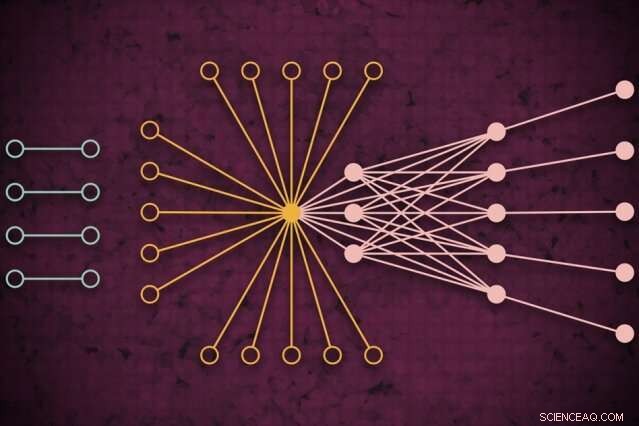
À l'aide d'un système de calcul intensif, Les chercheurs du MIT ont développé un modèle qui capture à quoi pourrait ressembler le trafic Web mondial un jour donné, y compris des liens isolés inédits (à gauche) qui se connectent rarement mais semblent avoir un impact sur le trafic Web principal (à droite). Crédit :Nouvelles du MIT
À l'aide d'un système de calcul intensif, Les chercheurs du MIT ont développé un modèle qui capture à quoi ressemble le trafic Web dans le monde un jour donné, qui peut être utilisé comme outil de mesure pour la recherche sur Internet et de nombreuses autres applications.
Comprendre les modèles de trafic Web à une si grande échelle, disent les chercheurs, est utile pour informer la politique Internet, identifier et prévenir les pannes, se défendre contre les cyberattaques, et la conception d'une infrastructure informatique plus efficace. Un article décrivant l'approche a été présenté lors de la récente conférence IEEE High Performance Extreme Computing.
Pour leur travail, les chercheurs ont rassemblé le plus grand ensemble de données de trafic Internet accessible au public, comprenant 50 milliards de paquets de données échangés dans différents endroits à travers le monde sur une période de plusieurs années.
Ils ont fait passer les données à travers un nouveau pipeline de « réseau de neurones » fonctionnant sur 10, 000 processeurs du MIT SuperCloud, un système qui combine les ressources informatiques du MIT Lincoln Laboratory et de l'ensemble de l'Institut. Ce pipeline a automatiquement formé un modèle qui capture la relation pour tous les liens de l'ensemble de données, des pings courants aux géants comme Google et Facebook, à de rares liens qui ne se connectent que brièvement mais semblent avoir un certain impact sur le trafic Web.
Le modèle peut prendre n'importe quel jeu de données réseau massif et générer des mesures statistiques sur la façon dont toutes les connexions du réseau s'affectent les unes les autres. Cela peut être utilisé pour révéler des informations sur le partage de fichiers peer-to-peer, des adresses IP malveillantes et des comportements de spam, la répartition des attaques dans les secteurs critiques, et les goulots d'étranglement du trafic pour mieux allouer les ressources informatiques et maintenir la circulation des données.
Dans la conception, le travail est similaire à la mesure du fond diffus cosmologique de l'espace, les ondes radio quasi-uniformes voyageant autour de notre univers qui ont été une source importante d'informations pour étudier les phénomènes dans l'espace extra-atmosphérique. "Nous avons construit un modèle précis pour mesurer le fond de l'univers virtuel d'Internet, " dit Jeremy Kepner, chercheur au MIT Lincoln Laboratory Supercomputing Center et astronome de formation. « Si vous souhaitez détecter des écarts ou des anomalies, vous devez avoir un bon modèle de l'arrière-plan."
Rejoindre Kepner sur le papier sont :Kenjiro Cho de l'Internet Initiative Japan; KC Claffy du Center for Applied Internet Data Analysis de l'Université de Californie à San Diego; Vijay Gadepally et Peter Michaleas du centre de calcul intensif du laboratoire Lincoln ; et Lauren Milechin, chercheur au Département de la Terre du MIT, Sciences atmosphériques et planétaires.
Diviser les données
Dans la recherche sur Internet, les experts étudient les anomalies de trafic web pouvant indiquer, par exemple, cybermenaces. Faire cela, cela aide d'abord à comprendre à quoi ressemble le trafic normal. Mais capturer cela est resté difficile. Les modèles traditionnels "d'analyse de trafic" ne peuvent analyser que de petits échantillons de paquets de données échangés entre les sources et les destinations limitées par l'emplacement. Cela réduit la précision du modèle.
