Crédit :La Conversation
Facebook a discrètement expérimenté la réduction de la quantité de contenu politique qu'il met dans les fils d'actualité des utilisateurs. Cette décision est une reconnaissance tacite que le fonctionnement des algorithmes de l'entreprise peut être un problème.
Le cœur du problème est la distinction entre provoquer une réponse et fournir le contenu que les gens veulent. Les algorithmes des médias sociaux (les règles que leurs ordinateurs suivent pour décider du contenu que vous voyez) dépendent fortement du comportement des gens pour prendre ces décisions. En particulier, ils surveillent le contenu auquel les gens réagissent ou avec lequel ils "interagissent" en aimant, en commentant et en partageant.
En tant qu'informaticien qui étudie la manière dont un grand nombre de personnes interagissent à l'aide de la technologie, je comprends la logique d'utiliser la sagesse des foules dans ces algorithmes. Je vois également des pièges importants dans la façon dont les entreprises de médias sociaux le font dans la pratique.
Des lions dans la savane aux likes sur Facebook
Le concept de la sagesse des foules suppose que l'utilisation des signaux des actions, opinions et préférences des autres comme guide conduira à des décisions judicieuses. Par exemple, les prédictions collectives sont normalement plus précises que les prédictions individuelles. L'intelligence collective est utilisée pour prédire les marchés financiers, les sports, les élections et même les épidémies.
Au cours de millions d'années d'évolution, ces principes ont été codés dans le cerveau humain sous la forme de biais cognitifs portant des noms tels que familiarité, simple exposition et effet de train en marche. Si tout le monde commence à courir, vous devriez également commencer à courir. peut-être que quelqu'un a vu un lion arriver et courir pourrait vous sauver la vie. Vous ne savez peut-être pas pourquoi, mais il est plus sage de poser des questions plus tard.
Votre cerveau capte des indices de l'environnement, y compris de vos pairs, et utilise des règles simples pour traduire rapidement ces signaux en décisions :suivez le gagnant, suivez la majorité, copiez votre voisin. Ces règles fonctionnent remarquablement bien dans des situations typiques car elles sont basées sur des hypothèses solides. Par exemple, ils supposent que les gens agissent souvent de manière rationnelle, qu'il est peu probable que beaucoup se trompent, que le passé prédit l'avenir, etc.
La technologie permet aux gens d'accéder aux signaux d'un nombre beaucoup plus grand d'autres personnes, dont la plupart ne sont pas connues. Les applications d'intelligence artificielle font un usage intensif de ces signaux de popularité ou d'"engagement", de la sélection des résultats des moteurs de recherche à la recommandation de musique et de vidéos, et de la suggestion d'amis au classement des publications sur les fils d'actualité.
Tout ce qui est viral ne mérite pas d'être
Nos recherches montrent que pratiquement toutes les plates-formes technologiques Web, telles que les médias sociaux et les systèmes de recommandation d'actualités, ont un fort biais de popularité. Lorsque les applications sont motivées par des indices tels que l'engagement plutôt que par des requêtes explicites des moteurs de recherche, le biais de popularité peut entraîner des conséquences imprévues néfastes.
Les médias sociaux comme Facebook, Instagram, Twitter, YouTube et TikTok s'appuient fortement sur les algorithmes d'IA pour classer et recommander le contenu. Ces algorithmes prennent en entrée ce que vous "aimez", commentez et partagez, en d'autres termes, le contenu avec lequel vous interagissez. L'objectif des algorithmes est de maximiser l'engagement en découvrant ce que les gens aiment et en le classant au sommet de leurs flux.
En surface, cela semble raisonnable. Si les gens aiment les nouvelles crédibles, les opinions d'experts et les vidéos amusantes, ces algorithmes devraient identifier un contenu de si haute qualité. Mais la sagesse des foules fait ici une hypothèse clé :que recommander ce qui est populaire aidera le contenu de haute qualité à "bouillir".
Nous avons testé cette hypothèse en étudiant un algorithme qui classe les éléments en utilisant un mélange de qualité et de popularité. Nous avons constaté qu'en général, le biais de popularité est plus susceptible de réduire la qualité globale du contenu. La raison en est que l'engagement n'est pas un indicateur fiable de la qualité lorsque peu de personnes ont été exposées à un élément. Dans ces cas, l'engagement génère un signal bruité, et l'algorithme est susceptible d'amplifier ce bruit initial. Une fois que la popularité d'un article de mauvaise qualité est suffisamment grande, elle continuera à s'amplifier.
