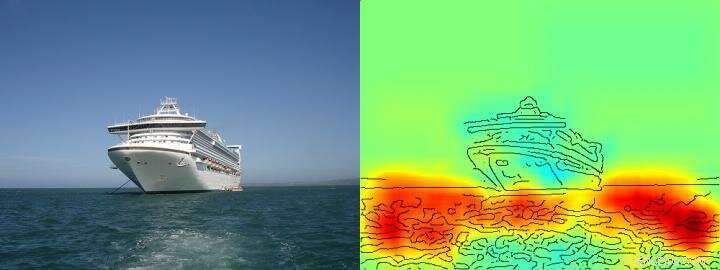
La carte thermique montre assez clairement que l'algorithme prend sa décision expédier/ne pas expédier sur la base de pixels représentant l'eau et non sur la base de pixels représentant le navire. Crédit: Communication Nature , CC PAR Lizenz
L'intelligence artificielle (IA) et les architectures d'apprentissage automatique telles que l'apprentissage en profondeur sont devenues partie intégrante de notre vie quotidienne - elles permettent des assistants vocaux numériques ou des services de traduction, améliorent les diagnostics médicaux et sont un élément indispensable des technologies futures telles que la conduite autonome. Basé sur une quantité toujours croissante de données et de nouvelles architectures informatiques puissantes, les algorithmes d'apprentissage se rapprochent apparemment des capacités humaines, parfois même les surpassant. Jusque là, cependant, les utilisateurs ignorent souvent comment exactement les systèmes d'IA parviennent à leurs conclusions. Par conséquent, il peut souvent rester difficile de savoir si le comportement de prise de décision de l'IA est vraiment intelligent ou si les procédures sont juste moyennement réussies.
Des chercheurs de la TU Berlin, L'Institut Fraunhofer Heinrich Hertz HHI et l'Université de technologie et de design de Singapour (SUTD) se sont penchés sur cette question et ont donné un aperçu du spectre "d'intelligence" diversifié observé dans les systèmes d'IA actuels, analyser spécifiquement ces systèmes d'IA avec une nouvelle technologie qui permet une analyse et une quantification automatisées.
La condition préalable la plus importante pour cette nouvelle technologie est une méthode développée précédemment par TU Berlin et Fraunhofer HHI, l'algorithme dit Layer-wise Pertinence Propagation (LRP) qui permet de visualiser en fonction de quelles variables d'entrée les systèmes d'IA prennent leurs décisions. L'extension du LRP, la nouvelle analyse de pertinence spectrale (SpRAy) peut identifier et quantifier un large éventail de comportements de prise de décision appris. De cette manière, il est désormais possible de détecter une prise de décision indésirable même dans des ensembles de données très volumineux.
Cette soi-disant « IA explicable » a été l'une des étapes les plus importantes vers une application pratique de l'IA, selon le Dr Klaus-Robert Müller, professeur d'apprentissage automatique à la TU Berlin. "En particulier dans le diagnostic médical ou dans les systèmes critiques pour la sécurité, aucun système d'IA qui utilise des stratégies de résolution de problèmes floconneuses ou même trompeuses ne devrait être utilisé."
En utilisant leurs algorithmes nouvellement développés, les chercheurs sont enfin en mesure de tester n'importe quel système d'IA existant et d'en déduire des informations quantitatives :tout un spectre à partir d'un comportement naïf de résolution de problèmes, des stratégies de tricherie jusqu'à des solutions stratégiques "intelligentes" très élaborées est observée.
Dr Wojciech Samek, Le chef de groupe chez Fraunhofer HHI a déclaré :« Nous avons été très surpris par le large éventail de stratégies de résolution de problèmes apprises. Même les systèmes d'IA modernes n'ont pas toujours trouvé une solution qui semble significative d'un point de vue humain, mais utilisait parfois ce que l'on appelle les stratégies intelligentes de Hans. »
Clever Hans était un cheval censé compter et était considéré comme une sensation scientifique dans les années 1900. Comme on l'a découvert plus tard, Hans ne maîtrisait pas les mathématiques, mais dans environ 90 pour cent des cas, il a pu déduire la bonne réponse de la réaction du questionneur.
L'équipe autour de Klaus-Robert Müller et Wojciech Samek a également découvert des stratégies "Clever Hans" similaires dans divers systèmes d'IA. Par exemple, un système d'IA qui a remporté plusieurs concours internationaux de classification d'images il y a quelques années a poursuivi une stratégie qui peut être considérée comme naïve d'un point de vue humain. Il classait les images principalement sur la base du contexte. Les images ont été attribuées à la catégorie "navire" lorsqu'il y avait beaucoup d'eau dans l'image. D'autres images ont été classées comme "train" si des rails étaient présents. D'autres images ont été attribuées à la catégorie correcte par leur filigrane de copyright. La vraie tâche, à savoir détecter les concepts de navires ou de trains, n'a donc pas été résolu par ce système d'IA, même s'il a en effet classé correctement la majorité des images.
Les chercheurs ont également pu trouver ces types de stratégies de résolution de problèmes défectueuses dans certains des algorithmes d'IA de pointe, les soi-disant réseaux de neurones profonds – des algorithmes qui avaient été considérés comme immunisés contre de telles défaillances. Ces réseaux ont basé leurs décisions de classification en partie sur des artefacts créés lors de la préparation des images et n'ont rien à voir avec le contenu réel de l'image.
"De tels systèmes d'IA ne sont pas utiles dans la pratique. Leur utilisation dans le diagnostic médical ou dans des zones critiques pour la sécurité entraînerait même d'énormes dangers, " a déclaré Klaus-Robert Müller. " Il est tout à fait concevable qu'environ la moitié des systèmes d'IA actuellement utilisés reposent implicitement ou explicitement sur de telles stratégies Clever Hans. Il est temps de vérifier systématiquement cela afin que des systèmes d'IA sécurisés puissent être développés."
Avec leur nouvelle technologie, les chercheurs ont également identifié des systèmes d'IA qui ont appris de manière inattendue des stratégies "intelligentes". Les exemples incluent les systèmes qui ont appris à jouer aux jeux Atari Breakout et Pinball. "Ici, l'IA a bien compris le concept du jeu, et trouvé un moyen intelligent de collecter beaucoup de points de manière ciblée et à faible risque. Le système intervient même parfois d'une manière qu'un vrai joueur ne ferait pas, ", a déclaré Wojciech Samek.
"Au-delà de la compréhension des stratégies d'IA, notre travail établit l'utilisabilité de l'IA explicable pour la conception itérative d'ensembles de données, à savoir pour supprimer des artefacts dans un ensemble de données qui amèneraient une IA à apprendre des stratégies erronées, ainsi que d'aider à décider quels exemples non étiquetés doivent être annotés et ajoutés afin que les défaillances d'un système d'IA puissent être réduites, " a déclaré le professeur adjoint SUTD Alexander Binder.
"Notre technologie automatisée est open source et accessible à tous les scientifiques. Nous considérons notre travail comme une première étape importante pour rendre les systèmes d'IA plus robustes, explicable et sécurisé à l'avenir, et d'autres devront suivre. Il s'agit d'un préalable indispensable à l'utilisation généralisée de l'IA, " a déclaré Klaus-Robert Müller.














