Pendant des années, des chercheurs du MIT et de l'Université Brown ont développé un système interactif qui permet aux utilisateurs de glisser-déposer et de manipuler des données sur n'importe quel écran tactile, y compris les smartphones et les tableaux blancs interactifs. Maintenant, ils ont inclus un outil qui génère instantanément et automatiquement des modèles d'apprentissage automatique pour exécuter des tâches de prédiction sur ces données. Crédit :Mélanie Gonick
Dans le Homme de fer films, Tony Stark utilise un ordinateur holographique pour projeter des données 3D dans l'air, les manipuler avec ses mains, et trouver des solutions à ses problèmes de super-héros. Dans la même veine, des chercheurs du MIT et de l'Université Brown ont maintenant développé un système d'analyse de données interactive qui s'exécute sur des écrans tactiles et permet à tout le monde, pas seulement aux génies, milliardaire, Playboy philanthropes - abordez les problèmes du monde réel.
Pendant des années, les chercheurs ont développé un système interactif de science des données appelé Northstar, qui s'exécute dans le cloud mais possède une interface qui prend en charge n'importe quel appareil à écran tactile, y compris les smartphones et les grands tableaux blancs interactifs. Les utilisateurs alimentent les jeux de données système, et manipuler, combiner, et extraire des fonctionnalités sur une interface conviviale, à l'aide de leurs doigts ou d'un stylo numérique, pour découvrir les tendances et les modèles.
Dans un article présenté à la conférence ACM SIGMOD, les chercheurs détaillent un nouveau composant de Northstar, appelé VDS pour "virtual data scientist, " qui génère instantanément des modèles d'apprentissage automatique pour exécuter des tâches de prédiction sur leurs ensembles de données. Médecins, par exemple, peuvent utiliser le système pour aider à prédire quels patients sont plus susceptibles d'avoir certaines maladies, tandis que les propriétaires d'entreprise peuvent vouloir prévoir les ventes. Si vous utilisez un tableau blanc interactif, tout le monde peut également collaborer en temps réel.
L'objectif est de démocratiser la science des données en facilitant la réalisation d'analyses complexes, rapidement et avec précision.
"Même un propriétaire de café qui ne connaît pas la science des données devrait être en mesure de prédire ses ventes au cours des prochaines semaines pour déterminer la quantité de café à acheter, " déclare Tim Kraska, co-auteur et chef de projet de longue date de Northstar, professeur agrégé de génie électrique et d'informatique au Laboratoire d'informatique et d'intelligence artificielle (CSAIL) du MIT et co-directeur fondateur du nouveau Data System and AI Lab (DSAIL). « Dans les entreprises qui ont des data scientists, il y a beaucoup de va-et-vient entre data scientists et non-experts, nous pouvons donc également les rassembler dans une même pièce pour effectuer des analyses ensemble. »
VDS est basé sur une technique de plus en plus populaire en intelligence artificielle appelée apprentissage automatique automatisé (AutoML), qui permet aux personnes ayant un savoir-faire limité en science des données de former des modèles d'IA pour faire des prédictions en fonction de leurs ensembles de données. Actuellement, l'outil est en tête du concours DARPA D3M Automatic Machine Learning, qui, tous les six mois, choisit l'outil AutoML le plus performant.
Rejoindre Kraska sur le papier sont :le premier auteur Zeyuan Shang, un étudiant diplômé, et Emmanuel Zgraggen, un post-doctorant et contributeur principal de Northstar, les deux de l'EECS, CSAIL, et DSAIL; Benedetto Buratti, Yeounoh Chung, Philippe Eichmann, et Eli Upfal, tout de Brown; et Carsten Binnig qui a récemment déménagé de Brown à l'Université technique de Darmstadt en Allemagne.

Crédit :Mélanie Gonick
Un « canevas illimité » pour l'analyse
Le nouveau travail s'appuie sur des années de collaboration sur Northstar entre des chercheurs du MIT et de Brown. Sur quatre ans, les chercheurs ont publié de nombreux articles détaillant les composants de Northstar, y compris l'interface interactive, opérations sur plusieurs plateformes, accélérer les résultats, et des études sur le comportement des utilisateurs.
Northstar commence comme un blanc, interface blanche. Les utilisateurs téléchargent des ensembles de données dans le système, qui apparaissent dans une boîte "datasets" sur la gauche. Toutes les étiquettes de données rempliront automatiquement une case "attributs" distincte ci-dessous. Il y a aussi une boîte "opérateurs" qui contient divers algorithmes, ainsi que le nouvel outil AutoML. Toutes les données sont stockées et analysées dans le cloud.
