De nombreuses études scientifiques ne résistent pas aux tests ultérieurs. Crédit :A et N photographie/Shutterstock.com
Dans un essai d'un nouveau médicament pour guérir le cancer, 44 pour cent des 50 patients ont obtenu une rémission après le traitement. Sans la drogue, seulement 32 pour cent des patients précédents ont fait de même. Le nouveau traitement semble prometteur, mais est-ce mieux que la norme?
Cette question est difficile, les statisticiens ont donc tendance à répondre à une question différente. Ils examinent leurs résultats et calculent ce qu'on appelle une valeur p. Si la valeur p est inférieure à 0,05, les résultats sont "statistiquement significatifs" - en d'autres termes, peu probable d'être causé par le hasard.
Le problème est, de nombreux résultats statistiquement significatifs ne se répliquent pas. Un traitement qui s'avère prometteur dans un essai ne montre aucun avantage lorsqu'il est administré au groupe de patients suivant. Ce problème est devenu si grave qu'une revue de psychologie a en fait complètement interdit les valeurs p.
Mes collègues et moi avons étudié ce problème, et nous pensons que nous savons ce qui le cause. La barre pour revendiquer une signification statistique est tout simplement trop basse.
La plupart des hypothèses sont fausses
La collaboration scientifique ouverte, une organisation à but non lucratif axée sur la recherche scientifique, essayé de reproduire 100 expériences de psychologie publiées. Alors que 97 des expériences initiales ont rapporté des résultats statistiquement significatifs, seulement 36 des études répétées l'ont fait.
Plusieurs étudiants diplômés et moi avons utilisé ces données pour estimer la probabilité qu'une expérience psychologique choisie au hasard ait testé un effet réel. Nous avons constaté que seulement environ 7 pour cent l'ont fait. Dans une étude similaire, l'économiste Anna Dreber et ses collègues ont estimé que seulement 9 % des expériences se reproduiraient.
Les deux analyses suggèrent que seulement environ un nouveau traitement expérimental sur 13 en psychologie - et probablement de nombreuses autres sciences sociales - s'avérera être un succès.
Cela a des implications importantes lors de l'interprétation des valeurs p, surtout quand ils sont proches de 0,05.
Le facteur Bayes
Les valeurs p proches de 0,05 sont plus susceptibles d'être dues au hasard que la plupart des gens ne le pensent.
Pour comprendre le problème, revenons à notre essai de drogue imaginaire. Rappelles toi, 22 des 50 patients sous le nouveau médicament sont entrés en rémission, contre une moyenne de seulement 16 patients sur 50 sous l'ancien traitement.
La probabilité de voir 22 succès ou plus sur 50 est de 0,05 si le nouveau médicament n'est pas meilleur que l'ancien. Cela signifie que la valeur p pour cette expérience est statistiquement significative. Mais nous voulons savoir si le nouveau traitement est vraiment une amélioration, ou si ce n'est pas mieux que l'ancienne façon de faire les choses.
Découvrir, nous devons combiner les informations contenues dans les données avec les informations disponibles avant la réalisation de l'expérience, ou les « cotes antérieures ». Les cotes antérieures reflètent des facteurs qui ne sont pas directement mesurés dans l'étude. Par exemple, ils pourraient expliquer le fait que dans 10 autres essais de médicaments similaires, aucun ne s'est avéré efficace.
Si le nouveau médicament n'est pas meilleur que l'ancien, ensuite, les statistiques nous indiquent que la probabilité de voir exactement 22 succès sur 50 dans cet essai est de 0,0235 – relativement faible.
Et si le nouveau médicament était réellement meilleur ? Nous ne connaissons pas réellement le taux de réussite du nouveau médicament, mais une bonne supposition est qu'il est proche du taux de réussite observé, 22 sur 50. Si nous supposons que, alors la probabilité d'observer exactement 22 réussites sur 50 est de 0,113 – environ cinq fois plus probable. (Pas presque 20 fois plus probable, bien que, comme vous pouvez le deviner si vous saviez que la valeur p de l'expérience était de 0,05.)
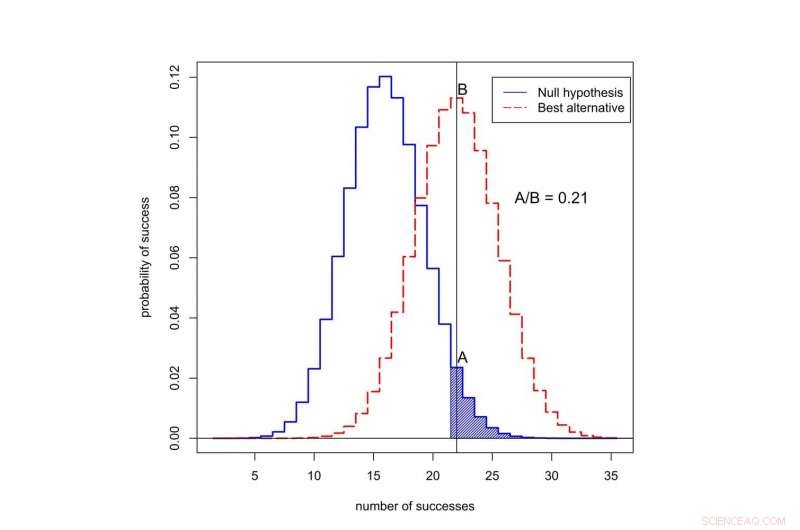
Quelle est la probabilité d'observer le succès dans 50 essais ? La courbe noire représente les probabilités sous l'« hypothèse nulle, ’ quand le nouveau traitement n’est pas meilleur que l’ancien. La courbe rouge représente les probabilités lorsque le nouveau traitement est meilleur. La zone ombrée représente la valeur p. Dans ce cas, le rapport des probabilités attribuées à 22 succès est A divisé par B, ou 0,21. Crédit :Valen Johnson, CC BY-SA
Ce rapport des probabilités est appelé facteur de Bayes. Nous pouvons utiliser le théorème de Bayes pour combiner le facteur de Bayes avec les cotes précédentes pour calculer la probabilité que le nouveau traitement soit meilleur.
