Oier Mees démontrant le fonctionnement de la nouvelle approche. Crédit :Mees et al.
Avec plus de robots faisant maintenant leur chemin dans un certain nombre de paramètres, les chercheurs essaient de rendre leurs interactions avec les humains aussi fluides et naturelles que possible. Entraîner les robots à répondre immédiatement aux instructions vocales, tels que " ramasser le verre, déplacez-le vers la droite, " etc., serait idéal dans de nombreuses situations, car cela permettrait à terme des interactions homme-robot plus directes et intuitives. Cependant, ce n'est pas toujours facile, car il nécessite que le robot comprenne les instructions d'un utilisateur, mais aussi de savoir déplacer des objets selon des relations spatiales précises.
Des chercheurs de l'Université de Fribourg en Allemagne ont récemment mis au point une nouvelle approche pour enseigner aux robots comment déplacer des objets selon les instructions des utilisateurs humains, qui fonctionne en classant les représentations de scènes « hallucinées ». Leur papier, prépublié sur arXiv, sera présenté à la conférence internationale IEEE sur la robotique et l'automatisation (ICRA) à Paris, ce juin.
« Dans notre travail, nous nous concentrons sur les instructions de placement d'objets relationnels, comme « placez la tasse à droite de la boîte » ou « mettez le jouet jaune sur la boîte, '" Oier Mees, l'un des chercheurs qui a mené l'étude, a déclaré TechXplore. "Faire cela, le robot doit raisonner sur l'endroit où placer la tasse par rapport à la boîte ou à tout autre objet de référence afin de reproduire la relation spatiale décrite par un utilisateur.
Entraîner des robots à comprendre les relations spatiales et à déplacer des objets en conséquence peut être très difficile, car les instructions d'un utilisateur ne délimitent généralement pas un emplacement spécifique dans une scène plus large observée par le robot. En d'autres termes, si un utilisateur humain dit "placez la tasse à gauche de la montre, " à quelle distance à gauche de la montre le robot doit-il placer la tasse et où se trouve la limite exacte entre les différentes directions (par exemple, droit, la gauche, devant de, derrière, etc.)?
« En raison de cette ambiguïté inhérente, il n'y a pas non plus de vérité terrain ou de données « correctes » qui peuvent être utilisées pour apprendre à modéliser les relations spatiales, " a déclaré Mees. " Nous abordons le problème de l'indisponibilité des annotations de vérité au sol des relations spatiales des relations spatiales du point de vue de l'apprentissage auxiliaire. "
L'idée principale derrière l'approche conçue par Mees et ses collègues est que lorsqu'on leur donne deux objets et une image représentant le contexte dans lequel ils se trouvent, il est plus facile de déterminer la relation spatiale entre eux. Cela permet aux robots de détecter si un objet est à gauche de l'autre, en plus, devant elle, etc.
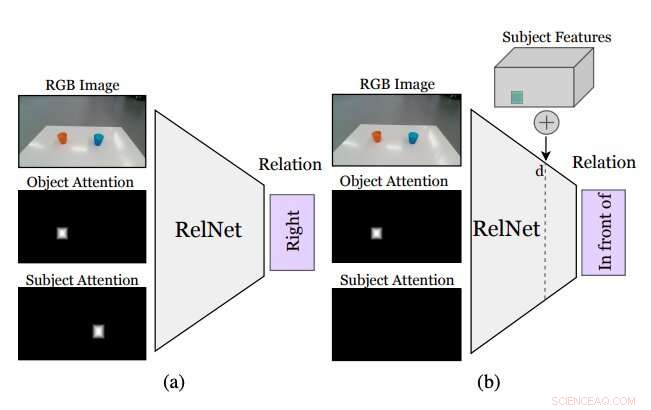
Figure résumant le fonctionnement de l'approche conçue par les chercheurs. Un CNN auxiliaire, appelé RelNet, est entraîné à prédire des relations spatiales à partir de l'image d'entrée et de deux masques d'attention se référant à deux objets formant une relation. (a) après la formation, le réseau peut être « trompé » pour classer les scènes hallucinées en (b) mettant en œuvre des caractéristiques de haut niveau d'éléments à différents emplacements spatiaux. Crédit :Mees et al.
Bien que l'identification d'une relation spatiale entre deux objets ne spécifie pas où les objets doivent être placés pour reproduire cette relation, l'insertion d'autres objets dans la scène pourrait permettre au robot d'inférer une distribution sur plusieurs relations spatiales. L'ajout de ces inexistants (c'est-à-dire, halluciné) des objets à ce que le robot voit devrait lui permettre d'évaluer à quoi ressemblerait la scène s'il effectuait une action donnée (c'est-à-dire, placer l'un des objets à un endroit précis sur la table ou sur la surface devant lui).
