Les ordinateurs sont excellents pour catégoriser les images en fonction des objets trouvés avec eux, mais ils sont étonnamment mauvais pour déterminer quand deux objets d'une même image sont identiques ou différents l'un de l'autre. De nouvelles recherches aident à montrer pourquoi cette tâche est si difficile pour les algorithmes modernes de vision par ordinateur. Crédit :Serre lab / Université Brown
Les algorithmes de vision par ordinateur ont parcouru un long chemin au cours de la dernière décennie. Ils se sont avérés aussi bons ou meilleurs que les personnes à des tâches telles que la catégorisation des races de chiens ou de chats, et ils ont la capacité remarquable d'identifier des visages spécifiques parmi une mer de millions.
Mais des recherches menées par des scientifiques de l'Université Brown montrent que les ordinateurs échouent lamentablement dans une classe de tâches avec lesquelles même les jeunes enfants n'ont aucun problème :déterminer si deux objets d'une image sont identiques ou différents. Dans un article présenté la semaine dernière à la réunion annuelle de la Cognitive Science Society, l'équipe Brown explique pourquoi les ordinateurs sont si mauvais pour ce type de tâches et suggère des pistes vers des systèmes de vision par ordinateur plus intelligents.
« Il y a beaucoup d'enthousiasme à propos de ce que la vision par ordinateur a pu réaliser, et je partage beaucoup de ça, " dit Thomas Serre, professeur agrégé de cognition, sciences linguistiques et psychologiques à Brown et auteur principal de l'article. "Mais nous pensons qu'en travaillant pour comprendre les limites des systèmes de vision par ordinateur actuels comme nous l'avons fait ici, on peut vraiment aller vers le nouveau, des systèmes beaucoup plus avancés plutôt que de simplement peaufiner les systèmes que nous avons déjà."
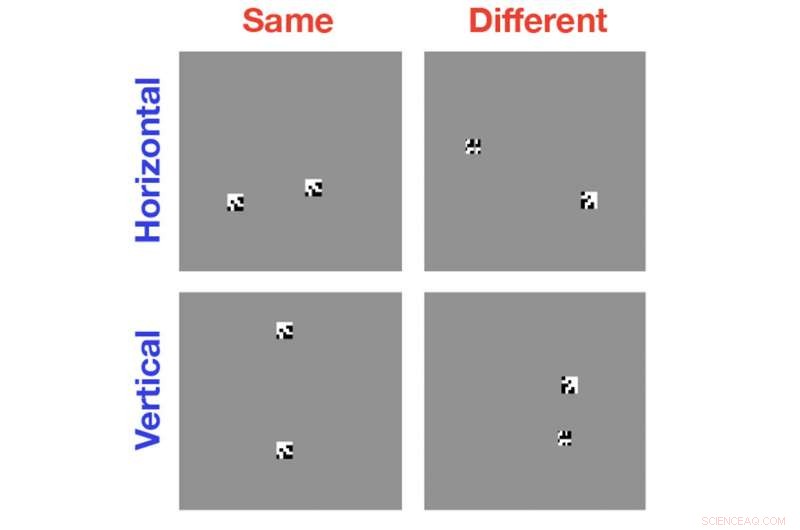
Pour l'étude, Serre et ses collègues ont utilisé des algorithmes de vision par ordinateur de pointe pour analyser de simples images en noir et blanc contenant au moins deux formes générées aléatoirement. Dans certains cas, les objets étaient identiques; parfois ils étaient les mêmes mais avec un objet tourné par rapport à l'autre; parfois les objets étaient complètement différents. L'ordinateur a été invité à identifier la relation identique ou différente.
L'étude a montré que, même après des centaines de milliers d'exemples de formation, les algorithmes n'étaient pas meilleurs que le hasard pour reconnaître la relation appropriée. La question, alors, était la raison pour laquelle ces systèmes sont si mauvais à cette tâche.
Serre et ses collègues soupçonnaient que cela avait quelque chose à voir avec l'incapacité de ces algorithmes de vision par ordinateur à individuer des objets. Lorsque les ordinateurs regardent une image, ils ne peuvent pas réellement dire où s'arrête un objet dans l'image et l'arrière-plan, ou un autre objet, commence. Ils voient juste une collection de pixels qui ont des motifs similaires aux collections de pixels qu'ils ont appris à associer à certaines étiquettes. Cela fonctionne très bien pour les problèmes d'identification ou de catégorisation, mais s'effondre en essayant de comparer deux objets.
Pour montrer que c'était bien la raison pour laquelle les algorithmes tombaient en panne, Serre et son équipe ont réalisé des expériences qui ont évité à l'ordinateur d'avoir à individuer des objets par lui-même. Au lieu de montrer à l'ordinateur deux objets dans la même image, les chercheurs ont montré à l'ordinateur les objets un par un dans des images séparées. Les expériences ont montré que les algorithmes n'avaient aucun problème à apprendre une relation identique ou différente tant qu'ils n'avaient pas à voir les deux objets dans la même image.
La source du problème dans l'individuation des objets, Serre dit, est l'architecture des systèmes d'apprentissage automatique qui alimentent les algorithmes. Les algorithmes utilisent des réseaux de neurones convolutifs, des couches d'unités de traitement connectées qui imitent vaguement des réseaux de neurones dans le cerveau. Une différence clé par rapport au cerveau est que les réseaux artificiels sont exclusivement « feed-forward », ce qui signifie que les informations circulent à sens unique à travers les couches du réseau. Ce n'est pas ainsi que fonctionne le système visuel chez l'homme, selon Serre.
"Si vous regardez l'anatomie de notre propre système visuel, vous trouvez qu'il y a beaucoup de connexions récurrentes, où l'information passe d'une zone visuelle supérieure à une zone visuelle inférieure et inversement, " dit Serre.
Bien qu'il ne soit pas clair exactement ce que font ces retours, Serre dit, il est probable qu'ils aient quelque chose à voir avec notre capacité à prêter attention à certaines parties de notre champ visuel et à faire des représentations mentales des objets dans notre esprit.
"Vraisemblablement, les gens s'occupent d'un objet, construire une représentation de caractéristiques liée à cet objet dans leur mémoire de travail, " dit Serre. " Puis ils portent leur attention sur un autre objet. Lorsque les deux objets sont représentés dans la mémoire de travail, votre système visuel est capable de faire des comparaisons identiques ou différentes."
Serre et ses collègues émettent l'hypothèse que la raison pour laquelle les ordinateurs ne peuvent rien faire de tel est que les réseaux de neurones à anticipation ne permettent pas le type de traitement récurrent requis pour cette individuation et cette représentation mentale des objets. Il pourrait être, Serre dit, que rendre la vision par ordinateur plus intelligente nécessitera des réseaux de neurones qui se rapprochent plus étroitement de la nature récurrente du traitement visuel humain.