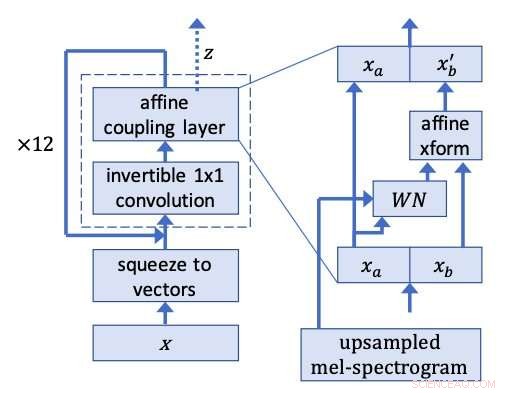
Réseau WaveGlow. Crédit :Prenger, Vallée, et Catanzaro.
Une équipe de chercheurs de NVIDIA a récemment développé WaveGlow, un réseau basé sur les flux qui peut générer une parole de haute qualité à partir de spectrogrammes mel, qui sont des représentations acoustiques temps-fréquence du son. Leur méthode, décrit dans un article prépublié sur arXiv, utilise un seul réseau formé avec une seule fonction de coût, rendre la procédure de formation plus facile et plus stable.
"La plupart des réseaux de neurones pour synthétiser la parole étaient trop lents pour nous, " Ryan Prenger, l'un des chercheurs qui a mené l'étude, a déclaré TechXplore. « Ils étaient limités en vitesse car ils étaient conçus pour ne générer qu'un échantillon à la fois. Les exceptions étaient les approches de Google et de Baidu qui généraient de l'audio très rapidement en parallèle. Cependant, ces approches utilisaient des réseaux d'enseignants et des réseaux d'étudiants et étaient trop complexes à reproduire. »
Les chercheurs se sont inspirés de Glow, un réseau basé sur les flux par OpenAI pouvant générer des images de haute qualité en parallèle, conservant une structure assez simple. En utilisant une convolution 1x1 inversible, Glow a obtenu des résultats remarquables, produire des images très réalistes. Les chercheurs ont décidé d'appliquer la même idée derrière cette méthode à la synthèse vocale.
"Pensez au bruit blanc qui vient d'une radio qui n'est réglée sur aucune station, " Prenger a expliqué. Ce bruit blanc est très facile à générer. L'idée de base de la synthèse de la parole avec WaveGlow est de former un réseau de neurones pour transformer ce bruit blanc en parole. Si vous utilisez un ancien réseau de neurones, la formation sera problématique. Mais si vous utilisez spécifiquement un réseau qui peut être exécuté en amont comme en aval, les maths deviennent faciles et certains des problèmes de formation disparaissent."
Les chercheurs ont exécuté des extraits de discours à partir de l'ensemble de données d'entraînement à l'envers, entraîner WaveGlow pour produire ce qui ressemble beaucoup à du bruit blanc. Leur modèle applique la même idée derrière Glow à une architecture de type WaveNet, d'où le nom WaveGlow.
Dans une implémentation PyTorch, WaveGlow a produit des échantillons audio à une fréquence de plus de 500 kHz, sur un GPU NVIDIA V100. Les tests de score d'opinion moyen (MOS) sur Amazon Mechanical Turk suggèrent que l'approche offre une qualité audio aussi bonne que la meilleure méthode WaveNet accessible au public.
« Dans le monde de la synthèse vocale, il existe un besoin de modèles qui génèrent de la parole plus d'un ordre de grandeur plus rapidement en temps réel, " a déclaré Prenger. " Nous espérons que WaveGlow pourra répondre à ce besoin tout en étant plus facile à mettre en œuvre et à entretenir que les autres modèles existants. Dans le monde de l'apprentissage profond, nous pensons que ce type d'approche utilisant un réseau de neurones inversible et la fonction de perte simple qui en résulte est relativement peu étudié. WaveGlow fournit un autre exemple de la façon dont cette approche peut donner des résultats génératifs de haute qualité malgré sa relative simplicité. »
Le code de WaveGlow est facilement disponible en ligne et peut être consulté par d'autres personnes souhaitant l'essayer ou l'expérimenter. Pendant ce temps, les chercheurs travaillent à l'amélioration de la qualité des clips audio synthétisés en affinant leur modèle et en effectuant d'autres évaluations.
"Nous n'avons pas fait beaucoup d'analyses pour voir à quel point un réseau nous pouvons nous en tirer, " a déclaré Prenger. " La plupart de nos décisions d'architecture étaient basées sur des parties très précoces de la formation. Cependant, des réseaux plus petits avec un temps de formation plus long peuvent générer un son tout aussi bon. Il y a beaucoup de directions intéressantes que cette recherche pourrait aller à l'avenir."
© 2018 Réseau Science X