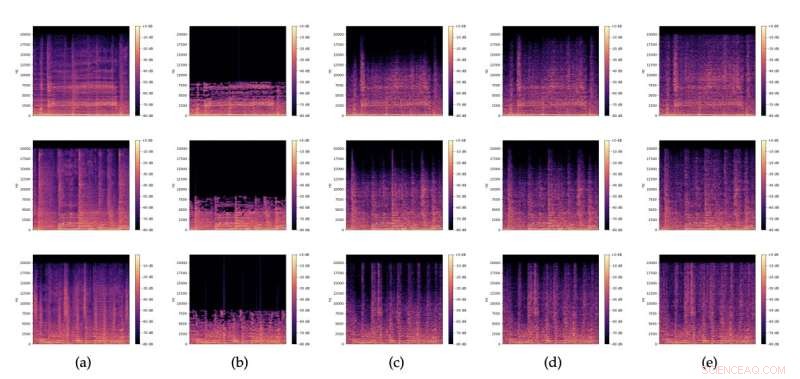
Spectrogrammes de (a) extraits audio originaux, (b) versions MP3 32kbit/s correspondantes, et (c), (d), (e) restaurations avec différents bruits z échantillonnés aléatoirement à partir de N (0,I). Crédit :Lattner &Nistal.
Au cours des dernières décennies, les informaticiens ont développé des technologies et des outils de plus en plus avancés pour stocker de grandes quantités de musique et de fichiers audio dans des appareils électroniques. Une étape importante pour le stockage de la musique a été le développement de la technologie MP3 (c'est-à-dire MPEG-1 couche 3), une technique permettant de compresser des séquences sonores ou des chansons dans de très petits fichiers qui peuvent être facilement stockés et transférés entre appareils.
L'encodage, l'édition et la compression des fichiers multimédias, y compris les fichiers PKZIP, JPEG, GIF, PNG, MP3, AAC, Cinepak et MPEG-2, sont réalisés à l'aide d'un ensemble de technologies connues sous le nom de codecs. Les codecs sont des technologies de compression avec deux composants clés :un encodeur qui compresse les fichiers et un décodeur qui les décompresse.
Il existe deux types de codecs, les codecs dits sans perte et avec perte. Lors de la décompression, les codecs sans perte, tels que les codecs PKZIP et PNG, reproduisent exactement le même fichier que les fichiers d'origine. Les méthodes de compression avec perte, en revanche, produisent un fac-similé du fichier original qui sonne (ou ressemble) à l'original mais occupe moins d'espace de stockage dans les appareils électroniques.
Les codecs audio avec perte fonctionnent essentiellement en compressant les flux audio numériques, en supprimant certaines données, puis en les décompressant. Généralement, la différence entre le fichier original et le fichier décompressé est difficile, voire impossible, à percevoir pour les humains.
Cependant, lorsque les codecs avec perte utilisent des taux de compression élevés, ils peuvent introduire des dégradations et altérer de manière perceptible les signaux audio. Récemment, des informaticiens ont tenté de surmonter cette limitation des codecs avec perte et d'améliorer la qualité des fichiers compressés à l'aide de techniques d'apprentissage en profondeur.
Des chercheurs de Sony Computer Science Laboratories (CSL) ont récemment développé une nouvelle méthode d'apprentissage en profondeur pour améliorer et restaurer la qualité des chansons et des enregistrements audio fortement compressés (c'est-à-dire des fichiers audio compressés par des codecs avec perte avec des taux de compression élevés). Cette méthode, présentée dans un article pré-publié sur arXiv, est basée sur les réseaux antagonistes génératifs (GAN), des modèles d'apprentissage automatique dans lesquels deux réseaux de neurones "concourent" pour faire des prédictions de plus en plus précises ou fiables.
"De nombreux travaux ont abordé le problème de l'amélioration audio et de la suppression des artefacts de compression à l'aide de techniques d'apprentissage en profondeur", ont écrit Stefan Lattner et Javier Nistal dans leur article. "Cependant, seuls quelques travaux abordent la restauration de signaux audio fortement compressés dans le domaine musical. Dans cette étude, nous testons un générateur stochastique pour une architecture de réseau antagoniste génératif (GAN) pour cette tâche."
Comme les autres GAN, le modèle créé par Lattner et Nistal est composé de deux modèles distincts, appelés « générateur (G) » et « critique (D) ». Le générateur reçoit un extrait d'un signal audio musical compressé en MP3, représenté par un spectrogramme (c'est-à-dire une représentation visuelle des fréquences du spectre d'un signal audio).
Le générateur apprend en permanence à produire une version restaurée de ce signal d'origine, dont la taille est inférieure. Pendant ce temps, le composant critique de l'architecture GAN apprend à faire la distinction entre les fichiers originaux de haute qualité et les versions restaurées, repérant ainsi les différences entre eux. En fin de compte, les informations recueillies par le critique sont utilisées pour améliorer la qualité des fichiers restaurés, en veillant à ce que la musique ou les données audio présentes dans les fichiers restaurés soient aussi fidèles que possible à celles de l'original.
Lattner et Nistal ont évalué leur architecture basée sur GAN dans une série de tests, qui visaient à déterminer si leur modèle pouvait améliorer la qualité des entrées MP3 et générer des échantillons compressés de meilleure qualité et plus proches d'un fichier original que ceux créés par d'autres modèles de base pour la compression audio. Leurs résultats étaient très prometteurs, car ils ont constaté que les restaurations du modèle de fichiers MP3 fortement compressés (16 kbit/s et 32 kbit/s) étaient généralement meilleures que les fichiers compressés d'origine, car elles sonnaient mieux pour les auditeurs humains experts. En revanche, lors de l'utilisation de taux de compression plus faibles (64 kbit/s mono), l'équipe a constaté que leur modèle obtenait des résultats légèrement inférieurs à ceux des outils de compression MP3 de base.
"Nous effectuons une évaluation approfondie des différentes expériences en utilisant des mesures objectives et des tests d'écoute", ont déclaré Lattner et Nistal. "Nous constatons que les modèles peuvent améliorer la qualité des signaux audio par rapport aux versions MP3 pour 16 et 32 kbit/s et que les générateurs stochastiques sont capables de générer des sorties plus proches des signaux d'origine que celles des générateurs déterministes."
Dans le cadre de leur étude, les chercheurs ont également montré que leur architecture pouvait générer et ajouter avec succès un contenu haute fréquence réaliste qui améliorait la qualité audio des chansons compressées. Le contenu généré comprenait des éléments de percussion, une voix chantée produisant des sifflantes ou des plosives (c'est-à-dire des sons en "s" et "t") et des sons de guitare.
À l'avenir, le modèle qu'ils ont créé pourrait aider à réduire considérablement la taille des fichiers musicaux MP3 sans altérer leur contenu ni créer d'erreurs facilement perceptibles. Cela pourrait avoir des implications importantes pour le stockage et la transmission de musique sur les applications de streaming (par exemple, Spotify, Apple Music, etc.) et les appareils électroniques modernes, y compris les smartphones, les tablettes et les ordinateurs.
© 2022 Réseau Science X Google Lyra permettra les appels vocaux pour un autre milliard d'utilisateurs