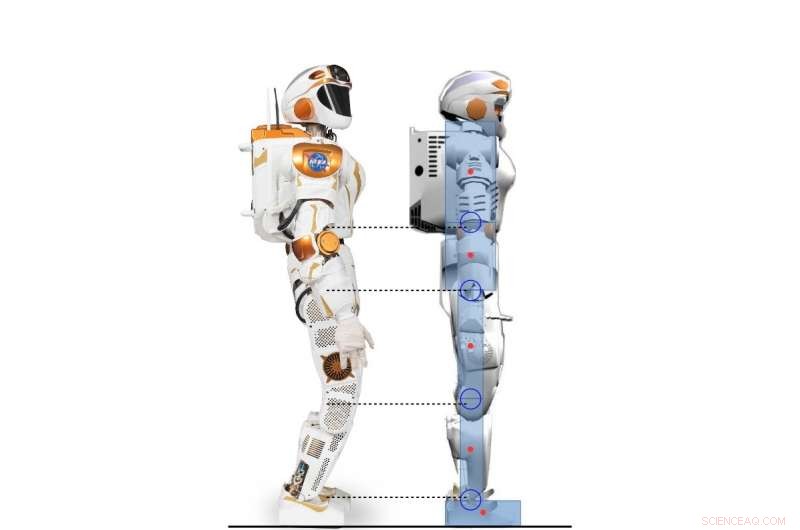
Vue latérale du robot Valkyrie et du personnage humanoïde 2D modélisé d'après le robot Valkyrie. Crédit :Yang, Komura &Li
Des chercheurs de l'Université d'Édimbourg ont développé un cadre hiérarchique basé sur l'apprentissage par renforcement profond (RL) qui peut acquérir une variété de stratégies pour le contrôle de l'équilibre humanoïde. leur cadre, décrit dans un article prépublié sur arXiv et présenté à la Conférence internationale 2017 sur la robotique humanoïde, pourrait effectuer des comportements d'équilibrage beaucoup plus humains que les contrôleurs conventionnels.
En position debout ou en marchant, les êtres humains utilisent de manière innée et efficace un certain nombre de techniques de contrôle sous-actionné qui les aident à garder leur équilibre. Ceux-ci incluent l'inclinaison des orteils et le roulement du talon, qui créent une meilleure garde au sol. La reproduction de comportements similaires dans des robots humanoïdes pourrait grandement améliorer leurs capacités motrices et de mouvement.
"Notre recherche se concentre sur l'utilisation de la RL profonde pour résoudre la locomotion dynamique des robots humanoïdes, " Dr Zhibin Li, maître de conférences en robotique et contrôle à l'Université d'Edimbourg, qui a réalisé l'étude, a déclaré TechXplore. "Autrefois, la locomotion a été principalement effectuée à l'aide d'approches analytiques conventionnelles—basées sur des modèles, qui sont limités parce qu'ils nécessitent des efforts et des connaissances humaines, et exigent une puissance de calcul élevée pour fonctionner en ligne."
Nécessitant moins d'effort humain et de réglage manuel, Les techniques d'apprentissage automatique pourraient conduire au développement de contrôleurs plus efficaces et spécifiques que les approches d'ingénierie traditionnelles. Un autre avantage de l'utilisation de RL est que le calcul de ces outils peut également être externalisé hors ligne, résultant en des performances en ligne plus rapides pour les systèmes de contrôle de grande dimension, comme les robots humanoïdes.

Un robot Valkyrie simulé dans une pose d'inclinaison des orteils/talons. Crédit :Yang, Komura &Li
"Compte tenu des algorithmes RL profonds de plus en plus puissants, un nombre croissant d'études de recherche ont commencé à utiliser le RL profond pour résoudre des tâches de contrôle, comme les progrès récents dans les algorithmes RL profonds conçus pour le domaine d'action continue ont mis en avant la possibilité d'appliquer des tâches de contrôle continu d'apprentissage par renforcement qui impliquent une dynamique compliquée, " a expliqué le Dr Li. " L'objectif principal de notre recherche était d'explorer les possibilités d'utiliser l'apprentissage par renforcement en profondeur pour acquérir des politiques de contrôle polyvalentes comparables ou meilleures que les approches analytiques tout en utilisant moins d'effort humain. "
Le cadre développé par le Dr Li, en collaboration avec le Dr Taku Komura et Ph.D. étudiant Chuanyu Yang, utilise Deep RL pour atteindre des politiques de contrôle de haut niveau. Recevoir en permanence des informations sur l'état du robot, ces stratégies permettent des angles d'articulation souhaités à une fréquence inférieure.
« Au bas niveau, les contrôleurs proportionnels et dérivés (PD) sont utilisés à une fréquence de contrôle beaucoup plus élevée pour garantir les mouvements communs stables, " L'étudiant au doctorat Chuanyu a déclaré. " Les entrées pour le contrôleur PD de bas niveau sont les angles de joint souhaités produits par le réseau de neurones de haut niveau, et les sorties sont les couples souhaités pour les moteurs communs."
Les chercheurs ont testé les performances de leur algorithme et ont obtenu des résultats très prometteurs. Ils ont découvert que le transfert des connaissances humaines des méthodes d'ingénierie de contrôle à la conception de la récompense pour les algorithmes RL permettait des stratégies de contrôle de l'équilibre qui ressemblaient à celles utilisées par les humains. De plus, à mesure que les algorithmes RL s'améliorent grâce à un processus d'essais et d'erreurs, s'adapter automatiquement aux nouvelles situations, leur cadre nécessite peu de réglages manuels ou d'autres interventions de la part d'ingénieurs humains.
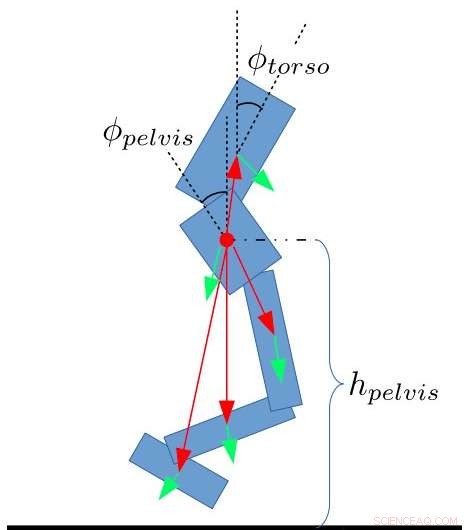
Caractéristiques de l'état pour le bipède. Yang, Komura &Li
"Notre étude montre que l'apprentissage par renforcement approfondi peut être un outil puissant pour produire des résultats d'équilibrage comparables à ceux d'un contrôleur conçu par l'homme avec moins d'effort de réglage manuel et un temps plus court, " a déclaré le Dr Li. " L'algorithme d'apprentissage par renforcement en profondeur que nous avons développé est même capable d'apprendre des comportements humains tels que l'inclinaison autour des orteils ou des talons, que la plupart des méthodes d'ingénierie sont incapables de réaliser.
Le Dr Li et ses collègues travaillent maintenant sur une extension de leur étude qui applique la RL à un robot Valkyrie au corps entier dans une simulation 3D. Dans ce nouvel effort de recherche, ils ont pu généraliser des stratégies d'équilibre ressemblant à des humains à la marche et à d'autres tâches de locomotion.
"Finalement, nous aimerions appliquer ce cadre hiérarchique de combinaison d'apprentissage automatique et de contrôle de robot à de vrais robots humanoïdes, ainsi qu'à d'autres plateformes robotiques, " dit le Dr Li.
© 2018 Tech Xplore