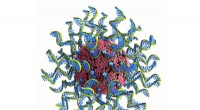
Les chercheurs du MIT ont développé un système qui glane beaucoup plus de données d'entraînement étiquetées à partir de données non étiquetées, ce qui pourrait aider les modèles d'apprentissage automatique à mieux détecter les modèles structurels dans les scintigraphies cérébrales associées aux maladies neurologiques. Le système apprend les variations structurelles et d'apparence dans les numérisations non étiquetées, et utilise ces informations pour façonner et mouler un scan étiqueté en milliers de nouveaux, scans étiquetés distincts. Crédit :Amy Zhao/MIT
Des chercheurs du MIT ont mis au point une nouvelle méthode pour glaner plus d'informations à partir d'images utilisées pour former des modèles d'apprentissage automatique, y compris ceux qui peuvent analyser les analyses médicales pour aider à diagnostiquer et à traiter les affections cérébrales.
Un nouveau domaine actif de la médecine implique la formation de modèles d'apprentissage en profondeur pour détecter des modèles structurels dans les scintigraphies cérébrales associées aux maladies et troubles neurologiques, comme la maladie d'Alzheimer et la sclérose en plaques. Mais la collecte des données d'entraînement est laborieuse :toutes les structures anatomiques de chaque scan doivent être décrites séparément ou étiquetées à la main par des experts en neurologie. Et, dans certains cas, comme pour les maladies cérébrales rares chez les enfants, seuls quelques scans peuvent être disponibles en premier lieu.
Dans un article présenté à la récente conférence sur la vision par ordinateur et la reconnaissance de formes, les chercheurs du MIT décrivent un système qui utilise un seul scan étiqueté, avec des scans non étiquetés, pour synthétiser automatiquement un ensemble de données massif d'exemples de formation distincts. L'ensemble de données peut être utilisé pour mieux former des modèles d'apprentissage automatique afin de trouver des structures anatomiques dans de nouvelles analyses :plus il y a de données d'apprentissage, meilleures sont ces prédictions.
L'essentiel du travail est de générer automatiquement des données pour le processus de "segmentation d'images", qui divise une image en régions de pixels plus significatives et plus faciles à analyser. Faire cela, le système utilise un réseau de neurones convolutifs (CNN), un modèle d'apprentissage automatique qui est devenu une centrale électrique pour les tâches de traitement d'images. Le réseau analyse un grand nombre d'analyses non étiquetées de différents patients et de différents équipements pour "apprendre" l'anatomie, luminosité, et les variations de contraste. Puis, il applique une combinaison aléatoire de ces variations apprises à un seul balayage étiqueté pour synthétiser de nouveaux balayages à la fois réalistes et étiquetés avec précision. Ces scans nouvellement synthétisés sont ensuite introduits dans un CNN différent qui apprend à segmenter de nouvelles images.
"Nous espérons que cela rendra la segmentation d'images plus accessible dans des situations réalistes où vous n'avez pas beaucoup de données d'entraînement, " dit le premier auteur Amy Zhao, un étudiant diplômé du Département de génie électrique et informatique (EECS) et du Laboratoire d'informatique et d'intelligence artificielle (CSAIL). « Dans notre approche, vous pouvez apprendre à imiter les variations des analyses non étiquetées pour synthétiser intelligemment un grand ensemble de données pour former votre réseau."
Il y a un intérêt à utiliser le système, par exemple, pour aider à former des modèles d'analyse prédictive au Massachusetts General Hospital, Zhao dit, où seulement un ou deux scans étiquetés peuvent exister de troubles cérébraux particulièrement rares chez les enfants patients.
Rejoindre Zhao sur le papier sont :Guha Balakrishnan, un post-doctorat en EECS et CSAIL; les professeurs EECS Fredo Durand et John Guttag, et auteur principal Adrian Dalca, qui est également membre du corps professoral en radiologie à la Harvard Medical School.
La "Magie" derrière le système
Bien qu'appliquée aujourd'hui à l'imagerie médicale, le système a en fait commencé comme un moyen de synthétiser des données d'entraînement pour une application pour smartphone qui pourrait identifier et récupérer des informations sur les cartes du jeu de cartes à collectionner populaire, "Magie :Le Rassemblement." Sorti au début des années 90, "Magic" en a plus de 20, 000 cartes uniques, avec d'autres sorties tous les quelques mois, que les joueurs peuvent utiliser pour créer des decks de jeu personnalisés.