Les chercheurs ne cherchaient pas spécifiquement à s'attaquer à ce problème d'analyse du trafic. Mais ils avaient développé de nouvelles techniques qui pourraient être utilisées sur le MIT SuperCloud pour traiter des matrices de réseau massives. Le trafic Internet était le cas de test parfait.
Les réseaux sont généralement étudiés sous forme de graphes, avec des acteurs représentés par des nœuds, et des liens représentant des connexions entre les nœuds. Avec le trafic Internet, les nœuds varient en taille et en emplacement. Les grands super-nœuds sont des hubs populaires, comme Google ou Facebook. Les nœuds feuilles s'étendent à partir de ce super-nœud et ont plusieurs connexions les uns aux autres et au super-nœud. Situés à l'extérieur de ce "noyau" de super-nœuds et de nœuds feuilles sont des nœuds et des liens isolés, qui ne se connectent que rarement.
Il est impossible de capturer toute l'étendue de ces graphiques pour les modèles traditionnels. "Vous ne pouvez pas toucher à ces données sans accès à un superordinateur, " dit Kepner.
En partenariat avec le projet Widely Integrated Distributed Environment (WIDE), fondée par plusieurs universités japonaises, et le Center for Applied Internet Data Analysis (CAIDA), en Californie, les chercheurs du MIT ont capturé le plus grand ensemble de données de capture de paquets au monde pour le trafic Internet. L'ensemble de données anonymisé contient près de 50 milliards de points de données source et de destination uniques entre les consommateurs et diverses applications et services pendant des jours aléatoires à divers endroits au Japon et aux États-Unis, datant de 2015.
Avant de pouvoir entraîner un modèle sur ces données, ils avaient besoin de faire un prétraitement approfondi. Faire cela, ils ont utilisé un logiciel qu'ils ont créé précédemment, appelé mode de données dimensionnelles distribuées dynamiques (D4M), qui utilise des techniques de calcul de moyenne pour calculer et trier efficacement les "données hypersparses" qui contiennent beaucoup plus d'espace vide que les points de données. Les chercheurs ont divisé les données en unités d'environ 100, 000 paquets sur 10, 000 processeurs MIT SuperCloud. Cela a généré des matrices plus compactes de milliards de lignes et de colonnes d'interactions entre les sources et les destinations.
Capturer les valeurs aberrantes
Mais la grande majorité des cellules de cet ensemble de données hyper clairsemée étaient encore vides. Pour traiter les matrices, l'équipe a exécuté un réseau de neurones sur le même 10, 000 cœurs. Dans les coulisses, une technique d'essais et d'erreurs a commencé à ajuster les modèles à l'ensemble des données, créer une distribution de probabilité de modèles potentiellement précis.
Puis, il a utilisé une technique de correction d'erreur modifiée pour affiner davantage les paramètres de chaque modèle afin de capturer autant de données que possible. Traditionnellement, les techniques de correction d'erreurs en apprentissage automatique tenteront de réduire l'importance de toutes les données aberrantes afin d'adapter le modèle à une distribution de probabilité normale, ce qui le rend globalement plus précis. Mais les chercheurs ont utilisé quelques astuces mathématiques pour s'assurer que le modèle considérait toujours toutes les données aberrantes, telles que les liens isolés, comme significatives pour les mesures globales.
À la fin, le réseau de neurones génère essentiellement un modèle simple, avec seulement deux paramètres, qui décrit l'ensemble de données de trafic Internet, "des nœuds très populaires aux nœuds isolés, et le spectre complet de tout ce qui se trouve entre les deux, " dit Kepner.
Les chercheurs contactent maintenant la communauté scientifique pour trouver leur prochaine application pour le modèle. Experts, par exemple, pourraient examiner l'importance des liens isolés que les chercheurs ont trouvés dans leurs expériences qui sont rares mais semblent avoir un impact sur le trafic Web dans les nœuds principaux.
Au-delà d'Internet, le pipeline de réseau de neurones peut être utilisé pour analyser n'importe quel réseau hypersparse, tels que les réseaux biologiques et sociaux. « Nous avons maintenant donné à la communauté scientifique un outil fantastique pour les personnes qui souhaitent construire des réseaux plus robustes ou détecter des anomalies de réseaux, " dit Kepner. "Ces anomalies peuvent être juste des comportements normaux de ce que font les utilisateurs, ou ce pourrait être des gens qui font des choses que vous ne voulez pas."
Cette histoire est republiée avec l'aimable autorisation de MIT News (web.mit.edu/newsoffice/), un site populaire qui couvre l'actualité de la recherche du MIT, innovation et enseignement.