Les prédictions des sons ont été réalisées grâce à une méthode améliorée développée par une équipe internationale de chercheurs. Crédit: Journal IEEE/CAA d'Automatica Sinica
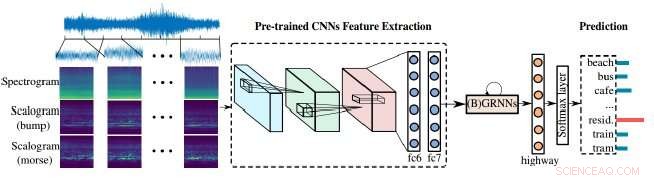
Les chercheurs ont démontré une méthode améliorée pour les machines d'analyse audio pour traiter notre monde bruyant. Leur approche repose sur la combinaison de scalogrammes et de spectrogrammes - les représentations visuelles de l'audio - ainsi que de réseaux de neurones convolutifs (CNN), l'outil d'apprentissage utilisé par les machines pour mieux analyser les images visuelles. Dans ce cas, les images visuelles sont utilisées pour analyser l'audio afin de mieux identifier et classer le son.
L'équipe a publié ses résultats dans la revue Journal IEEE/CAA d'Automatica Sinica ( JAS ), une publication conjointe de l'IEEE et de l'Association chinoise de l'automatisation.
« Les machines ont fait de grands progrès dans l'analyse de la parole et de la musique, mais l'analyse générale du son a pris beaucoup de retard - généralement, la plupart des « événements » sonores isolés tels que des coups de feu et autres ont été ciblés dans le passé, " a déclaré Björn Schuller, professeur et président de l'Intelligence embarquée pour les soins de santé et le bien-être à l'Université d'Augsbourg en Allemagne, qui a dirigé la recherche. « L'audio du monde réel est généralement un mélange hautement mélangé de différentes sources sonores, chacune ayant des états et des caractéristiques différents. »
Schuller cite le bruit d'une voiture comme exemple. Ce n'est pas un événement audio singulier; des parties assez différentes des pièces de la voiture, ses pneus interagissant avec la route, la marque et la vitesse de la voiture fournissent toutes leurs propres signatures uniques.
"À la fois, il peut y avoir de la musique ou de la parole dans la voiture, " dit Schuller, qui est également professeur agrégé d'apprentissage automatique à l'Imperial College de Londres, et professeur invité à l'École d'informatique et de technologie de l'Institut de technologie de Harbin en Chine. « Une fois que les ordinateurs pourront comprendre toutes les parties de cette « scène acoustique », ils seront considérablement meilleurs pour le décomposer en chaque partie et attribueront chaque partie comme décrit."
Les spectrogrammes fournissent une représentation visuelle des scènes audio, mais ils ont une résolution temps-fréquence fixe, c'est le moment où les fréquences changent. Scalogrammes, d'autre part, offrir une représentation visuelle plus détaillée des scènes acoustiques que les spectrogrammes, par exemple, les scènes acoustiques comme la musique, la parole ou d'autres sons dans la voiture peuvent désormais être mieux représentées.
"Il y a généralement plusieurs sons qui se produisent dans une scène donc... il devrait y avoir plusieurs fréquences et elles changent avec le temps, " dit Zhao Ren, un auteur sur le papier et un doctorat. candidat à l'Université d'Augsbourg qui travaille avec Schuller. "Heureusement, les scalogrammes pourraient résoudre ce problème exactement car il intègre plusieurs échelles. »
« Les scalogrammes peuvent être utilisés pour aider les spectrogrammes à extraire des caractéristiques pour la classification des scènes acoustiques, " Ren dit, et les spectrogrammes et les scalogrammes doivent être capables d'apprendre pour continuer à s'améliorer.
"Plus loin, les réseaux de neurones pré-entraînés établissent un pont entre [l'] image et le traitement audio."
Les réseaux de neurones pré-entraînés utilisés par les auteurs sont des réseaux de neurones convolutifs (CNN). Les CNN s'inspirent du fonctionnement des neurones dans le cortex visuel des animaux et les réseaux neuronaux artificiels peuvent être utilisés pour traiter avec succès l'imagerie visuelle. De tels réseaux sont cruciaux dans l'apprentissage automatique, et dans ce cas, aider à améliorer les scalogrammes.
Les CNN reçoivent une formation avant d'être appliqués à une scène, mais ils apprennent surtout de l'exposition. En apprenant des sons à partir d'une combinaison de différentes fréquences et échelles, l'algorithme peut mieux prédire les sources et, finalement, prédire le résultat d'un bruit inhabituel, comme un dysfonctionnement du moteur de la voiture.
"Le but ultime est l'audition/l'écoute machine de manière holistique... à travers la parole, musique, et sonner comme un être humain le ferait, " Schuller a dit, notant que cela se combinerait avec les travaux déjà avancés en analyse de la parole pour fournir une compréhension plus riche et plus approfondie, "pour ensuite être en mesure d'obtenir 'l'image entière' dans l'audio."