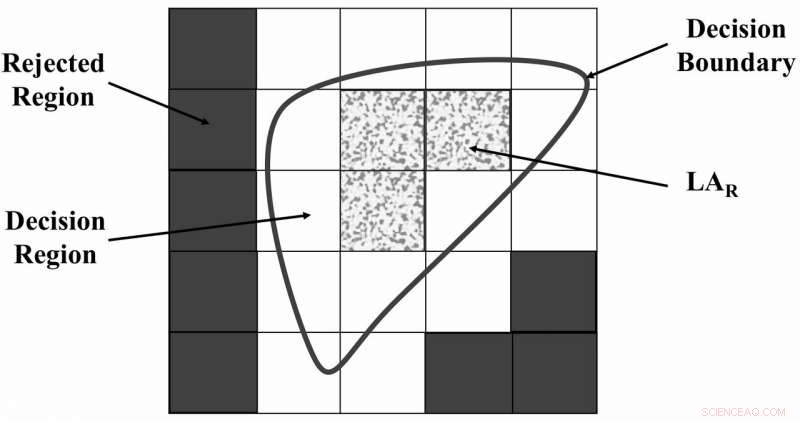
L'univers des régions discursives séparées par FRS. Crédit :Zabihimayvan &Doran.
Au cours des dernières décennies, les attaques de phishing sont devenues de plus en plus courantes. Ces attaques permettent aux attaquants d'obtenir des données utilisateur sensibles, comme les mots de passe, noms d'utilisateur, les détails de la carte de crédit, etc., en incitant les gens à divulguer des informations personnelles. Le type d'attaque de phishing le plus courant est l'escroquerie par e-mail dans laquelle les utilisateurs sont amenés à croire qu'ils doivent donner leurs coordonnées à une entité établie ou de confiance, pendant qu'ils sont, En réalité, partager ces données avec quelqu'un d'autre.
Les professionnels de l'informatique ont développé un grand nombre d'outils et de stratégies pour détecter et prévenir les attaques de phishing, dont beaucoup sont basés sur l'apprentissage automatique. Les performances de ces algorithmes d'apprentissage automatique dépendent souvent des fonctionnalités qu'ils extraient des sites Web.
Des chercheurs de la Wright State University ont récemment développé une nouvelle méthode pour identifier les meilleurs ensembles de fonctionnalités pour les algorithmes de détection des attaques de phishing. Leur approche, décrit dans un article prépublié sur arXiv, pourrait aider à améliorer les performances des algorithmes d'apprentissage automatique individuels pour découvrir les attaques de phishing.
"Les performances des algorithmes de détection de phishing qui utilisent l'apprentissage automatique dépendent fortement des fonctionnalités d'un site Web que l'algorithme prend en compte, y compris la longueur de l'URL de la page Web ou si des caractères spéciaux tels que @ et tiret existent dans l'URL, " Mahdieh Zabihimayvan et Derek Doran, les deux chercheurs qui ont mené l'étude, a dit TechXplore par e-mail. "Dans ce travail, nous voulions faciliter la création d'algorithmes d'apprentissage automatique pour la détection de phishing en récupérant automatiquement un « meilleur » ensemble de fonctionnalités pour tout algorithme de détection de phishing, quel que soit le site Web considéré."
S'il existe désormais plusieurs algorithmes pour identifier les attaques de phishing, jusque là, très peu d'études se sont concentrées sur la détermination des caractéristiques les plus efficaces pour détecter ce type particulier d'attaque. Dans leur étude, Zabihimayvan et Doran ont abordé cette lacune dans la littérature, en essayant de découvrir les fonctionnalités les plus efficaces pour cette tâche particulière.
