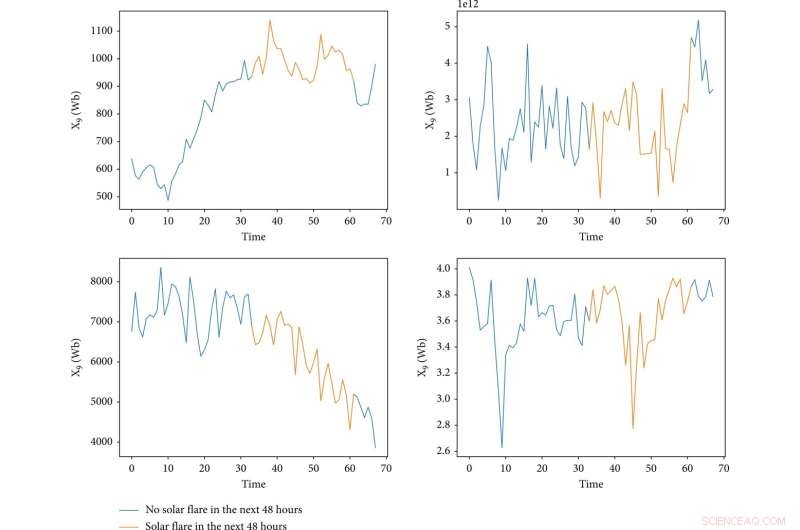
La visualisation de quatre caractéristiques pendant l'existence d'une région active. L'axe des x représente le temps et son unité est un échantillon, où "0" représente l'heure de début d'une région active, et l'écart de temps entre les temps adjacents est de 1,5 h. L'axe des ordonnées représente la valeur d'une caractéristique. Les lignes bleues indiquent qu'il n'y a pas d'éruption solaire dans les prochaines 48 heures, et les lignes jaunes sont à l'opposé. Source :Espace :science et technologie
Les éruptions solaires sont des tempêtes solaires provoquées par un champ magnétique dans la zone d'activité solaire. Lorsque ce rayonnement parasite arrive à proximité de la Terre, la photo-ionisation augmente la densité électronique dans la couche D de l'ionosphère, provoquant l'absorption des communications radio haute fréquence, la scintillation des communications par satellite et une interférence accrue du bruit de fond avec le radar.
Les statistiques et l'expérience montrent que plus l'éruption est importante, plus elle est susceptible d'être accompagnée d'autres explosions solaires telles qu'un événement de protons solaires, et plus les effets sur la Terre sont graves, affectant ainsi les vols spatiaux, les communications, la navigation, la transmission d'énergie et autres systèmes technologiques.
La fourniture d'informations prévisionnelles sur la probabilité et l'intensité des flambées de poussées est un élément important au début de la prévision opérationnelle de la météorologie spatiale. L'étude de modélisation de la prévision des éruptions solaires est une partie nécessaire de la prévision précise des éruptions et a une valeur d'application importante. Dans un article de recherche récemment publié dans Space :Science &Technology , Hong Chen du College of Science, Huazhong Agricultural University, a combiné l'algorithme de clustering k-means et plusieurs modèles CNN pour créer un système d'alerte capable de prédire si une éruption solaire se produirait dans les 48 prochaines heures.
Tout d'abord, l'auteur a présenté les données utilisées dans l'article et les a analysées d'un point de vue statistique pour fournir une base pour la conception du système d'alerte aux éruptions solaires. Pour réduire l'effet de projection, le centre de la région active situé à ±30° du centre du disque solaire a été sélectionné. Après cela, l'auteur a étiqueté les données en fonction des données sur les éruptions solaires fournies par la NOAA, y compris les heures de début et de fin des éruptions, le numéro de la région active, la magnitude des éruptions, etc.
Il y avait un sérieux déséquilibre entre le nombre d'échantillons positifs et négatifs dans l'ensemble de données. Pour atténuer le déséquilibre des échantillons positifs et négatifs, un principe a été trouvé pour sélectionner autant que possible les événements qui ont des échantillons positifs. L'auteur a visualisé la distribution de densité de probabilité de chaque caractéristique dans tous les échantillons négatifs et tous les échantillons positifs. On pouvait facilement trouver que les distributions de densité de probabilité des échantillons négatifs étaient toutes des distributions asymétriques négatives et que les caractéristiques des échantillons positifs étaient généralement plus grandes que celles des échantillons négatifs. Ainsi, il était possible de filtrer les événements avec des échantillons positifs par les valeurs de caractéristique de chaque événement.
