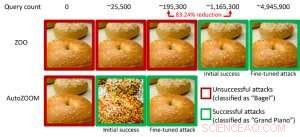
Figure 1 : Comparaison des performances pour transformer une image de bagel en une image de bagel conflictuelle classée comme un « piano à queue » à l'aide des attaques ZOO et AutoZOOM. Crédit :IBM
Des études récentes ont identifié le manque de robustesse des modèles d'IA actuels par rapport à des exemples contradictoires - des entrées de données évasives aux prédictions manipulées intentionnellement qui sont similaires aux données normales, mais qui entraîneront un mauvais comportement des modèles d'IA bien entraînés. Par exemple, des perturbations visuellement imperceptibles d'un panneau d'arrêt peuvent être facilement conçues et conduire un modèle d'IA de haute précision vers une mauvaise classification. Dans notre précédent article publié à la Conférence européenne sur la vision par ordinateur (ECCV) en 2018, nous avons validé que 18 modèles de classification différents formés sur ImageNet, un grand ensemble de données de reconnaissance d'objets publics, sont tous vulnérables aux perturbations accusatoires.
Notamment, les exemples contradictoires sont souvent générés dans le cadre de la « boîte blanche », où le modèle d'IA est entièrement transparent pour un adversaire. Dans le scénario pratique, lors du déploiement d'un modèle d'IA auto-formé en tant que service, comme une API de classification d'images en ligne, on peut croire à tort qu'il est robuste aux exemples contradictoires en raison d'un accès et d'une connaissance limités du modèle d'IA sous-jacent (alias le paramètre "boîte noire"). Cependant, nos travaux récents publiés à l'AAAI 2019 montrent que la robustesse due à l'accès limité au modèle n'est pas fondée. Nous fournissons un cadre général pour générer des exemples contradictoires à partir du modèle d'IA ciblé en utilisant uniquement les réponses d'entrée-sortie du modèle et quelques requêtes de modèle. Par rapport au travail précédent (attaque ZOO), notre cadre proposé, appelé AutoZOOM, réduit au moins 93 % des requêtes de modèle en moyenne tout en atteignant des performances d'attaque similaires, fournir une méthodologie efficace pour les requêtes pour évaluer la robustesse contradictoire des systèmes d'IA avec un accès limité. Un exemple illustratif est montré dans la figure 1, où une image de bagel contradictoire générée à partir d'un classificateur d'images de type boîte noire sera classée comme cible de l'attaque « piano à queue ». Cet article est sélectionné pour une présentation orale (29 janvier, 11h30-12h30 @ coral 1) et présentation du poster (29 janvier, 18h30-20h30) à l'AAAI 2019.
Dans le cadre de la boîte blanche, les exemples accusatoires sont souvent élaborés en tirant parti du gradient d'un objectif d'attaque conçu par rapport aux données d'entrée pour guider la perturbation accusatoire, ce qui nécessite de connaître l'architecture du modèle ainsi que les poids du modèle pour l'inférence. Cependant, dans le cadre de la boîte noire, l'acquisition du gradient est impossible en raison de l'accès limité à ces détails du modèle. Au lieu, un adversaire ne peut accéder qu'aux réponses d'entrée-sortie du modèle d'IA déployé, tout comme les utilisateurs réguliers (par exemple, télécharger une image et recevoir la prédiction d'une API de classification d'images en ligne). Il a été montré pour la première fois dans l'attaque ZOO qu'il est possible de générer des exemples contradictoires à partir de modèles avec un accès limité en utilisant des techniques d'estimation de gradient. Cependant, cela peut prendre une énorme quantité de requêtes de modèle pour créer un exemple contradictoire. Par exemple, dans la figure 1, L'attaque ZOO nécessite plus d'un million de requêtes de modèle pour trouver l'image contradictoire du bagel. Pour accélérer l'efficacité des requêtes dans la recherche d'exemples contradictoires dans le cadre de la boîte noire, notre cadre AutoZOOM proposé comporte deux nouveaux blocs de construction :(i) une stratégie d'estimation de gradient aléatoire adaptative pour équilibrer le nombre de requêtes et la distorsion, et (ii) un auto-encodeur qui est soit entraîné hors ligne avec des données non étiquetées, soit une opération de redimensionnement bilinéaire pour l'accélération. Pour (i), AutoZOOM dispose d'un estimateur de gradient optimisé et efficace pour les requêtes, qui a un schéma adaptatif qui utilise peu de requêtes pour trouver la première perturbation contradictoire réussie, puis utilise plus de requêtes pour affiner la distorsion et rendre l'exemple contradictoire plus réaliste. Pour (ii), comme le montre la figure 2, AutoZOOM implémente une technique appelée "réduction de dimension" pour réduire la complexité de la recherche d'exemples contradictoires. La réduction de dimension peut être réalisée par un auto-encodeur formé hors ligne pour capturer les caractéristiques des données ou un simple redimensionneur d'image bilinéaire qui ne nécessite aucune formation.
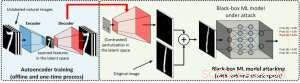
Figure 2 :Illustration de la technique de réduction de dimension utilisée dans AutoZOOM pour les échanges de requêtes. Le décodeur peut être soit un autoencodeur formé hors ligne, soit une opération de redimensionnement bilinéaire qui ne nécessite aucune formation. Crédit :IBM
Avec ces deux techniques de base, nos expériences sur les classificateurs d'images basés sur des réseaux de neurones profonds à boîte noire entraînés sur MNIST, CIFAR-10 et ImageNet montrent qu'AutoZOOM atteint des performances d'attaque similaires tout en réalisant une réduction significative (au moins 93%) du nombre moyen de requêtes par rapport à l'attaque ZOO. Sur ImageNet, cette réduction drastique signifie des millions de requêtes de modèle en moins, faire d'AutoZOOM un outil efficace et pratique pour évaluer la robustesse contradictoire des modèles d'IA avec un accès limité. De plus, AutoZOOM est un accélérateur d'échange de requêtes général qui peut facilement s'appliquer à différentes méthodes pour générer des exemples contradictoires dans le cadre pratique de la boîte noire.
Le code AutoZOOM est open source et peut être trouvé ici. Veuillez également consulter l'Adversarial Robustness Toolbox d'IBM pour plus d'implémentations sur les attaques et les défenses contradictoires.
Cette histoire est republiée avec l'aimable autorisation d'IBM Research. Lisez l'histoire originale ici.