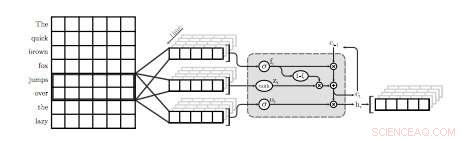
Une illustration de la première couche QRNN pour la modélisation du langage. Dans cette visualisation, une couche QRNN avec une taille de fenêtre de deux convolutions et des pools utilisant les plongements de l'entrée. Notez l'absence de poids récurrents. Crédit :Tang &Lin.
Une équipe de chercheurs de l'Université de Waterloo au Canada a récemment mené une étude explorant les compromis précision-efficacité des modèles de langage neuronal (NLM) spécifiquement appliqués aux appareils mobiles. Dans leur papier, qui a été prépublié sur arXiv, les chercheurs ont également proposé une technique simple pour récupérer une certaine perplexité, une mesure de la performance d'un modèle de langage, utilisant une quantité négligeable de mémoire.
Les NLM sont des modèles de langage basés sur des réseaux de neurones à travers lesquels les algorithmes peuvent apprendre la distribution typique des séquences de mots et faire des prédictions sur le mot suivant dans une phrase. Ces modèles ont un certain nombre d'applications utiles, par exemple, permettant des claviers logiciels plus intelligents pour les téléphones mobiles ou autres appareils.
"Les modèles de langage neuronal (NLM) existent dans un espace de compromis précision-efficacité où une meilleure perplexité se fait généralement au prix d'une plus grande complexité de calcul, " les chercheurs ont écrit dans leur article. " Dans une application de clavier logiciel sur les appareils mobiles, cela se traduit par une consommation d'énergie plus élevée et une durée de vie de la batterie plus courte."
Lorsqu'il est appliqué aux claviers logiciels, Les NLM peuvent conduire à une prédiction plus précise du mot suivant, permettant aux utilisateurs de saisir le mot suivant dans une phrase donnée en un seul clic. Deux applications existantes qui utilisent des réseaux de neurones pour fournir cette fonctionnalité sont SwiftKey1 et Swype2. Cependant, ces applications nécessitent souvent beaucoup de puissance pour fonctionner, vider rapidement les batteries des appareils mobiles.
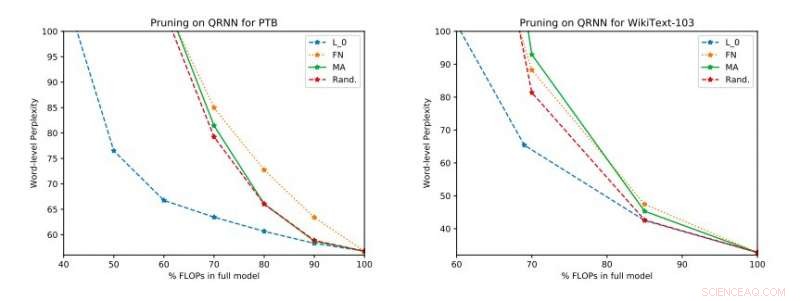
Résultats expérimentaux complets sur Penn Treebank et WikiText-103. Nous illustrons l'espace de compromis perplexité-efficacité sur l'ensemble de test obtenu avant d'appliquer la mise à jour à rang unique. Crédit :Tang &Lin.
« Basé sur des mesures standard telles que la perplexité, les techniques neuronales représentent une avancée dans la modélisation du langage de pointe, " les chercheurs ont expliqué dans leur article. " De meilleurs modèles, cependant, ont un coût en termes de complexité de calcul, ce qui se traduit par une consommation d'énergie plus élevée. Dans le contexte des appareils mobiles, l'efficacité énergétique est, bien sûr, un objectif d'optimisation important."
Selon les chercheurs, Les NLM ont jusqu'à présent été principalement évalués dans le contexte de la reconnaissance d'images et du repérage de mots clés, tandis que leur compromis précision-efficacité dans les applications de traitement du langage naturel (NLP) n'a pas encore été étudié en profondeur. Leur étude porte sur ce domaine de recherche inexploré, effectuer une évaluation des NLM et de leurs compromis précision-efficacité sur un Raspberry Pi.
"Nos évaluations empiriques tiennent compte à la fois de la perplexité et de la consommation d'énergie sur un Raspberry Pi, où nous démontrons quelles méthodes fournissent le meilleur point de fonctionnement perplexité-consommation d'énergie, " les chercheurs ont dit. " À un point de fonctionnement, l'une des techniques est capable de fournir des économies d'énergie de 40 pour cent par rapport aux [méthodes] de pointe avec seulement une augmentation relative de 17 pour cent de la perplexité."
Dans leur étude, les chercheurs ont également évalué un certain nombre de techniques d'élagage en temps d'inférence sur les réseaux de neurones quasi-récurrents (QRNN). Étendre la convivialité des méthodes d'élagage existantes au moment de la formation aux QRNN lors de l'exécution, ils ont atteint plusieurs points de fonctionnement dans l'espace de compromis précision-efficacité. Pour améliorer les performances en utilisant une petite quantité de mémoire, ils ont suggéré de former et de stocker les mises à jour de poids à un seul rang aux points de fonctionnement souhaités.
© 2018 Tech Xplore