"Le plus souvent, « coller » des objets de manière réaliste dans une image nécessite soit l'accès à des modèles et des silhouettes 3D, soit une conception minutieuse de la procédure d'optimisation des réseaux antagonistes génératifs (GAN), " Mees a dit. " De plus, "coller" naïvement des masques d'objets dans les images crée de subtils artefacts de pixels qui conduisent à des caractéristiques sensiblement différentes et à la formation se concentrant à tort sur ces divergences. Nous adoptons une approche différente et implantons des caractéristiques de haut niveau d'objets dans des cartes de caractéristiques de la scène générées par un réseau de neurones convolutifs pour halluciner les représentations de scènes, qui sont ensuite classés comme tâche auxiliaire pour obtenir le signal d'apprentissage."
Avant d'entraîner un réseau de neurones convolutifs (CNN) pour apprendre des relations spatiales basées sur des objets hallucinés, les chercheurs devaient s'assurer qu'il était capable de classer les relations entre des paires individuelles d'objets à partir d'une seule image. Ensuite, ils ont "truqué" leur réseau, surnommé RelNet, dans la classification des scènes « hallucinées » en implantant des caractéristiques de haut niveau d'objets à différents emplacements spatiaux.
"Notre approche permet à un robot de suivre des instructions de placement en langage naturel données par des utilisateurs humains avec une collecte de données ou une heuristique minimale, " a déclaré Mees. " Tout le monde aimerait avoir un robot de service à la maison qui peut effectuer des tâches en comprenant des instructions en langage naturel. C'est une première étape pour permettre à un robot de mieux comprendre la signification des prépositions spatiales couramment utilisées."
La plupart des méthodes existantes pour entraîner des robots à déplacer des objets utilisent des informations liées aux formes 3D des objets pour modéliser des relations spatiales par paires. Une limitation clé de ces techniques est qu'elles nécessitent souvent des composants technologiques supplémentaires, tels que les systèmes de suivi qui peuvent suivre les mouvements de différents objets. L'approche proposée par Mees et ses collègues, d'autre part, ne nécessite aucun outil supplémentaire, car il n'est pas basé sur des techniques de vision 3D.
Les chercheurs ont évalué leur méthode dans une série d'expériences impliquant de vrais utilisateurs humains et des robots. Les résultats de ces tests étaient très prometteurs, car leur méthode a permis aux robots d'identifier efficacement les meilleures stratégies pour placer des objets sur une table conformément aux relations spatiales définies par les instructions orales d'un utilisateur humain.
"Notre nouvelle approche des représentations de scènes hallucinantes peut également avoir de multiples applications dans les communautés de la robotique et de la vision par ordinateur, comme souvent les robots doivent être capables d'estimer la qualité d'un état futur afin de raisonner sur les actions qu'ils doivent entreprendre, " a déclaré Mees. " Il pourrait également être utilisé pour améliorer les performances de nombreux réseaux de neurones, tels que les réseaux de détection d'objets, en utilisant des représentations de scènes hallucinées comme une forme d'augmentation de données."
Mees et ses collègues, nous avons pu modéliser un ensemble de prépositions spatiales en langage naturel (par exemple, à droite, la gauche, au dessus de, etc.) de manière fiable et sans utiliser d'outils de vision 3D. À l'avenir, l'approche présentée dans leur étude pourrait être utilisée pour améliorer les capacités des robots existants, leur permettant d'effectuer plus efficacement des tâches simples de déplacement d'objets tout en suivant les instructions vocales d'un utilisateur humain.
Pendant ce temps, leur article pourrait éclairer le développement de techniques similaires pour améliorer les interactions entre les humains et les robots lors d'autres tâches de manipulation d'objets. Si couplé avec des méthodes d'apprentissage auxiliaires, l'approche développée par Mees et ses collègues peut également réduire les coûts et les efforts associés à la compilation d'ensembles de données pour la recherche en robotique, car il permet la prédiction de probabilités au niveau des pixels sans nécessiter de grands ensembles de données annotés.
"Nous pensons qu'il s'agit d'un premier pas prometteur vers une compréhension partagée entre les humains et les robots, " conclut Mees. " A l'avenir, nous voulons étendre notre approche pour incorporer une compréhension des expressions référentes, afin de développer un système pick-and-place qui suit les instructions en langage naturel."
© 2020 Réseau Science X