Un algorithme ne fait que suivre des règles conçues directement ou indirectement par un humain. Crédit :Shutterstock/Milliards de photos
Le rôle des algorithmes dans nos vies augmente rapidement, de simplement suggérer des résultats de recherche en ligne ou du contenu dans notre flux de médias sociaux, à des questions plus critiques comme aider les médecins à déterminer notre risque de cancer.
Mais comment savons-nous que nous pouvons faire confiance à la décision d'un algorithme ? En juin, près de 100 conducteurs aux États-Unis ont appris à leurs dépens que les algorithmes peuvent parfois se tromper.
Google Maps les a tous coincés sur une route privée boueuse dans un détour raté pour échapper à un embouteillage en direction de l'aéroport international de Denver, dans le Colorado.
Alors que notre société devient de plus en plus dépendante des algorithmes pour le conseil et la prise de décision, il devient urgent de s'attaquer à l'épineuse question de savoir comment leur faire confiance.
Les algorithmes sont régulièrement accusés de parti pris et de discrimination. Ils ont suscité l'inquiétude des politiciens américains, au milieu des affirmations, des hommes blancs développent des algorithmes de reconnaissance faciale formés pour bien fonctionner uniquement pour les hommes blancs.
Mais les algorithmes ne sont rien de plus que des programmes informatiques prenant des décisions basées sur des règles :soit des règles que nous leur avons données, ou des règles qu'ils ont définies eux-mêmes sur la base d'exemples que nous leur avons donnés.
Dans les deux cas, les humains contrôlent ces algorithmes et leur comportement. Si un algorithme est défectueux, c'est notre fait.
Alors avant que nous ne nous retrouvions tous dans un embouteillage boueux métaphorique (ou littéral !), il est urgent de revoir la façon dont nous, les humains, choisissons de tester ces règles et de gagner la confiance dans les algorithmes.
Des algorithmes mis à l'épreuve, type de
Les humains sont des créatures naturellement méfiantes, mais la plupart d'entre nous peuvent être convaincus par des preuves.
Avec suffisamment d'exemples de test - avec des réponses correctes connues - nous développons la confiance si un algorithme donne systématiquement la bonne réponse, et pas seulement pour les exemples faciles et évidents, mais pour les défis, exemples réalistes et variés. Nous pouvons alors être convaincus que l'algorithme est impartial et fiable.
Cela semble assez facile, droit? Mais est-ce ainsi que les algorithmes sont généralement testés ? Il est plus difficile qu'il n'y paraît de s'assurer que les exemples de test sont impartiaux et représentatifs de tous les scénarios possibles qui pourraient être rencontrés.
Plus communément, des exemples de référence bien étudiés sont utilisés car ils sont facilement disponibles sur les sites Web. (Microsoft disposait d'une base de données de visages de célébrités pour tester les algorithmes de reconnaissance faciale, mais elle a récemment été supprimée en raison de problèmes de confidentialité.)
La comparaison des algorithmes est également plus facile lorsqu'elle est testée sur des benchmarks partagés, mais ces exemples de test sont rarement examinés pour leurs biais. Encore pire, les performances des algorithmes sont généralement rapportées en moyenne sur les exemples de test.
Malheureusement, savoir qu'un algorithme fonctionne bien en moyenne ne nous dit pas si nous pouvons lui faire confiance dans des cas spécifiques.
Il n'est pas surprenant de lire que les médecins sont sceptiques quant à l'algorithme de Google pour le diagnostic du cancer, qui offre une précision de 89 % en moyenne. Comment un médecin sait-il si son patient fait partie des 11% malchanceux avec un diagnostic erroné ?
Avec une demande croissante de médecine personnalisée adaptée à l'individu (pas seulement M/Mme Moyenne), et avec des moyennes connues pour cacher toutes sortes de péchés, les résultats moyens ne gagneront pas la confiance humaine.
Le besoin de nouveaux protocoles de test
Ce n'est clairement pas assez rigoureux pour tester un tas d'exemples - des benchmarks bien étudiés ou non - sans prouver qu'ils sont impartiaux, puis tirer des conclusions sur la fiabilité d'un algorithme en moyenne.
Et pourtant, paradoxalement, c'est l'approche dont dépendent les laboratoires de recherche du monde entier pour fléchir leurs muscles algorithmiques. Le processus universitaire d'examen par les pairs renforce ces procédures de test héritées et rarement remises en question.
Un nouvel algorithme est publiable s'il est meilleur en moyenne que les algorithmes existants sur des exemples de référence bien étudiés. Si ce n'est pas compétitif de cette façon, il est soit caché d'un examen plus approfondi par les pairs, ou de nouveaux exemples sont présentés pour lesquels l'algorithme semble utile.
De cette façon, un chaud, une lumière flatteuse brille sur chaque algorithme nouvellement publié, avec peu d'efforts pour tester ses forces et ses faiblesses, et lui présenter les verrues et tout. C'est la version informatique des chercheurs en médecine qui ne publient pas les résultats complets des essais cliniques.
