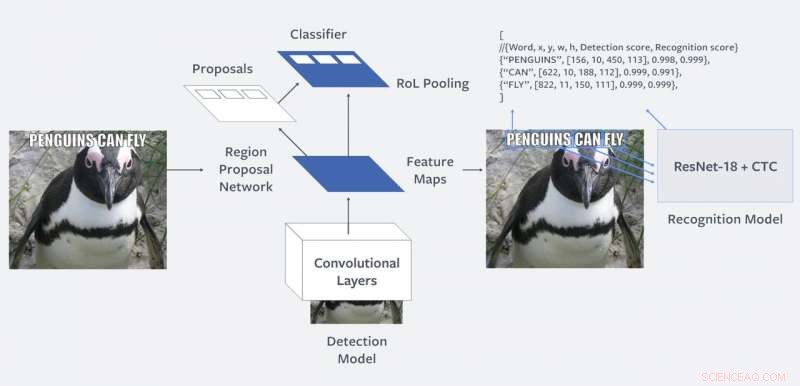
Architecture de modèle en deux étapes :la première étape effectue la détection de mots sur la base de Faster R-CNN. La deuxième étape effectue la reconnaissance de mots à l'aide d'un modèle entièrement convolutif avec perte de CTC. Les deux modèles sont entraînés indépendamment. Crédit :Facebook
Quand un mème est au-delà de l'idiot et franchit la ligne pour devenir carrément offensant, est-ce que quelqu'un s'occupe du magasin?
Dites bonjour à Rosetta, qui est un système d'apprentissage automatique qui a été conçu pour dire whoa. Facebook a construit et déployé ce système d'apprentissage automatique. "Il extrait le texte de plus d'un milliard d'images et de cadres vidéo publics Facebook et Instagram (dans une grande variété de langues), quotidiennement et en temps réel, et les insère dans un modèle de reconnaissance de texte qui a été entraîné sur des classificateurs pour comprendre ensemble le contexte du texte et de l'image."
La reconnaissance du discours de haine via la technologie automatique n'est jamais facile et devient de plus en plus difficile avec le temps. Rosetta peut alléger la charge d'essayer de s'assurer qu'il ne glisse pas sans être détecté. Rosetta est un système qui peut déterminer le contexte du texte et de l'image ensemble .
Qu'est-ce que ça veut dire? Comprendre les mots, comprendre les images... mais maintenant la compréhension du texte dans images?
Publication sur le site "Code Facebook", Viswanath Sivakumar, Albert Gordo, et Manohar Paluri, décrire les défis qui appelaient une solution comme Rosetta. Après tout, les créatifs vont au-delà des articles traditionnels centrés sur le texte.
Ils ont déclaré qu'"un nombre important de photos partagées sur Facebook et Instagram contiennent du texte sous diverses formes. Il peut être superposé sur une image dans un mème, ou incrusté dans une photo d'une devanture de magasin, Panneau de signalisation, ou carte du restaurant. Compte tenu du volume considérable de photos partagées chaque jour sur Facebook et Instagram, le nombre de langues supportées sur notre plateforme mondiale, et les variations du texte, le problème de la compréhension du texte dans les images est assez différent de ceux résolus par les systèmes traditionnels de reconnaissance optique de caractères (OCR), qui reconnaissent les personnages mais ne comprennent pas le contexte de l'image associée."
D'ACCORD, IA, pouvons-nous parler de mèmes? Nos conversations ont de multiples condiments. Avec Facebook, des images avec du texte sont publiées tous les jours, y compris des mèmes. Rosetta est conçu (1) pour donner aux lecteurs d'écran un moyen de lire ce qui est écrit dessus (2) pour s'assurer qu'ils ne contiennent pas de discours haineux ou ne violent pas la politique de contenu du site Web,
Entreprise rapide fait remarquer que le système a surtout été appliqué à l'imagerie fixe, mais Rosetta commence à peine à se mouiller les pieds; cela va aller plus loin. "Facebook prévoit d'utiliser de plus en plus Rosetta pour extraire le sens du texte de la vidéo dans toutes ses applications, " même si la technologie n'est pas encore prête à s'attaquer à toutes les vidéos.
De façon intéressante, Entreprise rapide Daniel Terdiman a vu cela comme une arme contre les mèmes car il y avait un besoin d'outils efficaces sur lesquels les services peuvent s'appuyer, pour déraciner les mèmes qui peuvent être nocifs, dans un contenu qui pourrait autrement passer inaperçu. "Nous aimons tous les mèmes, et la plupart d'entre nous ont probablement aidé à les diffuser - en transmettant cette jolie photo avec le texte ironique à nos nombreux amis sur Facebook, Twitter, et ailleurs. Mais parfois les mèmes peuvent être nocifs, répandre des mensonges sur des personnes ou des organisations.
Clair et simple, le système Rosetta peut faire un meilleur travail qu'auparavant "pour comprendre le texte nuisible ou faux utilisé dans les mèmes qui se propagent sur Facebook et Instagram".
Mariella Lune dans Engagé discuté de son fonctionnement, et "il commence par détecter des régions rectangulaires dans des images qui contiennent potentiellement du texte. Il utilise ensuite un réseau de neurones convolutifs pour reconnaître et transcrire ce qui est écrit dans cette région, même des mots non anglais ou des alphabets non latins, " dit Moon. Pour entraîner le système, elle a ajouté, Facebook a utilisé "un mélange d'images publiques annotées par des humains et des machines".
Quel est le statut de Rosetta en ce moment ? Jacob Kastrenakes, Le bord :"On dit que Rosetta est en direct maintenant, extraire du texte à partir d'un milliard d'images et d'images vidéo par jour sur Facebook et Instagram."
Et après? Rosetta n'est pas parfaite; Facebook veut se rapprocher de la perfection, cependant et a une liste de choses à faire. Moon a déclaré que la société prévoyait de continuer à augmenter le nombre de langues qu'elle peut comprendre et "d'améliorer l'extraction de texte à partir d'images vidéo".
Quelqu'un a-t-il le sentiment qu'il pourrait y en avoir qui enverront de mauvais regards à Rosetta à mesure qu'elle deviendra plus connue? Peut-être. Cohen Coberly dans TechSpot a écrit, « Rosetta sera presque certainement un outil controversé pour certains membres du public amoureux des mèmes, mais j'espère que la technologie s'avérera suffisamment intelligente pour faire la distinction entre un contenu idiot mais inoffensif et des images vraiment offensantes."
Kastrenakes, Le bord :"Compte tenu des problèmes de modération bien connus de l'entreprise, un système qui fonctionne bien et qui peut automatiquement signaler les images potentiellement problématiques pourrait être d'une réelle aide."
© 2018 Tech Xplore