Pour le bien de l'argument, supposons que seulement 1 traitement expérimental contre le cancer sur 13 s'avérera être un succès. C'est proche de la valeur que nous avons estimée pour les expériences de psychologie.
Lorsque nous combinons ces cotes antérieures avec le facteur de Bayes, il s'avère que la probabilité que le nouveau traitement ne soit pas meilleur que l'ancien est d'au moins 0,71. Mais la valeur p statistiquement significative de 0,05 suggère exactement le contraire !
Une nouvelle approche
Cette incohérence est typique de nombreuses études scientifiques. C'est particulièrement courant pour les valeurs p autour de 0,05. Cela explique pourquoi une proportion aussi élevée de résultats statistiquement significatifs ne se réplique pas.
Alors, comment devrions-nous évaluer les affirmations initiales d'une découverte scientifique ? En septembre, mes collègues et moi avons proposé une nouvelle idée :seules les valeurs p inférieures à 0,005 doivent être considérées comme statistiquement significatives. Les valeurs p comprises entre 0,005 et 0,05 devraient simplement être qualifiées de suggestives.
Dans notre proposition, les résultats statistiquement significatifs sont plus susceptibles de se reproduire, même après avoir tenu compte des faibles probabilités antérieures qui se rapportent généralement aux études dans le domaine social, sciences biologiques et médicales.
Quoi de plus, nous pensons que la signification statistique ne devrait pas servir de seuil clair pour la publication. Des résultats statistiquement suggestifs – voire des résultats largement peu concluants – pourraient également être publiés, selon qu'ils ont rapporté ou non des preuves préliminaires importantes concernant la possibilité qu'une nouvelle théorie puisse être vraie.
Le 11 octobre, nous avons présenté cette idée à un groupe de statisticiens lors du Symposium ASA sur l'inférence statistique à Bethesda, Maryland. Notre objectif en changeant la définition de la signification statistique est de restaurer le sens voulu de ce terme :que les données ont fourni un soutien substantiel pour une découverte scientifique ou un effet de traitement.
Critiques de notre idée
Tout le monde n'est pas d'accord avec notre proposition, y compris un autre groupe de scientifiques dirigé par le psychologue Daniel Lakens.
Ils soutiennent que la définition des facteurs de Bayes est trop subjective, et que les chercheurs peuvent faire d'autres hypothèses qui pourraient modifier leurs conclusions. Dans l'essai clinique, par exemple, Lakens pourrait faire valoir que les chercheurs pourraient déclarer le taux de rémission à trois mois plutôt qu'à six mois, s'il fournissait des preuves plus solides en faveur du nouveau médicament.
Lakens et son groupe estiment également que l'estimation selon laquelle seulement une expérience sur 13 se répliquera est trop faible. Ils soulignent que cette estimation n'inclut pas les effets tels que le p-hacking, un terme lorsque les chercheurs analysent à plusieurs reprises leurs données jusqu'à ce qu'ils trouvent une valeur p forte.
Au lieu de relever la barre de la signification statistique, le groupe de Lakens pense que les chercheurs devraient définir et justifier leur propre niveau de signification statistique avant de mener leurs expériences.
Je ne suis pas d'accord avec de nombreuses affirmations du groupe Lakens - et, d'un point de vue purement pratique, Je pense que leur proposition est un non-starter. La plupart des revues scientifiques ne fournissent pas de mécanisme permettant aux chercheurs d'enregistrer et de justifier leur choix de valeurs p avant de mener des expériences. Plus important, permettre aux chercheurs de fixer leurs propres seuils de preuves ne semble pas être un bon moyen d'améliorer la reproductibilité de la recherche scientifique.
La proposition de Lakens ne fonctionnerait que si les éditeurs de revues et les agences de financement acceptaient à l'avance de publier des rapports d'expériences qui n'ont pas été menées sur la base de critères que les scientifiques eux-mêmes ont imposés. Je pense qu'il est peu probable que cela se produise dans un avenir proche.
Jusqu'à ce qu'il le fasse, Je vous recommande de ne pas faire confiance aux allégations d'études scientifiques basées sur des valeurs p proches de 0,05. Insistez sur une norme plus élevée.
Cet article a été initialement publié sur The Conversation. Lire l'article original.