Alors que la confiance algorithmique devient plus cruciale, nous devons de toute urgence mettre à jour cette méthodologie pour vérifier si les exemples de test choisis sont adaptés à l'objectif. Jusque là, les chercheurs ont été freinés dans une analyse plus rigoureuse par le manque d'outils adaptés.
Nous avons construit un meilleur test de résistance
Après plus d'une décennie de recherche, mon équipe a lancé un nouvel outil d'analyse d'algorithmes en ligne appelé MATILDA :Melbourne Algorithm Test Instance Library with Data Analytics.
Il aide à tester les algorithmes de manière plus rigoureuse en créant des visualisations puissantes d'un problème, montrant tous les scénarios ou exemples qu'un algorithme doit prendre en compte pour des tests complets.
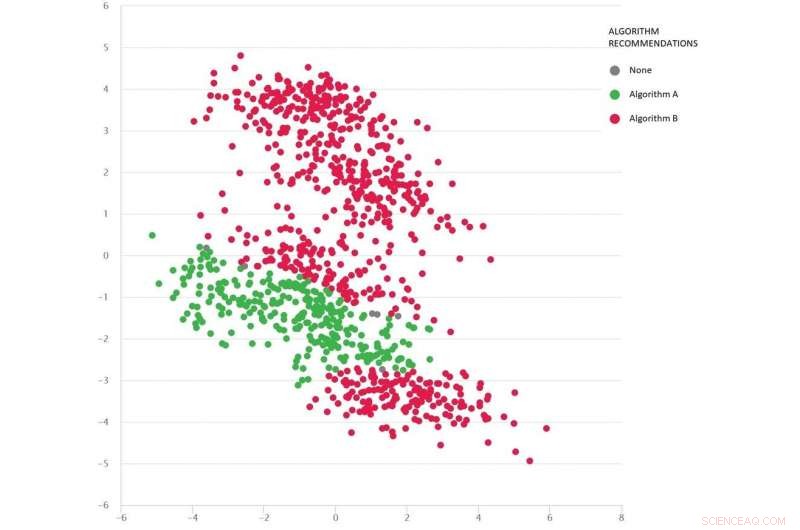
Un problème de type Google-maps avec divers scénarios de test sous forme de points :l'algorithme B (rouge) est le meilleur en moyenne, mais l'algorithme A (vert) est meilleur dans de nombreux cas. Crédit :MATILDA, Auteur fourni
MATILDA identifie les forces et faiblesses uniques de chaque algorithme, recommander lequel des algorithmes disponibles utiliser dans différents scénarios et pourquoi.
Par exemple, si la pluie récente a transformé les routes non goudronnées en boue, certains algorithmes du "chemin le plus court" peuvent ne pas être fiables à moins qu'ils ne puissent anticiper l'impact probable de la météo sur les temps de trajet lorsqu'ils conseillent l'itinéraire le plus rapide. À moins que les développeurs ne testent de tels scénarios, ils ne connaîtront jamais ces faiblesses jusqu'à ce qu'il soit trop tard et que nous soyons coincés dans la boue.
MATILDA nous aide à voir la diversité et l'exhaustivité des benchmarks, et où de nouveaux exemples de test devraient être conçus pour remplir tous les coins et recoins de l'espace possible dans lequel l'algorithme pourrait être appelé à fonctionner.
L'image ci-dessous montre un ensemble diversifié de scénarios (points) pour un problème de type Google Maps. Chaque scénario varie selon les conditions, comme les emplacements d'origine et de destination, le réseau routier disponible, conditions météorologiques, les temps de trajet sur diverses routes - et toutes ces informations sont capturées mathématiquement et résumées par les coordonnées bidimensionnelles de chaque scénario dans l'espace.
Deux algorithmes sont comparés (rouge et vert) pour voir lequel peut trouver le chemin le plus court. Chaque algorithme s'est avéré le meilleur (ou s'est avéré peu fiable) dans différentes régions en fonction de ses performances sur ces scénarios testés.
Nous pouvons également deviner quel algorithme est susceptible d'être le meilleur pour les scénarios manquants (lacunes) que nous n'avons pas encore testés.
Les mathématiques derrière MATILDA aident à créer cette visualisation, en analysant les données de fiabilité des algorithmes à partir de scénarios de test, et trouver un moyen de voir les modèles facilement.
Les idées et les explications signifient que nous pouvons choisir le meilleur algorithme pour le problème à résoudre, plutôt que de croiser les doigts et d'espérer que nous pouvons faire confiance à l'algorithme qui fonctionne le mieux en moyenne.
En testant rigoureusement les algorithmes de cette manière, les verrues et tout le reste, nous devrions réduire le risque de décisions d'algorithmes malveillants, gagner la confiance de Mr/Mme Average, et peut-être même les humains les plus sceptiques.
Cet article est republié à partir de The Conversation sous une licence Creative Commons. Lire l'article original.