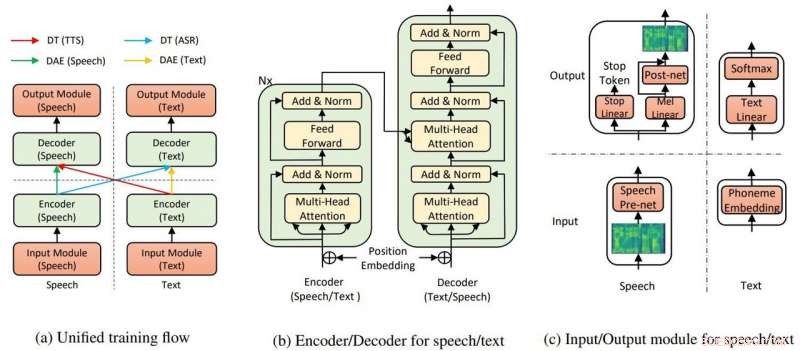
La structure globale du modèle pour TTS et ASR. Crédit :Yi Ren, Xu Tan et al.
Microsoft Research Asia s'est attiré des applaudissements pour avoir réussi à faire passer du texte à la parole nécessitant peu de formation et à montrer des résultats "incroyablement" réalistes.
Kyle Wiggers dans VentureBeat ces algorithmes de synthèse vocale n'étaient pas nouveaux et d'autres tout à fait capables mais, toujours, l'effort d'équipe chez Microsoft a toujours un avantage.
Abdallah Matloob dans Monde de l'information numérique :"La conversion texte-parole devient intelligente avec le temps, mais l'inconvénient est qu'il faudra encore une quantité excessive de temps de formation et de ressources pour créer un produit au son naturel."
À la recherche d'un moyen d'alléger le fardeau du temps et des ressources de formation pour créer un résultat qui sonne naturel, Microsoft Research et des chercheurs chinois ont découvert un autre moyen de convertir le texte en parole.
Fabienne Lang dans Ingénierie intéressante :Leur réponse s'avère être une synthèse vocale IA utilisant 200 échantillons vocaux (seulement 200) pour créer un discours réaliste correspondant aux transcriptions. Lang a dit, "Cela signifie environ 20 minutes."
Le fait que l'exigence n'était que de 200 clips audio et les transcriptions correspondantes a impressionné Wiggers dans VentureBeat . Il a également noté que les chercheurs ont conçu un système d'IA "qui tire parti de l'apprentissage non supervisé - une branche de l'apprentissage automatique qui glane des connaissances à partir de données non étiquetées, non classé, et des données de test non catégorisées."
Leur article est sur arXiv. "Text to Speech et reconnaissance vocale automatique presque non supervisés" est de Yi Ren, Xu Tan, Tao Qin, Sheng Zhao, Zhou Zhao, Tie-Yan Liu. Les affiliations des auteurs sont l'Université du Zhejiang, Microsoft Research et Microsoft Search Technology Center (STC) Asie.
Dans leur papier, l'équipe a déclaré que l'IA TTS utilise deux composants clés, un auto-encodeur à transformateur et débruitage, pour que tout fonctionne.
"Par les transformateurs, L'IA text-to-speech de Microsoft a pu reconnaître la parole ou le texte en entrée ou en sortie, " disait un article dans Nerveux par Rechelle Fuertes.
Tyler Lee dans Ubergizmo a fourni une définition de transformateur :« Les transformateurs… sont des réseaux de neurones profonds conçus pour émuler les neurones de notre cerveau. »
MathWorks avait une définition pour l'auto-encodeur. "Un auto-encodeur est un type de réseau de neurones artificiels utilisé pour apprendre des données efficaces (codages) de manière non supervisée. Le but d'un auto-encodeur est d'apprendre une représentation (codage) pour un ensemble de données, Les autoencodeurs de débruitage sont généralement un type d'autoencodeurs entraînés à ignorer le "bruit" dans les échantillons d'entrée corrompus."
Les résultats de leur expérience ont-ils montré que leur idée valait la peine d'être poursuivie ? "Notre méthode atteint 99,84% en termes de taux d'intelligibilité au niveau des mots et 2,68 MOS pour TTS, et 11,7% PER pour l'ASR [reconnaissance vocale automatique] sur le jeu de données LJSpeech, en exploitant seulement 200 données vocales et textuelles appariées (environ 20 minutes audio), ainsi que des données vocales et textuelles supplémentaires non appariées."
Pourquoi c'est important :cette approche peut rendre la synthèse vocale plus accessible, lesdits rapports.
« Les chercheurs travaillent continuellement à l'amélioration du système, et espérons qu'à l'avenir, il faudra encore moins de travail pour générer un discours réaliste, " dit Lang.
Le document sera présenté à la Conférence internationale sur l'apprentissage automatique, à Long Beach en Californie plus tard cette année, et l'équipe prévoit de publier le code dans les semaines à venir, dit Wiggers.
Pendant ce temps, les chercheurs ne s'éloignent pas encore de leur travail en présentant des transformations avec peu de données appariées.
"Dans ce travail, nous avons proposé la méthode presque non supervisée pour la synthèse vocale et la reconnaissance vocale automatique, qui n'exploite que quelques données vocales et textuelles appariées et des données supplémentaires non appariées... Pour les travaux futurs, nous repousserons les limites de l'apprentissage non supervisé en exploitant uniquement des données vocales et textuelles non appariées, avec l'aide d'autres méthodes de pré-formation."
© 2019 Réseau Science X














