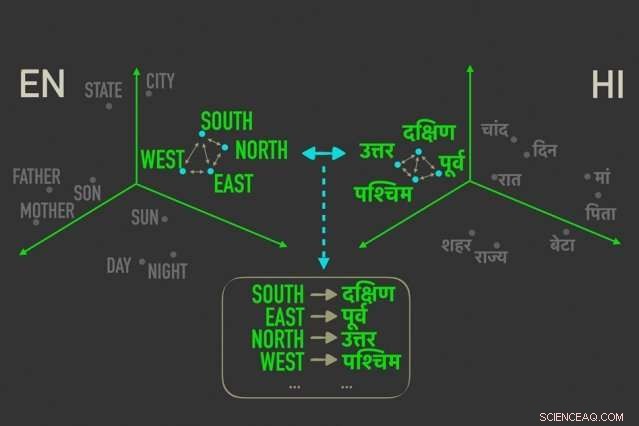
Le nouveau modèle mesure les distances entre les mots ayant des significations similaires dans « mot embeddings, ", puis aligne les mots dans les deux plongements qui sont le plus étroitement corrélés par les distances relatives, ce qui signifie qu'ils sont plus susceptibles d'être des traductions directes les uns des autres. Crédit :Massachusetts Institute of Technology
Les chercheurs du MIT ont mis au point un nouveau modèle de traduction linguistique « non supervisée », ce qui signifie qu'il fonctionne sans avoir besoin d'annotations et de conseils humains - qui pourrait conduire à une accélération plus rapide, des traductions informatiques plus efficaces de beaucoup plus de langues.
Systèmes de traduction de Google, Facebook, et Amazon ont besoin de modèles de formation pour rechercher des modèles dans des millions de documents, tels que des documents juridiques et politiques, ou des articles de presse - qui ont été traduits dans diverses langues par des humains. Étant donné de nouveaux mots dans une langue, ils peuvent alors trouver les mots et expressions correspondants dans l'autre langue.
Mais ces données translationnelles sont chronophages et difficiles à rassembler, et peut tout simplement ne pas exister pour la plupart des 7, 000 langues parlées dans le monde. Récemment, les chercheurs ont développé des modèles « unilingues » qui font des traductions entre des textes en deux langues, mais sans information de traduction directe entre les deux.
Dans un article présenté cette semaine à la Conférence sur les méthodes empiriques dans le traitement du langage naturel, Des chercheurs du Laboratoire d'informatique et d'intelligence artificielle (CSAIL) du MIT décrivent un modèle qui fonctionne plus rapidement et plus efficacement que ces modèles monolingues.
Le modèle exploite une métrique dans les statistiques, distance de Gromov-Wasserstein, qui mesure essentiellement les distances entre les points dans un espace de calcul et les associe à des points de même distance dans un autre espace. Ils appliquent cette technique aux « inclusions de mots » de deux langues, qui sont des mots représentés comme des vecteurs - en gros, tableaux de nombres - avec des mots de significations similaires regroupés plus près les uns des autres. Ce faisant, le modèle aligne rapidement les mots, ou vecteurs, dans les deux plongements qui sont le plus étroitement corrélés par les distances relatives, ce qui signifie qu'ils sont susceptibles d'être des traductions directes.
Dans les expériences, le modèle des chercheurs a fonctionné aussi précisément que les modèles monolingues de pointe - et parfois plus précisément - mais beaucoup plus rapidement et en utilisant seulement une fraction de la puissance de calcul.
"Le modèle voit les mots dans les deux langues comme des ensembles de vecteurs, et mappe [ces vecteurs] d'un ensemble à l'autre en préservant essentiellement les relations, " déclare Tommi Jaakkola, co-auteur de l'article, chercheur au CSAIL et professeur Thomas Siebel au Département de génie électrique et informatique et à l'Institut des données, Systèmes, et Société. « L'approche pourrait aider à traduire des langues ou des dialectes à faibles ressources, tant qu'ils viennent avec suffisamment de contenu unilingue."
Le modèle représente un pas vers l'un des objectifs majeurs de la traduction automatique, qui est un alignement de mots entièrement non supervisé, dit le premier auteur David Alvarez-Melis, un doctorat CSAIL étudiant :"Si vous n'avez pas de données qui correspondent à deux langues… vous pouvez mapper deux langues et, à l'aide de ces mesures de distance, alignez-les."
