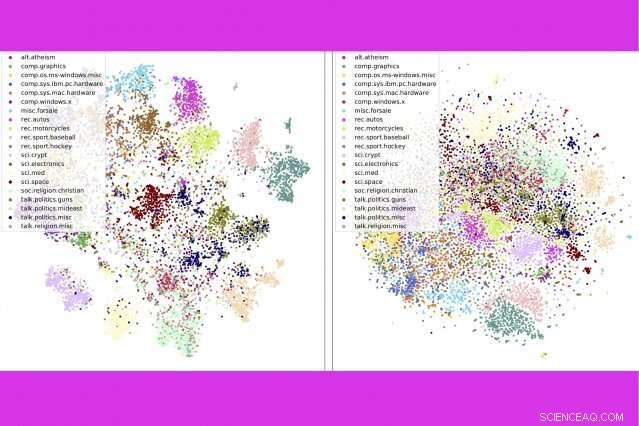
Dans une nouvelle étude, les chercheurs du MIT et d'IBM combinent trois outils d'analyse de texte populaires :la modélisation de sujets, inclusions de mots, et un transport optimal — pour comparer des milliers de documents par seconde. Ici, ils montrent que leur méthode (à gauche) regroupe les messages de groupes de discussion par catégorie plus étroitement qu'une méthode concurrente. Crédit :Massachusetts Institute of Technology
Avec des milliards de livres, des nouvelles, et documents en ligne, il n'y a jamais eu de meilleur moment pour lire, si vous avez le temps de passer au crible toutes les options. "Il y a une tonne de texte sur Internet, " dit Justin Salomon, professeur assistant au MIT. « Tout ce qui peut aider à couper tout ce matériel est extrêmement utile. »
Avec le MIT-IBM Watson AI Lab et son groupe de traitement des données géométriques au MIT, Solomon a récemment présenté une nouvelle technique pour découper des quantités massives de texte lors de la Conférence sur les systèmes de traitement de l'information neuronale (NeurIPS). Leur méthode combine trois outils d'analyse de texte populaires :la modélisation thématique, inclusions de mots, et un transport optimal - pour mieux livrer, des résultats plus rapides que les méthodes concurrentes sur une référence populaire pour la classification des documents.
Si un algorithme sait ce que vous avez aimé dans le passé, il peut analyser les millions de possibilités pour quelque chose de similaire. À mesure que les techniques de traitement du langage naturel s'améliorent, ces suggestions « vous aimerez peut-être aussi » deviennent plus rapides et plus pertinentes.
Dans la méthode présentée à NeurIPS, un algorithme résume une collection de, dire, livres, en sujets basés sur des mots couramment utilisés dans la collection. Il divise ensuite chaque livre en ses cinq à 15 sujets les plus importants, avec une estimation de la contribution globale de chaque sujet au livre.
Pour comparer des livres, les chercheurs utilisent deux autres outils :word embeddings, une technique qui transforme les mots en listes de nombres pour refléter leur similitude dans l'usage populaire, et un transport optimal, un cadre pour calculer le moyen le plus efficace de déplacer des objets (ou des points de données) entre plusieurs destinations.
Les imbrications de mots permettent d'exploiter deux fois un transport optimal :d'abord pour comparer les sujets au sein de la collection dans son ensemble, puis, dans n'importe quelle paire de livres, pour mesurer à quel point les thèmes communs se chevauchent.
La technique fonctionne particulièrement bien lors de la numérisation de grandes collections de livres et de documents volumineux. Dans l'étude, les chercheurs donnent l'exemple de "The Great War Syndicate, de Frank Stockton, " un roman américain du XIXe siècle qui anticipait la montée des armes nucléaires. Si vous cherchez un livre similaire, un modèle thématique aiderait à identifier les thèmes dominants partagés avec d'autres livres - dans ce cas, nautique, élémentaire, et martial.
Mais un modèle de sujet à lui seul n'identifierait pas la conférence de Thomas Huxley en 1863, « La condition passée de la nature organique, " comme un bon match. L'écrivain était un champion de la théorie de l'évolution de Charles Darwin, et sa conférence, parsemé de mentions de fossiles et de sédimentation, reflétait les idées émergentes sur la géologie. Lorsque les thèmes de la conférence de Huxley sont mis en correspondance avec le roman de Stockton via un transport optimal, des motifs transversaux émergent :la géographie de Huxley, flore/faune, et les thèmes de connaissances correspondent étroitement aux thèmes nautiques, élémentaire, et thèmes martiaux, respectivement.
Modéliser des livres par leurs thèmes représentatifs, plutôt que des mots individuels, permet des comparaisons de haut niveau. "Si vous demandez à quelqu'un de comparer deux livres, ils décomposent chacun en concepts faciles à comprendre, puis comparer les concepts, " dit l'auteur principal de l'étude Mikhail Yurochkin, un chercheur chez IBM.
Le résultat est plus rapide, comparaisons plus précises, l'étude montre. Les chercheurs ont comparé 1, 720 paires de livres dans l'ensemble de données du projet Gutenberg en une seconde, soit plus de 800 fois plus rapide que la meilleure méthode suivante.
La technique permet également de mieux trier les documents avec précision que les méthodes concurrentes, par exemple, regrouper les livres dans le jeu de données Gutenberg par auteur, avis produits sur Amazon par département, et les reportages sportifs de la BBC par sport. Dans une série de visualisations, les auteurs montrent que leur méthode classe soigneusement les documents par type.
En plus de catégoriser les documents plus rapidement et plus précisément, la méthode offre une fenêtre sur le processus de prise de décision du modèle. Grâce à la liste des sujets qui s'affichent, les utilisateurs peuvent voir pourquoi le modèle recommande un document.
Cette histoire est republiée avec l'aimable autorisation de MIT News (web.mit.edu/newsoffice/), un site populaire qui couvre l'actualité de la recherche du MIT, innovation et enseignement.