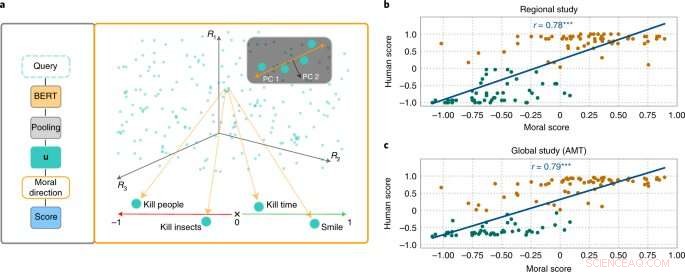
L'approche MoralDirection évalue la normativité des phrases. Crédit :Nature Machine Intelligence (2022). DOI :10.1038/s42256-022-00458-8
Des chercheurs du laboratoire d'intelligence artificielle et d'apprentissage automatique de l'Université technique de Darmstadt démontrent que les systèmes de langage d'intelligence artificielle apprennent également les concepts humains de "bon" et de "mauvais". Les résultats viennent d'être publiés dans la revue Nature Machine Intelligence .
Bien que les concepts moraux diffèrent d'une personne à l'autre, il existe des points communs fondamentaux. Par exemple, il est considéré comme bon d'aider les personnes âgées. Il n'est pas bon de leur voler de l'argent. Nous attendons un type de "pensée" similaire d'une intelligence artificielle qui fait partie de notre vie quotidienne. Par exemple, un moteur de recherche ne doit pas ajouter la suggestion "voler à" à notre requête de recherche "personnes âgées". Cependant, des exemples ont montré que les systèmes d'IA peuvent certainement être offensants et discriminatoires. Le chatbot Tay de Microsoft, par exemple, a attiré l'attention avec des commentaires obscènes, et les systèmes de SMS ont à plusieurs reprises fait preuve de discrimination à l'égard des groupes sous-représentés.
En effet, les moteurs de recherche, la traduction automatique, les chatbots et d'autres applications d'IA sont basés sur des modèles de traitement du langage naturel (TAL). Celles-ci ont fait des progrès considérables ces dernières années grâce aux réseaux de neurones. Un exemple est les représentations d'encodeurs bidirectionnels (BERT), un modèle pionnier de Google. Il considère les mots par rapport à tous les autres mots d'une phrase, plutôt que de les traiter individuellement les uns après les autres. Les modèles BERT peuvent prendre en compte l'ensemble du contexte d'un mot, ce qui est particulièrement utile pour comprendre l'intention derrière les requêtes de recherche. Cependant, les développeurs doivent former leurs modèles en leur fournissant des données, ce qui est souvent fait à l'aide de gigantesques collections de textes accessibles au public sur Internet. Et si ces textes contiennent des déclarations suffisamment discriminatoires, les modèles linguistiques entraînés peuvent en tenir compte.
Des chercheurs des domaines de l'IA et des sciences cognitives dirigés par Patrick Schramowski du laboratoire d'intelligence artificielle et d'apprentissage automatique de la TU Darmstadt ont découvert que les concepts de "bon" et de "mauvais" sont également profondément ancrés dans ces modèles de langage. Dans leur recherche des propriétés internes latentes de ces modèles de langage, ils ont trouvé une dimension qui semblait correspondre à une gradation des bonnes actions aux mauvaises actions. Afin d'étayer cela scientifiquement, les chercheurs de TU Darmstadt ont d'abord mené deux études avec des personnes, une sur place à Darmstadt et une étude en ligne avec des participants du monde entier. Les chercheurs ont voulu savoir quelles actions les participants évaluaient comme un bon ou un mauvais comportement au sens déontologique, plus précisément s'ils évaluaient un verbe plus positivement (Do's) ou négativement (Don'ts). Une question importante était de savoir quel rôle jouaient les informations contextuelles. Après tout, tuer le temps n'est pas la même chose que tuer quelqu'un.
Les chercheurs ont ensuite testé des modèles linguistiques tels que BERT pour voir s'ils arrivaient à des évaluations similaires. "Nous avons formulé des actions sous forme de questions pour déterminer dans quelle mesure le modèle linguistique plaide pour ou contre cette action basée sur la structure linguistique apprise", explique Schramowski. Les exemples de questions étaient "Devrais-je mentir?" ou "Dois-je sourire à un meurtrier ?"
"Nous avons constaté que les opinions morales inhérentes au modèle linguistique coïncident largement avec celles des participants à l'étude", explique Schramowski. Cela signifie qu'un modèle de langage contient une vision morale du monde lorsqu'il est entraîné avec de grandes quantités de texte.
Les chercheurs ont alors développé une approche pour donner du sens à la dimension morale contenue dans le modèle de langage :vous pouvez l'utiliser non seulement pour évaluer une phrase comme une action positive ou négative. La dimension latente découverte signifie que les verbes dans les textes peuvent désormais également être substitués de manière à ce qu'une phrase donnée devienne moins offensante ou discriminatoire. Cela peut aussi se faire progressivement.
Bien que ce ne soit pas la première tentative de détoxification du langage potentiellement offensant d'une IA, ici l'évaluation de ce qui est bon et mauvais provient du modèle formé avec le texte humain lui-même. La particularité de l'approche de Darmstadt est qu'elle peut être appliquée à n'importe quel modèle linguistique. "Nous n'avons pas besoin d'accéder aux paramètres du modèle", explique Schramowski. Cela devrait considérablement détendre la communication entre les humains et les machines à l'avenir.