Zhao, un fervent joueur de "Magic", voulait développer une application alimentée par CNN qui prenait une photo de n'importe quelle carte avec un appareil photo pour smartphone et extrayait automatiquement des informations telles que le prix et la note des bases de données de cartes en ligne. "Quand je choisissais des cartes dans un magasin de jeux, J'en avais marre d'entrer tous leurs noms dans mon téléphone et de rechercher des notes et des combos, " dit Zhao. " Ne serait-ce pas génial si je pouvais les scanner avec mon téléphone et récupérer ces informations ? "
Mais elle s'est rendu compte que c'était une tâche d'entraînement à la vision par ordinateur très difficile. "Vous auriez besoin de beaucoup de photos de tous les 20, 000 cartes, dans toutes les conditions et tous les angles d'éclairage. Personne ne va collecter cet ensemble de données, " dit Zhao.
Au lieu, Zhao a formé un CNN sur un ensemble de données plus petit d'environ 200 cartes, avec 10 photos distinctes de chaque carte, pour apprendre à déformer une carte dans différentes positions. Il a calculé un éclairage différent, angles, et des réflexions (lorsque les cartes sont placées dans des pochettes en plastique) pour synthétiser des versions déformées réalistes de n'importe quelle carte de l'ensemble de données. C'était un projet passionnant et passionnant, Zhao déclare : « Mais nous avons réalisé que cette approche était vraiment bien adaptée aux images médicales, car ce type de déformation s'adapte très bien aux IRM."
Déformation de l'esprit
Les images par résonance magnétique (IRM) sont composées de pixels tridimensionnels, appelés voxels. Lors de la segmentation des IRM, les experts séparent et étiquettent les régions de voxels en fonction de la structure anatomique les contenant. La diversité des scans, causés par des variations dans les cerveaux individuels et les équipements utilisés, pose un défi à l'utilisation de l'apprentissage automatique pour automatiser ce processus.
Certaines méthodes existantes peuvent synthétiser des exemples d'apprentissage à partir d'analyses étiquetées en utilisant « l'augmentation de données, " qui déforme les voxels étiquetés dans différentes positions. Mais ces méthodes nécessitent que des experts écrivent à la main diverses directives d'augmentation, et certains scans synthétisés ne ressemblent en rien à un cerveau humain réaliste, ce qui peut nuire au processus d'apprentissage.
Au lieu, le système des chercheurs apprend automatiquement à synthétiser des scans réalistes. Les chercheurs ont entraîné leur système sur 100 analyses non étiquetées de patients réels pour calculer des transformations spatiales, des correspondances anatomiques d'une analyse à l'autre. Cela a généré autant de « champs de flux, " qui modélise la façon dont les voxels passent d'un scan à un autre. Simultanément, il calcule les transformations d'intensité, qui capturent les variations d'apparence causées par le contraste de l'image, bruit, et d'autres facteurs.
En générant un nouveau scan, le système applique un champ de flux aléatoire au scan étiqueté d'origine, qui se déplace autour des voxels jusqu'à ce qu'il corresponde structurellement à un réel, analyse sans étiquette. Puis, il superpose une transformation d'intensité aléatoire. Finalement, le système mappe les étiquettes sur les nouvelles structures, en suivant comment les voxels se déplaçaient dans le champ de flux. À la fin, les scans synthétisés ressemblent beaucoup au réel, scans non étiquetés, mais avec des étiquettes précises.
Pour tester leur précision de segmentation automatisée, les chercheurs ont utilisé les scores de Dice, qui mesurent l'ajustement d'une forme 3D sur une autre, sur une échelle de 0 à 1. Ils ont comparé leur système aux méthodes de segmentation traditionnelles - manuelles et automatisées - sur 30 structures cérébrales différentes sur 100 scans de test. Les grandes structures étaient d'une précision comparable parmi toutes les méthodes. Mais le système des chercheurs a surpassé toutes les autres approches sur des structures plus petites, comme l'hippocampe, qui occupe seulement environ 0,6 pour cent d'un cerveau, Par volume.
"Cela montre que notre méthode s'améliore par rapport aux autres méthodes, d'autant plus que vous entrez dans les petites structures, ce qui peut être très important pour comprendre la maladie, " dit Zhao. " Et nous l'avons fait en n'ayant besoin que d'un seul scan étiqueté à la main. "
Cette histoire est republiée avec l'aimable autorisation de MIT News (web.mit.edu/newsoffice/), un site populaire qui couvre l'actualité de la recherche du MIT, innovation et enseignement.