« Nous avons appliqué la théorie du Fuzzy Rough Set (FRS) comme outil pour sélectionner les fonctionnalités les plus efficaces à partir de trois ensembles de données de sites Web de phishing comparés, " Zabihimayvan et Doran ont déclaré. " Les fonctionnalités sélectionnées sont ensuite utilisées pour trois algorithmes d'apprentissage automatique souvent utilisés pour la détection de phishing. "
Pour tester l'efficacité et la généralisation de leur approche de sélection de fonctionnalités FRS, les chercheurs l'ont utilisé pour former trois classificateurs de détection de phishing couramment utilisés sur un ensemble de données de 14, 000 échantillons de sites Web, puis évalué leurs performances. Leurs évaluations ont donné des résultats très prometteurs, atteignant une mesure F maximale de 95 % lorsque leur méthode de sélection des caractéristiques a été appliquée à un classificateur de forêt aléatoire (RM).
"FRS découvre les dépendances des fonctionnalités en fonction des données, " Zabihimayvan et Doran ont expliqué. " En d'autres termes, FRS décide comment séparer un ensemble de données en fonction de leurs valeurs de caractéristiques et de leurs étiquettes à l'aide d'une limite de décision et d'une relation de similarité déclarée sous la forme de fonctions d'appartenance floues. Les fonctionnalités sélectionnées par FRS sont celles qui permettent de mieux distinguer les échantillons de données appartenant à différentes classes. »
L'approche FRS utilisée par Zabihimayvan et Doran a sélectionné neuf caractéristiques universelles dans tous les ensembles de données utilisés dans leur étude. En utilisant cet ensemble de fonctionnalités universelles, ils ont atteint une F-mesure d'environ 93 pour cent, ce qui est similaire à celui obtenu par les classificateurs utilisant leur approche FRS. L'ensemble de fonctionnalités universel ne contient aucune fonctionnalité de services tiers, cette découverte suggère donc que l'on pourrait potentiellement détecter les attaques de phishing plus rapidement sans aucune enquête de sources externes.
« Les fonctionnalités sélectionnées automatiquement par FRS offrent les meilleures performances de détection sur un certain nombre de classificateurs, " Zabihimayvan et Doran ont déclaré. " Nous trouvons également un ensemble de 'fonctionnalités universelles' - ces aspects d'une page Web que FRS a trouvé pour mieux prédire si une page tente de pêcher des informations, quel que soit le type de site Web que la page essaie d'imiter."
L'étude menée par Zabihimayvan et Doran est l'une des premières à fournir des informations précieuses sur les fonctionnalités les plus efficaces pour détecter les attaques de phishing. À l'avenir, leurs travaux pourraient ouvrir la voie au développement de techniques de détection de phishing plus efficaces et plus fiables, qui permettrait de découvrir ces attaques plus rapidement que les méthodes actuelles.
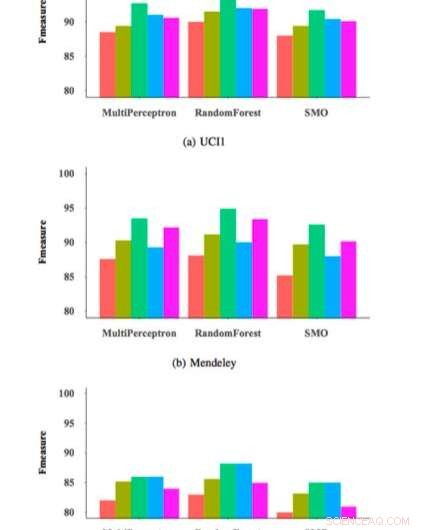
F-mesure pour différents classificateurs et ensembles de fonctionnalités. Crédit :Zabihimayvan &Doran.
"Nous espérons maintenant étendre notre étude en étudiant la sélection de fonctionnalités pour des algorithmes d'apprentissage automatique plus sophistiqués, y compris des architectures d'apprentissage en profondeur qui découvrent automatiquement des « méta-fonctionnalités » pour améliorer encore les performances de détection, " Zabihimayvan et Doran ont déclaré. " Nous prévoyons également d'étendre notre cadre de sélection de fonctionnalités pour détecter les e-mails de phishing. "
© 2019 Réseau Science X