Les algorithmes ne sont pas la seule chose affectée par le biais d'engagement, cela peut aussi affecter les gens. Les preuves montrent que l'information est transmise par "contagion complexe", ce qui signifie que plus une personne est exposée à une idée en ligne, plus elle est susceptible de l'adopter et de la partager. Lorsque les médias sociaux informent les gens qu'un article devient viral, leurs préjugés cognitifs entrent en jeu et se traduisent par l'envie irrésistible d'y prêter attention et de le partager.
Foules pas si sages
Nous avons récemment mené une expérience à l'aide d'une application d'information sur l'information appelée Fakey. C'est un jeu développé par notre labo, qui simule un fil d'actualité comme ceux de Facebook et Twitter. Les joueurs voient un mélange d'articles actuels provenant de fausses nouvelles, de la junk science, de sources hyper partisanes et conspiratrices, ainsi que de sources grand public. Ils obtiennent des points pour avoir partagé ou aimé des nouvelles provenant de sources fiables et pour avoir signalé des articles peu crédibles pour vérification des faits.
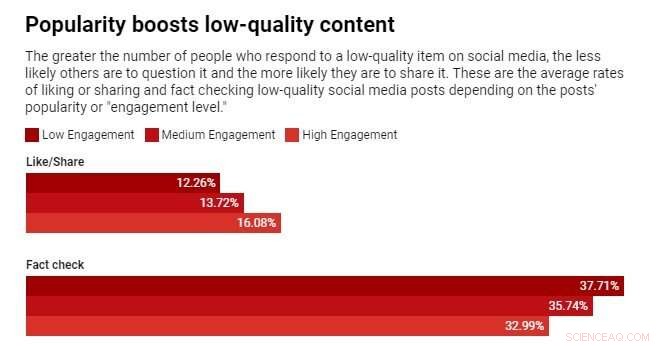
Nous avons constaté que les joueurs sont plus susceptibles d'aimer ou de partager et moins susceptibles de signaler des articles provenant de sources peu crédibles lorsque les joueurs peuvent voir que de nombreux autres utilisateurs ont interagi avec ces articles. L'exposition aux mesures d'engagement crée donc une vulnérabilité.
La sagesse des foules échoue parce qu'elle est construite sur la fausse hypothèse que la foule est composée de sources diverses et indépendantes. Il peut y avoir plusieurs raisons pour lesquelles ce n'est pas le cas.
Premièrement, en raison de la tendance des gens à s'associer à des personnes similaires, leurs quartiers en ligne ne sont pas très diversifiés. La facilité avec laquelle un utilisateur de médias sociaux peut se débarrasser de ceux avec qui il n'est pas d'accord pousse les gens dans des communautés homogènes, souvent appelées chambres d'écho.
Deuxièmement, parce que beaucoup d'amis sont amis les uns des autres, ils s'influencent mutuellement. Une expérience célèbre a démontré que savoir quelle musique vos amis aiment affecte vos propres préférences déclarées. Votre désir social de vous conformer déforme votre jugement indépendant.
Troisièmement, les signaux de popularité peuvent être manipulés. Au fil des ans, les moteurs de recherche ont développé des techniques sophistiquées pour contrer les soi-disant «fermes de liens» et d'autres stratagèmes pour manipuler les algorithmes de recherche. Les plates-formes de médias sociaux, en revanche, commencent tout juste à découvrir leurs propres vulnérabilités.
Les personnes visant à manipuler le marché de l'information ont créé de faux comptes, comme des trolls et des robots sociaux, et organisé de faux réseaux. Ils ont inondé le réseau pour donner l'impression qu'une théorie du complot ou un candidat politique est populaire, trompant à la fois les algorithmes de la plate-forme et les biais cognitifs des gens. Ils ont même modifié la structure des réseaux sociaux pour créer des illusions sur les opinions majoritaires.
Réduire l'engagement
Que faire? Les plateformes technologiques sont actuellement sur la défensive. Ils deviennent plus agressifs pendant les élections en supprimant les faux comptes et la désinformation nuisible. Mais ces efforts peuvent s'apparenter à un jeu de taupe.
Une autre approche préventive consisterait à ajouter de la friction. En d'autres termes, pour ralentir le processus de diffusion de l'information. Les comportements à haute fréquence tels que le like et le partage automatisés pourraient être inhibés par les tests CAPTCHA ou les frais. Cela réduirait non seulement les possibilités de manipulation, mais avec moins d'informations, les gens pourraient accorder plus d'attention à ce qu'ils voient. Cela laisserait moins de place au biais d'engagement pour affecter les décisions des gens.
Il serait également utile que les entreprises de médias sociaux ajustaient leurs algorithmes pour s'appuyer moins sur l'engagement pour déterminer le contenu qu'elles vous proposent.