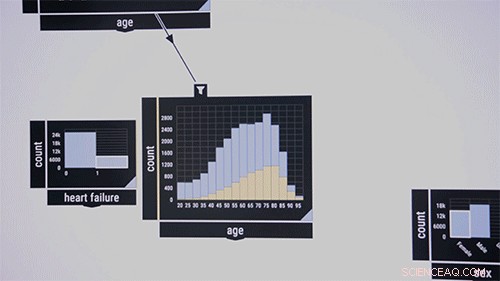
Les chercheurs aiment démontrer le système sur un ensemble de données public contenant des informations sur les patients des unités de soins intensifs. Pensez aux chercheurs en médecine qui souhaitent examiner les cooccurrences de certaines maladies dans certains groupes d'âge. Ils glissent et déposent au milieu de l'interface un algorithme de vérification de modèle, qui apparaît d'abord comme une case vide. En entrée, ils se déplacent dans la case caractéristiques de la maladie étiquetées, dire, "du sang, " "infectieux, " et "métabolique". Les pourcentages de ces maladies dans l'ensemble de données apparaissent dans la case. Ensuite, ils font glisser la fonction "âge" dans l'interface, qui affiche un graphique à barres de la répartition par âge du patient. Tracer une ligne entre les deux cases les relie entre elles. En encerclant les tranches d'âge, l'algorithme calcule immédiatement la cooccurrence des trois maladies dans la tranche d'âge.
"C'est comme un gros, toile illimitée où vous pouvez disposer comme vous voulez tout, " dit Zgraggen, qui est le principal inventeur de l'interface interactive de Northstar. "Puis, vous pouvez lier les choses ensemble pour créer des questions plus complexes sur vos données."
Approximation d'AutoML
Avec VDS, les utilisateurs peuvent désormais également exécuter des analyses prédictives sur ces données en obtenant des modèles adaptés à leurs tâches, telles que la prédiction de données, classement d'images, ou l'analyse de structures de graphes complexes.
En utilisant l'exemple ci-dessus, disent que les chercheurs en médecine veulent prédire quels patients peuvent avoir une maladie du sang en fonction de toutes les caractéristiques de l'ensemble de données. Ils font glisser et déposent "AutoML" de la liste des algorithmes. Cela produira d'abord une boîte vide, mais avec un onglet "cible", sous lequel ils laisseraient tomber la fonction "sang". Le système trouvera automatiquement les pipelines d'apprentissage automatique les plus performants, présentés sous forme d'onglets avec des pourcentages de précision constamment mis à jour. Les utilisateurs peuvent arrêter le processus à tout moment, affiner la recherche, et examiner les taux d'erreurs de chaque modèle, structure, calculs, et d'autres choses.
Crédit :Mélanie Gonick
Selon les chercheurs, VDS est l'outil AutoML interactif le plus rapide à ce jour, Merci, en partie, à leur "moteur d'estimation" personnalisé. Le moteur se situe entre l'interface et le stockage cloud. Le moteur crée automatiquement plusieurs échantillons représentatifs d'un ensemble de données qui peuvent être progressivement traités pour produire des résultats de haute qualité en quelques secondes.
"Avec mes co-auteurs, j'ai passé deux ans à concevoir VDS pour imiter la pensée d'un data scientist, " Shang dit, ce qui signifie qu'il identifie instantanément les modèles et les étapes de prétraitement qu'il doit ou ne doit pas exécuter sur certaines tâches, basé sur diverses règles codées. Il choisit d'abord parmi une grande liste de ces pipelines d'apprentissage automatique possibles et exécute des simulations sur l'ensemble d'échantillons. Ce faisant, il mémorise les résultats et affine sa sélection. Après avoir fourni des résultats approximatifs rapides, le système affine les résultats dans le back-end. Mais les chiffres finaux sont généralement très proches de la première approximation.
"Pour utiliser un prédicteur, vous ne voulez pas attendre quatre heures pour obtenir vos premiers résultats. Vous voulez déjà voir ce qui se passe et, si vous détectez une erreur, vous pouvez immédiatement le corriger. Ce n'est normalement pas possible dans un autre système, " dit Kraska. L'étude précédente des chercheurs sur les utilisateurs, En réalité, "montrez que dès que vous tardez à donner des résultats aux utilisateurs, ils commencent à perdre leur engagement avec le système."
Les chercheurs ont évalué l'outil sur 300 ensembles de données du monde réel. Par rapport à d'autres systèmes AutoML de pointe, Les approximations de VDS étaient aussi précises, mais ont été générés en quelques secondes, qui est beaucoup plus rapide que d'autres outils, qui fonctionnent en quelques minutes à quelques heures.
Prochain, the researchers are looking to add a feature that alerts users to potential data bias or errors. Par exemple, to protect patient privacy, sometimes researchers will label medical datasets with patients aged 0 (if they do not know the age) and 200 (if a patient is over 95 years old). But novices may not recognize such errors, which could completely throw off their analytics.
"If you're a new user, you may get results and think they're great, " Kraska says. "But we can warn people that there, En réalité, may be some outliers in the dataset that may indicate a problem."
Cette histoire est republiée avec l'aimable autorisation de MIT News (web.mit.edu/newsoffice/), un site populaire qui couvre l'actualité de la recherche du MIT, innovation et enseignement.