Les relations comptent le plus
L'alignement des incorporations de mots pour la traduction automatique non supervisée n'est pas un nouveau concept. Des travaux récents entraînent les réseaux de neurones à faire correspondre les vecteurs directement dans les plongements de mots, ou des matrices, de deux langues ensemble. Mais ces méthodes nécessitent beaucoup d'ajustements pendant l'entraînement pour obtenir les alignements exacts, ce qui est inefficace et prend du temps.
Mesurer et faire correspondre des vecteurs basés sur des distances relationnelles, d'autre part, est une méthode beaucoup plus efficace qui ne nécessite pas beaucoup de réglages. Peu importe où se trouvent les vecteurs de mots dans une matrice donnée, la relation entre les mots, signifiant leurs distances, restera le même. Par exemple, le vecteur pour "père" peut tomber dans des zones complètement différentes dans deux matrices. Mais les vecteurs pour "père" et "mère" seront très probablement toujours proches l'un de l'autre.
"Ces distances sont invariantes, " dit Alvarez-Melis. " En regardant à distance, et non les positions absolues des vecteurs, alors vous pouvez ignorer l'alignement et passer directement à la correspondance des correspondances entre les vecteurs."
C'est là que Gromov-Wasserstein est utile. La technique a été utilisée en informatique pour, dire, aider à aligner les pixels de l'image dans la conception graphique. Mais la métrique semblait "sur mesure" pour l'alignement des mots, Alvarez-Melis dit :« S'il y a des points, ou des mots, qui sont proches les uns des autres dans un même espace, Gromov-Wasserstein va automatiquement essayer de trouver le groupe de points correspondant dans l'autre espace."
Pour la formation et les tests, les chercheurs ont utilisé un ensemble de données d'inclusions de mots accessibles au public, appelé FASTTEXT, avec 110 paires de langues. Dans ces encastrements, et d'autres, les mots qui apparaissent de plus en plus fréquemment dans des contextes similaires ont des vecteurs étroitement correspondants. "Mère" et "père" seront généralement proches l'un de l'autre mais tous deux plus éloignés, dire, "loger."
Fournir une « traduction douce »
Le modèle note des vecteurs étroitement liés mais différents des autres, et attribue une probabilité que des vecteurs de même distance dans l'autre plongement correspondent. C'est un peu comme une "traduction douce, " Alvarez-Melis dit, "parce qu'au lieu de simplement renvoyer une traduction d'un seul mot, il vous dit 'ce vecteur, ou mot, a une forte correspondance avec ce mot, ou des mots, dans l'autre langue.'"
Un exemple serait dans les mois de l'année, qui apparaissent étroitement ensemble dans de nombreuses langues. Le modèle verra un cluster de 12 vecteurs regroupés dans un encastrement et un cluster remarquablement similaire dans l'autre encastrement. "Le modèle ne sait pas que ce sont des mois, " Alvarez-Melis dit. " Il sait juste qu'il y a un cluster de 12 points qui s'aligne avec un cluster de 12 points dans l'autre langue, mais ils sont différents du reste des mots, donc ils vont probablement bien ensemble. En trouvant ces correspondances pour chaque mot, il aligne alors tout l'espace simultanément."
Les chercheurs espèrent que le travail servira de « contrôle de faisabilité, " Jaakkola dit, appliquer la méthode Gromov-Wasserstein aux systèmes de traduction automatique pour fonctionner plus rapidement, plus efficacement, et accédez à de nombreuses autres langues.
En outre, un avantage possible du modèle est qu'il produit automatiquement une valeur qui peut être interprétée comme quantifiante, à l'échelle numérique, la similitude entre les langues. Cela peut être utile pour les études de linguistique, disent les chercheurs. Le modèle calcule à quelle distance tous les vecteurs sont les uns des autres dans deux plongements, qui dépend de la structure de la phrase et d'autres facteurs. Si les vecteurs sont tous très proches, ils marqueront plus près de 0, et plus ils sont éloignés, plus le score est élevé. Langues romanes similaires telles que le français et l'italien, par exemple, score proche de 1, tandis que le chinois classique obtient entre 6 et 9 avec les autres langues principales.
"Cela vous donne une belle, nombre simple indiquant à quel point les langues sont similaires… et peut être utilisé pour tirer un aperçu des relations entre les langues, " dit Alvarez-Melis.
Cette histoire est republiée avec l'aimable autorisation de MIT News (web.mit.edu/newsoffice/), un site populaire qui couvre l'actualité de la recherche du MIT, innovation et enseignement.