Ensuite, l'auteur a construit l'ensemble du pipeline avec une méthode contenant les deux étapes suivantes :le prétraitement des données et la formation du modèle. Pour effectuer le prétraitement des données, K-means, une méthode de regroupement non supervisée, a été utilisée pour regrouper les événements afin de réduire autant que possible les événements qui n'incluent que des échantillons négatifs.
Après le regroupement des k-moyennes, tous les événements ont été divisés en trois catégories, à savoir la catégorie A, la catégorie B et la catégorie C. L'auteur a constaté que le rapport des échantillons positifs dans la catégorie C est de 0,340633, ce qui est beaucoup plus élevé que celui de l'ensemble de données. Par conséquent, seules les données de la catégorie C ont été choisies comme données d'entrée pour la prochaine étape de l'algorithme.
Dans la 2e étape, les réseaux de neurones utilisés par l'auteur étaient Resnet18, Resnet34 et Xception, qui sont couramment utilisés dans l'apprentissage en profondeur. Les trois quarts des échantillons de la catégorie C ont été choisis au hasard. Dans chaque cas, il y avait des données de formation pour les modèles de réseau neuronal et le reste des échantillons étaient considérés comme des données de validation dans le processus de modèle de formation.
Pour éviter l'influence de la dimension, l'auteur a également normalisé les données d'origine. La méthode de normalisation était différente de celles couramment utilisées. Selon la formule de calcul de standardisation, si le label d'un échantillon était prédit à 1 par le réseau de neurones, cet échantillon était considéré comme un signal d'éruption solaire qui se produirait dans les 48 heures suivantes. Mais s'il est prévu qu'il soit égal à 0, la probabilité d'éruption solaire dans les 48 prochaines heures serait si faible qu'elle pourrait être ignorée.
Ensuite, l'auteur a mené des expériences et discuté des résultats. L'auteur a d'abord donné une introduction au cadre expérimental, puis a mené plusieurs expériences d'ablation et des comparaisons avec différents modèles pour vérifier l'amélioration de l'algorithme de clustering k-means et de la stratégie de boosting. En outre, l'auteur a également fait des comparaisons entre la méthode utilisée dans l'expérience et 13 autres algorithmes de classification binaire couramment utilisés pour présenter ses performances de prédiction.
Les résultats expérimentaux ont montré que les performances de prédiction du modèle intégrant plusieurs réseaux de neurones étaient meilleures que celles d'un seul réseau de neurones convolutifs. Enfin, les résultats de prédiction de Resnet18, Resnet34 et Xception ont été combinés par une stratégie de boosting. Pour tous les réseaux, le rappel peut être inchangé ou même fortement réduit après le regroupement. Cependant, la précision devait augmenter de manière significative.
Après regroupement, même si le taux d'échantillons positifs serait grandement amélioré, passant de 5% à 34%, près de 40% des informations des échantillons positifs seraient également perdues. L'auteur pensait que c'était la principale raison pour laquelle le rappel restait inchangé ou même diminuait. Cela signifiait également que le nombre d'échantillons positifs prédits dans l'expérience était inférieur à celui sans regroupement, mais la probabilité qu'un échantillon positif prédit soit un vrai positif était plus élevée.
Contrairement au phénomène selon lequel les performances de prédiction des autres méthodes de classification binaire diminuaient ou même étaient très médiocres après le regroupement, les performances de la méthode de l'auteur s'amélioraient de plus de 9 % après le regroupement. En conclusion, le système d'alerte précoce des éruptions solaires en deux étapes consistait en un algorithme de clustering non supervisé (k-means) et plusieurs modèles CNN, où le premier devait augmenter le taux d'échantillonnage positif, et le second intégrait les résultats de prédiction des modèles CNN. pour améliorer les performances de prédiction.
Les résultats de l'expérience ont prouvé l'efficacité de la méthode. Comment le scientifique a appliqué l'algorithme de recommandation pour anticiper les heures d'arrivée des CME