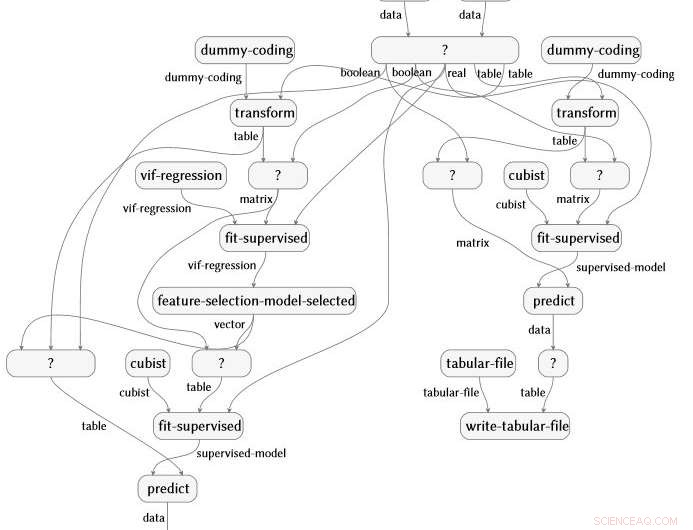
Représentation graphique de flux sémantique produite automatiquement à partir d'une analyse des données sur la polyarthrite rhumatoïde. Crédit :IBM
Nous avons vu des progrès récents significatifs dans l'analyse des motifs et l'intelligence artificielle appliquée aux images, signaux audio et vidéo, et texte en langage naturel, mais pas autant appliqué à un autre artefact produit par des personnes :le code source d'un programme informatique. Dans un article qui sera présenté à l'atelier FEED au KDD 2018, nous présentons un système qui progresse vers l'analyse sémantique du code. En faisant cela, nous fournissons la base aux machines pour vraiment raisonner sur le code du programme et en tirer des leçons.
L'oeuvre, également récemment démontré à IJCAI 2018, est conçu et dirigé par Evan Patterson, membre d'IBM Science for Social Good, et se concentre spécifiquement sur les logiciels de science des données. Les programmes de science des données sont un type particulier de code informatique, souvent assez court, mais plein de contenu sémantiquement riche qui spécifie une séquence de transformation de données, une analyse, la modélisation, et les opérations d'interprétation. Notre technique exécute une analyse de données (imaginez un script R ou Python) et capture toutes les fonctions appelées dans l'analyse. Il connecte ensuite ces fonctions à une ontologie de science des données que nous avons créée, effectue plusieurs étapes de simplification, et produit une représentation graphique de flux sémantique du programme. Par exemple, le graphique ci-dessous est produit automatiquement à partir d'une analyse des données sur la polyarthrite rhumatoïde.
La technique est applicable à travers les choix de langage de programmation et de package. Les trois extraits de code ci-dessous sont écrits en R, Python avec les packages NumPy et SciPy, et Python avec les packages Pandas et Scikit-learn. Tous produisent exactement le même graphe de flux sémantique.
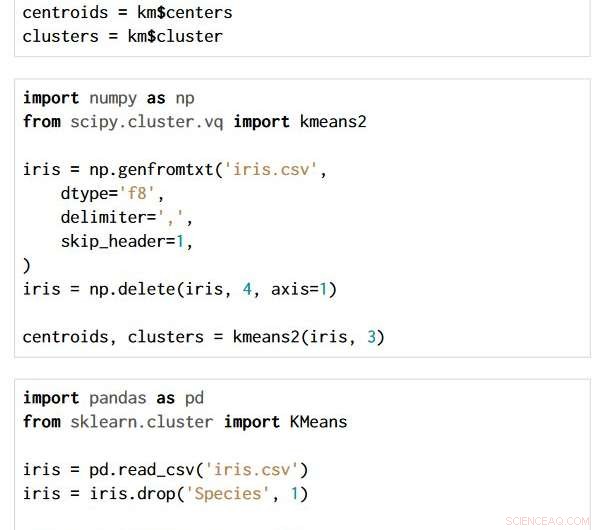
Crédit :IBM
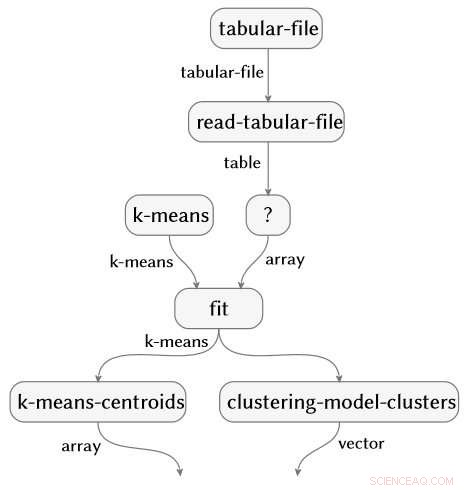
Crédit :IBM
Nous pouvons considérer le graphe de flux sémantique que nous extrayons comme un seul point de données, tout comme une image ou un paragraphe de texte, sur lequel effectuer d'autres tâches de niveau supérieur. Avec la représentation que nous avons développée, nous pouvons activer plusieurs fonctionnalités utiles pour la pratique des data scientists, y compris la recherche intelligente et l'auto-complétion des analyses, recommandation d'analyses similaires ou complémentaires, visualisation de l'espace de toutes les analyses menées sur un problème ou un jeu de données particulier, traduction ou transfert de style, et même la génération automatique de nouvelles analyses de données (c'est-à-dire la créativité informatique), le tout reposant sur la compréhension véritablement sémantique de ce que fait le code.
L'ontologie Data Science est écrite dans un nouveau langage d'ontologie que nous avons développé appelé Monoidal Ontology and Computing Language (Monocl). Cet axe de travail a été initié en 2016 en partenariat avec le projet Accelerated Cure for Multiple Sclerosis.
Cette histoire est republiée avec l'aimable autorisation d'IBM Research. Lisez l'histoire originale ici.