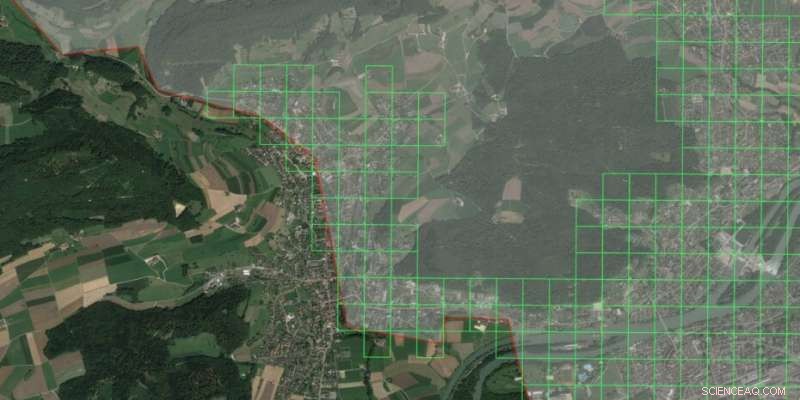
Des variables telles que l'heure de la journée, le lieu et la densité de population permettent de classer une certaine parcelle de terrain comme à risque ou non à risque de cambriolage à un moment donné. Crédit :ETH Zurich
Une nouvelle méthode d'apprentissage automatique développée par les scientifiques de l'ETH permet de prédire les cambriolages même dans les zones peu peuplées.
Les cambriolages ne se produisent pas partout tout le temps. Certaines communautés, quartiers et rues, ainsi que les saisons de l'année et les moments de la journée, ont un risque plus ou moins élevé de cambriolage. En utilisant les statistiques d'effraction, les techniques d'apprentissage automatique peuvent identifier des modèles et prédire le risque d'une effraction à un endroit spécifique. Des programmes informatiques peuvent ainsi aider la police à identifier les points chauds de cambriolage - des endroits à risque particulièrement élevé d'effraction - un jour donné, leur permettant de déployer des patrouilles en conséquence.
Le déséquilibre des classes rend l'apprentissage plus difficile
À ce jour, ces systèmes d'alerte ne fonctionnent que dans les zones densément peuplées, principalement dans les villes. C'est parce que les programmes informatiques ont besoin de suffisamment de données pour reconnaître les modèles, et la criminalité est moins fréquente dans les zones peu peuplées. C'est ce qu'on appelle un « déséquilibre de classe » dans les statistiques. Spécifiquement, cela signifie que pour chaque section de route qui a un cambriolage, il y en a plusieurs centaines voire mille qui ne le font pas.
Les algorithmes fonctionnent en parallèle
Cristina Kadar est informaticienne et doctorante au Département de Management, La technologie, et Économie. Elle a développé une méthode qui permet de faire des prévisions fiables malgré des données déséquilibrées. Ses recherches viennent d'être publiées dans la revue Decision Support Systems. Elle a testé de nombreuses méthodes d'apprentissage automatique avec un grand ensemble de données de cambriolages dans le canton suisse d'Argovie, les ont combinés et comparé les taux de réussite. Une méthode qui utilise l'apprentissage d'ensemble et combine des analyses de différents algorithmes s'est avérée la plus précise.
L'apprentissage automatique, c'est lorsqu'un algorithme utilise de grands ensembles de données pour s'entraîner à classer correctement les données. Dans cet exemple, il faut des variables telles que l'heure de la journée, endroit, densité de population et bien plus encore et apprend d'eux s'il faut classer une certaine parcelle de terrain comme à risque ou non à risque de cambriolage à un moment donné.
Le défi résidait dans la formation des algorithmes de classification malgré le petit nombre de cambriolages dans l'ensemble de données. Kadar a prétraité l'ensemble de données en supprimant au hasard les unités de données sans cambriolage jusqu'à ce qu'elle arrive au même nombre d'unités avec cambriolage que d'unités sans. Cette méthode statistique est appelée "sous-échantillonnage aléatoire". Kadar a entraîné en parallèle de nombreux algorithmes de classification avec cet ensemble de données réduit, et leurs prévisions agrégées ont produit la prévision de cambriolage. Kadar a pris des cellules de grille de 200 sur 200 mètres un jour donné comme unités de données individuelles.
Alors que les systèmes d'alerte conventionnels utilisent principalement des données de cambriolage, Kadar a également alimenté les algorithmes de classification avec des données démographiques agrégées impersonnelles, comme la densité de population, pyramide des ages, type de développement du bâtiment, infrastructures (présence d'écoles, postes de police, hôpitaux, routes), proximité des frontières nationales, ainsi que des informations temporelles incluant le jour de la semaine, vacances publiques, heures de lumière du jour et même la phase de la lune.
Taux de réussite meilleur que dans les villes
Avec la nouvelle méthode, Kadar a pu améliorer considérablement le taux de réussite par rapport aux méthodes conventionnelles. Elle a demandé à l'ordinateur d'utiliser sa méthode pour prédire les points chauds où les cambriolages étaient susceptibles de se produire dans le canton. Un examen a montré qu'environ 60% des effractions réelles ont été commises dans les points chauds prévus. Par comparaison, lorsque les hotspots ont été prédits en utilisant la méthode traditionnelle employée par la police, seulement 53 pour cent des cambriolages réels ont eu lieu dans la zone prévue. "Avec des données déséquilibrées, la méthode atteint des taux de réussite au moins aussi bons et dans certains cas meilleurs que les méthodes conventionnelles dans les zones urbaines, où les données sont plus denses et plus uniformément réparties, " dit Kadar.
Les résultats sont utiles avant tout pour la police, car la méthode peut également être utilisée pour prédire les régions et les moments avec un risque accru de cambriolage dans les zones moins densément peuplées. Cependant, il n'y a aucune raison pour que la méthode ne puisse pas être utilisée pour prédire d'autres risques :risques pour la santé, par exemple, ou la probabilité d'appels d'urgence au service d'ambulance. L'industrie immobilière pourrait également l'utiliser pour prévoir l'évolution des prix de l'immobilier sur la base de facteurs spatiaux.