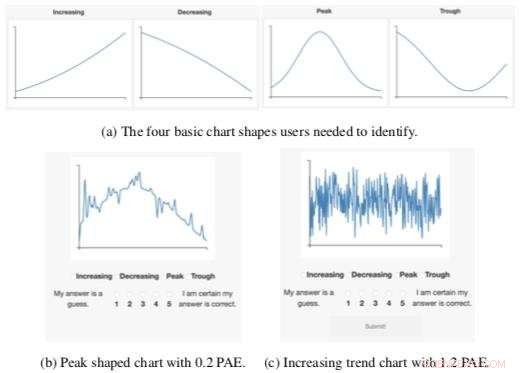
Figure montrant un exemple d'une des études d'utilisateurs, dans lequel les utilisateurs devaient classer les graphiques en fonction de leur forme. Le graphique de droite montre un exemple de graphique complexe qui recevrait un score de complexité élevé (c). Intuitivement, il est plus difficile à lire que le tableau de gauche. Pour améliorer la lisibilité, un programme de visualisation pourrait améliorer des aspects importants des données pour en faciliter la lecture. Crédit :Gabriel Ryan, Wu Lab/Columbia Engineering
Les médecins lisant les EEG aux urgences, les premiers intervenants regardant plusieurs écrans montrant des flux de données en direct provenant de capteurs dans une zone sinistrée, les courtiers qui achètent et vendent des instruments financiers doivent tous prendre des décisions éclairées très rapidement. La complexité de la visualisation peut compliquer la prise de décision lorsque l'on examine des données sur un graphique. Lorsque le timing est critique, il est essentiel qu'un tableau soit facile à lire et à interpréter.
Pour aider les décideurs dans des scénarios comme ceux-ci, Les informaticiens de Columbia Engineering et de l'Université Tufts ont développé une nouvelle méthode - "Pixel Approximate Entropy" - qui mesure la complexité d'une visualisation de données et peut être utilisée pour développer des visualisations plus faciles à lire. Eugène Wu, professeur assistant en informatique, et Gabriel Ryan, qui était alors étudiant à la maîtrise et maintenant au doctorat. étudiant à Columbia, présenteront leur article à la conférence IEEE VIS 2018 jeudi, 25 octobre à Berlin, Allemagne.
"Il s'agit d'une toute nouvelle approche pour travailler avec des graphiques linéaires avec de nombreuses applications potentielles différentes, " dit Ryan, premier auteur sur le papier. "Notre méthode donne aux systèmes de visualisation un moyen de mesurer la difficulté de lecture des graphiques en courbes, Nous pouvons donc maintenant concevoir ces systèmes pour simplifier ou résumer automatiquement des graphiques qui seraient difficiles à lire par eux-mêmes."
Outre l'inspection visuelle d'une visualisation, il existe peu de moyens de quantifier automatiquement la complexité d'une visualisation de données. Pour résoudre ce problème, Le groupe de Wu a créé Pixel Approximate Entropy pour fournir un « score de complexité visuelle » qui peut identifier automatiquement les graphiques difficiles. Ils ont modifié une mesure d'entropie de faible dimension pour opérer sur des graphiques linéaires, puis a mené une série d'études d'utilisateurs qui ont démontré que la mesure pouvait prédire dans quelle mesure les utilisateurs percevaient les graphiques.