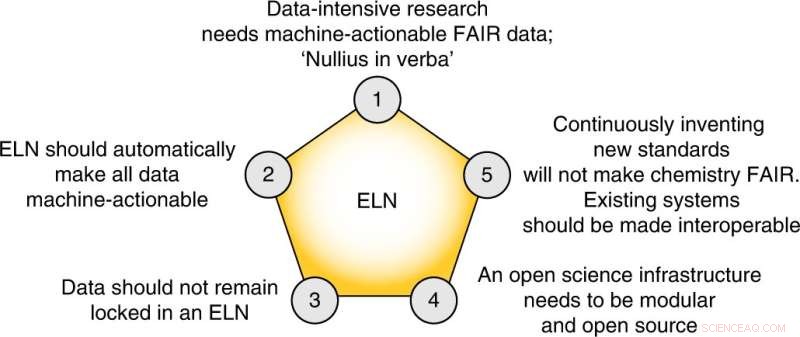
Les cinq thèses centrales de cette perspective. Crédit :Chimie de la nature (2022). DOI :10.1038/s41557-022-00910-7
L'un des aspects les plus difficiles de la chimie moderne est la gestion des données. Par exemple, lors de la synthèse d'un nouveau composé, les scientifiques passeront par de multiples tentatives d'essais et d'erreurs pour trouver les bonnes conditions pour la réaction, générant ainsi des quantités massives de données brutes. Ces données sont d'une valeur incroyable, car, comme les humains, les algorithmes d'apprentissage automatique peuvent apprendre beaucoup des expériences ratées et partiellement réussies.
La pratique actuelle consiste cependant à ne publier que les expériences les plus réussies, car aucun humain ne peut traiter de manière significative le nombre massif de celles qui ont échoué. Mais l'IA a changé cela; c'est exactement ce que ces méthodes d'apprentissage automatique peuvent faire, à condition que les données soient stockées dans un format exploitable par la machine pour que n'importe qui puisse les utiliser.
"Pendant longtemps, nous avions besoin de compresser l'information en raison du nombre limité de pages dans les articles de revues imprimées", explique le professeur Berend Smit, qui dirige le Laboratoire de simulation moléculaire de l'EPFL Valais Wallis. "De nos jours, de nombreuses revues n'ont même plus d'éditions imprimées ; cependant, les chimistes sont toujours aux prises avec des problèmes de reproductibilité parce qu'il manque des détails cruciaux aux articles de revues. Les chercheurs "perdent" du temps et des ressources en reproduisant les expériences "ratées" des auteurs et ont du mal à s'appuyer sur résultats publiés car les données brutes sont rarement publiées."
Mais le volume n'est pas le seul problème ici; la diversité des données en est un autre :les groupes de recherche utilisent différents outils comme le logiciel Electronic Lab Notebook, qui stocke les données dans des formats propriétaires parfois incompatibles entre eux. Ce manque de standardisation rend presque impossible pour les groupes de partager des données.
Maintenant, Smit, avec Luc Patiny et Kevin Jablonka à l'EPFL, ont publié une perspective dans Nature Chemistry présentant une plate-forme ouverte pour l'ensemble du flux de travail de la chimie :de la création d'un projet à sa publication.
Les scientifiques envisagent la plate-forme comme intégrant « de manière transparente » trois étapes cruciales :la collecte de données, le traitement des données et la publication des données, le tout à un coût minimal pour les chercheurs. Le principe directeur est que les données doivent être JUSTES :faciles à trouver, accessibles, interopérables et réutilisables. "Au moment de la collecte des données, les données seront automatiquement converties dans un format FAIR standard, ce qui permettra de publier automatiquement toutes les expériences "échouées" et partiellement réussies avec l'expérience la plus réussie", explique Smit.
Mais les auteurs vont plus loin en proposant que les données soient également exploitables par la machine. "Nous voyons de plus en plus d'études de science des données en chimie", déclare Jablonka. "En effet, les résultats récents de l'apprentissage automatique tentent de résoudre certains des problèmes que les chimistes considèrent comme insolubles. Par exemple, notre groupe a fait d'énormes progrès dans la prédiction des conditions de réaction optimales à l'aide de modèles d'apprentissage automatique. Mais ces modèles seraient beaucoup plus précieux s'ils pourraient également apprendre les conditions de réaction qui échouent, mais sinon, ils restent biaisés car seules les conditions réussies sont publiées."
Enfin, les auteurs proposent cinq étapes concrètes que le terrain doit suivre pour créer un plan de gestion des données FAIR :
"Nous pensons qu'il n'est pas nécessaire d'inventer de nouveaux formats de fichiers ou de nouvelles technologies", déclare Patiny. "En principe, toute la technologie est là, et nous devons adopter les technologies existantes et les rendre interopérables."
Les auteurs soulignent également que le simple fait de stocker des données dans n'importe quel cahier de laboratoire électronique - la tendance actuelle - ne signifie pas nécessairement que les humains et les machines peuvent réutiliser les données. Au contraire, les données doivent être structurées et publiées dans un format standardisé, et elles doivent également contenir suffisamment de contexte pour permettre des actions basées sur les données.
"Notre point de vue offre une vision de ce que nous pensons être les éléments clés pour combler le fossé entre les données et l'apprentissage automatique pour les problèmes fondamentaux de la chimie", déclare Smit. "Nous fournissons également une solution de science ouverte dans laquelle l'EPFL peut prendre l'initiative." L'apprentissage automatique décrypte les états d'oxydation des structures cristallines