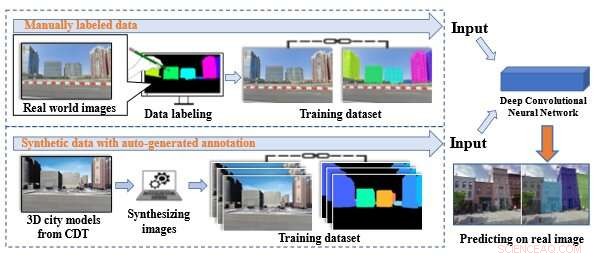
Fig. 1. Comparaison des jeux de données annotés manuellement et des jeux de données synthétiques générés automatiquement. La méthode conventionnelle nécessite que les images soient étiquetées à la main lors de la production de l'ensemble d'apprentissage, tandis que notre système proposé peut créer automatiquement des données synthétiques avec des annotations d'instance à l'aide d'actifs numériques à partir d'un jumeau numérique de la ville. Source :Journal of Computational Design and Engineering (2022). DOI :10.1093/jcde/qwac086
Les moteurs de jeu ont été développés à l'origine pour créer des mondes imaginaires pour le divertissement. Cependant, ces mêmes moteurs peuvent être utilisés pour construire des copies d'environnements réels, c'est-à-dire des jumeaux numériques. Des chercheurs de l'Université d'Osaka ont trouvé un moyen d'utiliser les images générées automatiquement par les jumelles de villes numériques pour former des modèles d'apprentissage en profondeur capables d'analyser efficacement les images de villes réelles et de séparer avec précision les bâtiments qui y apparaissent.
Un réseau neuronal convolutif est un réseau neuronal d'apprentissage en profondeur conçu pour traiter des tableaux structurés de données telles que des images. De telles avancées dans l'apprentissage en profondeur ont fondamentalement changé la façon dont les tâches, comme la segmentation architecturale, sont effectuées. Cependant, un modèle précis de réseau de neurones à convolution profonde (DCNN) nécessite un grand volume de données d'entraînement étiquetées et l'étiquetage de ces données peut être une entreprise manuelle lente et extrêmement coûteuse.
Pour créer les données numériques synthétiques des villes jumelles, les enquêteurs ont utilisé un modèle de ville 3D de la plate-forme PLATEAU, qui contient des modèles 3D de la plupart des villes japonaises à un niveau de détail extrêmement élevé. Ils ont chargé ce modèle dans le moteur de jeu Unity et créé une configuration de caméra sur une voiture virtuelle, qui a parcouru la ville et acquis les images de données virtuelles dans diverses conditions d'éclairage et météorologiques. L'API Google Maps a ensuite été utilisée pour obtenir des images réelles au niveau de la rue de la même zone d'étude pour les expériences.

Fig. 2. Modèle de ville en trois dimensions de notre zone d'étude. (a) Exemple d'un jumeau numérique de ville avec son homologue Street View dans le monde réel (Wangan-doro Avenue, Tokyo ; mars 2021 ; latitude :35,6283, longitude :139,7782). (b) Vue aérienne du jumeau numérique de la ville. Crédit :CC BY, 2022 Jiaxin Zhang et al., Génération automatique d'ensembles de données synthétiques à partir d'un jumeau numérique de la ville à utiliser dans la segmentation d'instance des façades de bâtiments, Journal of Computational Design and Engineering
Les chercheurs ont découvert que les données jumelles de la ville numérique donnent de meilleurs résultats que les données purement virtuelles sans contrepartie dans le monde réel. De plus, l'ajout de données synthétiques à un jeu de données réel améliore la précision de la segmentation. Cependant, plus important encore, les enquêteurs ont découvert que lorsqu'une certaine fraction de données réelles est incluse dans l'ensemble de données synthétiques du jumeau de la ville numérique, la précision de segmentation du DCNN est considérablement améliorée. De fait, ses performances deviennent compétitives avec celles d'un DCNN entraîné sur des données 100% réelles.
"Ces résultats révèlent que notre ensemble de données synthétiques proposé pourrait potentiellement remplacer toutes les images réelles de l'ensemble d'apprentissage", déclare Tomohiro Fukuda, l'auteur correspondant de l'article.

Fig. 3. Résultats qualitatifs pour différents types et tailles de bâtiments lorsque Mask R-CNN est formé à l'aide d'ensembles de données HSRBFIA (Hybrid Collection of Synthetic and Real-world Building Facade Images and Annotations) avec différents rapports entre données synthétiques et données réelles :(a) des maisons basses à Osaka ; (b) des maisons basses à Los Angeles; (c) des immeubles de grande hauteur à New York ; (d) façades complexes à Shanghai. (Les rectangles en pointillés rouges mettent en évidence les parties des images Street View qui étaient sujettes à l'échec lors de la segmentation de l'instance de façade.). Crédit :CC BY, 2022 Jiaxin Zhang et al., Génération automatique d'ensembles de données synthétiques à partir d'un jumeau numérique de la ville à utiliser dans la segmentation d'instance des façades de bâtiments, Journal of Computational Design and Engineering
La séparation automatique des façades de bâtiments individuelles qui apparaissent dans une image est utile pour la gestion de la construction et la conception architecturale, les mesures à grande échelle pour les rénovations et l'analyse énergétique, et même la visualisation des façades de bâtiments qui ont été démolies. Le système a été testé sur plusieurs villes, démontrant la transférabilité du cadre proposé. L'ensemble de données hybride de données réelles et synthétiques donne des résultats de prédiction prometteurs pour la plupart des styles architecturaux modernes. Cela en fait une approche prometteuse pour former les DCNN aux tâches de segmentation architecturale à l'avenir, sans avoir besoin d'une annotation manuelle coûteuse des données.
L'étude est publiée dans le Journal of Computational Design and Engineering . Un modèle d'apprentissage automatique faiblement supervisé pour extraire des caractéristiques d'images de microscopie