Penser en dehors de la colonne vertébrale :les surplombs font passer la technologie des données ADN à la vitesse supérieure. Crédit :Kaikai Chen
Le stockage des données ADN peut devenir plus facile à lire et à écrire qu'auparavant, selon des chercheurs du laboratoire Cavendish de l'Université de Cambridge au Royaume-Uni. Ils rapportent une technique qui peut également stocker des données cryptées, ainsi que la réécriture des données.
L'idée originale derrière le stockage de données ADN est de synthétiser de longues molécules d'ADN avec des séquences sur mesure d'unités de base qui codent des données numériques. La densité de données obtenue par cette approche est de plusieurs ordres de grandeur supérieure à celle des technologies magnétiques ou à semi-conducteurs en place, et dure des milliers au lieu de dizaines d'années. La longévité et la densité de données du stockage des données ADN seraient particulièrement utiles pour les archives de données sans certaines limitations importantes.
"L'un des plus gros problèmes est de faire de l'ADN, " dit Ulrich Keyser, professeur de physique appliquée à l'Université de Cambridge au Royaume-Uni. Il explique que la synthèse des molécules d'ADN de nova avec des séquences d'unités de base prescrites suffisamment longues pour stocker des données est difficile et nécessite des enzymes. « Avec notre approche, c'est comme les briques Lego. Vous le faites juste en mélangeant, se réchauffer et se refroidir."
La lecture des données stockées dans la séquence de paires de bases est également lente et coûteuse. La technologie de séquençage a parcouru un long chemin, mais il repose encore principalement sur la réplication de milliards de copies de la molécule pour amplifier les signaux des interactions protéiques, etc.
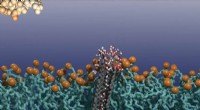
Une approche de séquençage alternative fait passer la molécule d'ADN à travers un nanopore et lit la séquence en temps réel à partir des changements de courant ionique au fur et à mesure que différentes paires de bases passent. Bien que moins cher et plus efficace, la lecture de bits à partir de paires de bases dans l'épine dorsale de l'ADN prend encore trop de temps pour les technologies de stockage de données. Cependant, en stockant des données sur des surplombs collés sur le backbone principal, Keyser et son équipe ont développé une approche que la technologie des nanopores peut lire facilement et avec précision, et le mélange simple peut écrire.
En incorporant des « prises d'orteil » sur les données écrites en surplomb, ils montrent qu'il peut être facilement supprimé et réécrit. "J'ai été surpris que la réécriture fonctionne et puisse être si simple, car c'est très difficile avec toute autre technique de données ADN, " dit Keyser.
Potentiel de détection
"L'idée avec laquelle nous avons commencé était de détecter l'amplification, " explique Kaikai Chen, le premier auteur de la Lettres nano papier rapportant ces résultats. « Ensuite, nous avons eu l'idée du stockage de données. »
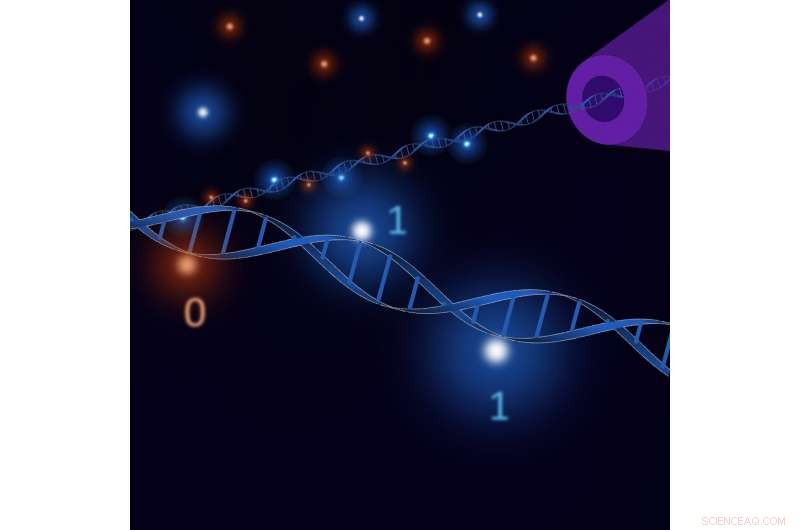
La clé de l'approche pionnière consiste à contrôler la façon dont les surplombs d'ADN simple brin sont "hybridés". Alors que la séquence de paires de bases dans le squelette de l'ADN est identique d'une molécule à l'autre, les chercheurs hybrident des surplombs spécifiques avec de l'ADN simple brin complémentaire qui est biotinylé tandis que le reste est annelé avec de l'ADN simple brin. Lorsque le brin complémentaire est biotinylé, il se lie aux molécules de streptavidine, qui fait un changement facilement détectable dans le courant ionique lorsque l'ADN passe à travers un nanopore, en le lisant comme "1". Lorsque le brin d'ADN en surplomb n'a pas de streptavidine, les données écrites sont "0". Le groupe a utilisé des techniques reconnues basées sur des molécules qui se concentrent sur des régions spécifiques de la molécule pour livrer le brin complémentaire correct à la bonne adresse.
Le "toehold" qui permet la réécriture n'est qu'un petit ADN simple brin supplémentaire qui dépasse après fonctionnalisation, ce qui le rend facile à supprimer et à réécrire. Laisser les brins biotinylés de côté laisse les données cryptées car seule une personne connaissant la séquence des surplombs d'ADN simple brin saura quelle séquence le brin complémentaire doit avoir pour fournir les brins biotinylés qui se lieront à la streptavidine, et ainsi distinguer les uns des zéros.
Futur
Le prochain défi pour la technologie serait la mise à l'échelle. Puisqu'ils exploitent un laboratoire de physique, Keyser ne considère pas cela comme l'objectif de leurs prochaines étapes en tant qu'équipe, bien que cela semble simple dans son principe avec l'utilisation de robots de pipetage ou de microfluidique. « Il existe déjà des entreprises qui proposent les produits de microfluidique qui pourraient être utilisés, " ajoute Chen.
Les chercheurs examinent maintenant quels autres groupes fonctionnels ils peuvent utiliser en plus de la streptavidine. "En principe, notre méthode peut s'adapter à différentes fonctionnalisations, " dit Chen. Ils ont utilisé la streptavidine pour leur démonstration de principe car c'est un groupe fonctionnel qu'ils connaissent bien. " C'est très simple et ça marche bien, " ajoute-t-il. Cependant, l'utilisation de groupes plus petits peut permettre un stockage à plus haute densité.
Aucun choix de groupe fonctionnel ne permettra tout à fait la densité de données obtenue en stockant les données dans la séquence de paires de bases. Keyser suggère que cela pourrait également expliquer pourquoi personne n'a pensé à essayer l'approche du bloc Lego auparavant. Bien que les travaux sur les nouvelles technologies tendent à s'inscrire dans le prolongement des techniques déjà démontrées plutôt qu'à adopter une approche orthogonale, l'accent mis sur l'optimisation de la densité des données a pu avoir un effet dissuasif supplémentaire. Encore, les avantages d'être plus rapide, lecture et écriture plus simples, et en particulier, réécriture, peut faire en sorte que le compromis en vaille la peine. Le stockage de données ADN réinscriptibles ouvre également des opportunités pour les calculs ADN, qui pourrait offrir une alternative à l'informatique traditionnelle qui, bien que lent, consomme très peu d'énergie et a donc de la valeur pour certaines applications.
© 2020 Réseau Science X