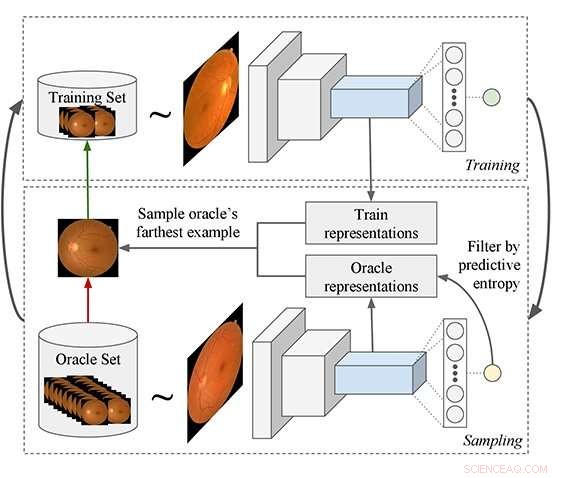
Pipeline d'apprentissage actif proposé :le processus commence par l'apprentissage d'un modèle et son utilisation pour interroger des exemples à partir d'un ensemble de données sans étiquette qui sont ensuite ajoutés à l'ensemble d'apprentissage. Une nouvelle fonction de requête est proposée, mieux adaptée aux modèles d'apprentissage profond (DL). Le modèle DL est utilisé pour extraire des caractéristiques des exemples d'oracle et d'ensemble d'apprentissage, puis l'algorithme filtre les exemples d'oracle qui ont une faible entropie prédictive. Finalement, l'exemple d'oracle sélectionné est en moyenne le plus éloigné dans l'espace des fonctionnalités de tous les exemples d'apprentissage. Crédit :Asim Smailagic
À mesure que les systèmes d'intelligence artificielle apprennent à mieux reconnaître et classer les images, ils deviennent de plus en plus fiables pour diagnostiquer les maladies, comme le cancer de la peau, à partir d'images médicales. Mais aussi bons qu'ils soient pour détecter les modèles, L'IA ne remplacera pas votre médecin de sitôt. Même lorsqu'il est utilisé comme un outil, les systèmes de reconnaissance d'images nécessitent toujours un expert pour étiqueter les données, et beaucoup de données en plus :il a besoin d'images à la fois de patients en bonne santé et de patients malades. L'algorithme trouve des modèles dans les données d'entraînement et lorsqu'il reçoit de nouvelles données, il utilise ce qu'il a appris pour identifier la nouvelle image.
L'un des défis est qu'il est long et coûteux pour un expert d'obtenir et d'étiqueter chaque image. Pour résoudre ce problème, un groupe de chercheurs du Collège d'ingénierie de l'Université Carnegie Mellon, dont les professeurs Hae Young Noh et Asim Smailagic, se sont associés pour développer une technique d'apprentissage actif qui utilise un ensemble de données limité pour atteindre un haut degré de précision dans le diagnostic de maladies comme la rétinopathie diabétique ou le cancer de la peau.
Le modèle des chercheurs commence à travailler avec un ensemble d'images non étiquetées. Le modèle décide du nombre d'images à étiqueter pour disposer d'un ensemble de données d'apprentissage robuste et précis. Il choisit un ensemble initial de données aléatoires à étiqueter. Une fois ces données étiquetées, il trace ces données sur une distribution car les images varient selon l'âge, genre, propriété physique, etc. Afin de prendre une bonne décision sur la base de ces données, les échantillons doivent couvrir un grand espace de distribution. Le système décide alors quelles nouvelles données doivent être ajoutées à l'ensemble de données, compte tenu de la distribution actuelle des données.
"Le système mesure à quel point cette distribution est optimale, " dit Non, professeur agrégé de génie civil et environnemental, "et calcule ensuite les métriques lorsqu'un certain ensemble de nouvelles données y est ajouté, et sélectionne le nouvel ensemble de données qui maximise son optimalité."
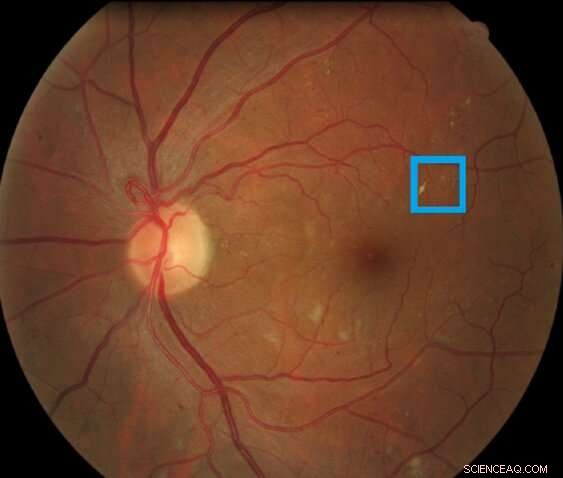
Image d'une rétine contenant une lésion rétinienne associée à une rétinopathie diabétique mise en évidence dans l'encadré. Ce type de lésion est appelé microanévrisme. Crédit :Asim Smailagic
Le processus est répété jusqu'à ce que l'ensemble de données ait une distribution suffisamment bonne pour être utilisé comme ensemble d'apprentissage. Leur méthode, appelé MedAL (pour l'apprentissage actif médical), atteint une précision de 80 % sur la détection de la rétinopathie diabétique, en utilisant seulement 425 images étiquetées, ce qui représente une réduction de 32 % du nombre d'exemples étiquetés requis par rapport à la technique d'échantillonnage à incertitude standard, et une réduction de 40 % par rapport à l'échantillonnage aléatoire.
Ils ont également testé le modèle sur d'autres maladies, y compris les images du cancer de la peau et du cancer du sein, pour montrer qu'il pourrait s'appliquer à une variété d'images médicales différentes. La méthode est généralisable, car son objectif est de savoir comment utiliser les données de manière stratégique plutôt que d'essayer de trouver un modèle ou une caractéristique spécifique pour une maladie. Il pourrait également être appliqué à d'autres problèmes qui utilisent l'apprentissage en profondeur mais ont des contraintes de données.
"Notre approche d'apprentissage actif combine un échantillonnage d'incertitude prédictif basé sur l'entropie et une fonction de distance sur un espace de caractéristiques apprises pour optimiser la sélection d'échantillons non étiquetés, " dit Smailagic, professeur-chercheur à l'accélérateur de recherche en ingénierie de Carnegie Mellon. "La méthode surmonte les limites des approches traditionnelles en sélectionnant efficacement uniquement les images qui fournissent le plus d'informations sur la distribution globale des données, réduisant les coûts de calcul et augmentant à la fois la vitesse et la précision."
L'équipe comprenait un doctorat en génie civil et environnemental. étudiants Mostafa Mirshekari, Jonathan Fagert, et Susu Xu, et les étudiants en maîtrise en génie électrique et informatique Devesh Walawalkar et Kartik Khandelwal. Ils ont présenté leurs conclusions à la conférence internationale IEEE 2018 sur l'apprentissage automatique et les applications en décembre, où ils ont reçu un Best Paper Award pour leur roman.