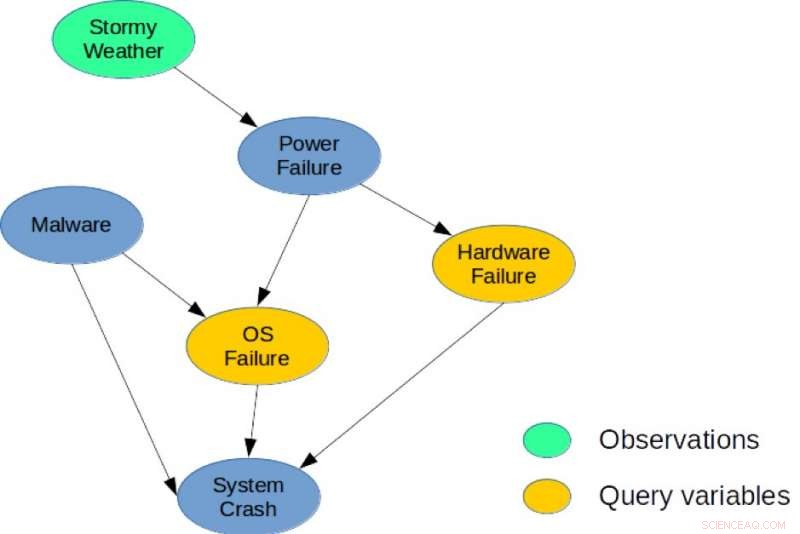
Figure 1. Un réseau bayésien simple pour une tâche de diagnostic du système. Crédit :IBM
Il existe un lien profond entre la planification et l'inférence, et au cours de la dernière décennie, plusieurs chercheurs ont introduit des réductions explicites montrant comment la planification stochastique peut être résolue en utilisant l'inférence probabiliste avec des applications en robotique, Planification, et les problèmes environnementaux. Cependant, Les méthodes heuristiques et la recherche restent les approches les plus performantes pour la planification dans de grands espaces combinatoires d'états et d'actions. Mes co-auteurs et moi adoptons une nouvelle approche dans notre article, « De la planification stochastique à la MAP marginale » (auteurs :Hao Cui, Radu Marinescu, Roni Khadon), à la conférence 2018 sur les systèmes de traitement de l'information neuronale (NeurIPS) en montrant comment les idées de la planification peuvent être utilisées pour l'inférence.
Nous avons développé le Solver Algebraic Gradient Based (AGS), un nouveau solveur pour l'inférence MAP marginale approximative. L'algorithme construit un graphe de calcul algébrique approximatif capturant les marges des variables d'état et de récompense sous des hypothèses d'indépendance. Il utilise ensuite la différenciation automatique et la recherche par gradient pour optimiser le choix d'action. Notre analyse montre que la valeur calculée par le graphe de calcul AGS est identique à la solution de la propagation des croyances (BP) lorsqu'elle est conditionnée aux actions. Cela fournit un lien explicite entre les algorithmes de planification heuristique et l'inférence approximative.
Plus précisement, nous revisitons le lien entre la planification stochastique et l'inférence probabiliste. Nous proposons pour la première fois d'utiliser un algorithme heuristique efficace qui a été conçu à l'origine pour résoudre des problèmes de planification afin d'aborder une tâche d'inférence centrale pour les modèles graphiques probabilistes, à savoir la tâche de probabilité marginale maximale a posteriori (MMAP).
Les modèles graphiques probabilistes tels que les réseaux bayésiens ou les réseaux de Markov fournissent un cadre très puissant pour raisonner sur les structures de dépendances conditionnelles sur de nombreuses variables. Pour de tels modèles, la requête d'inférence MMAP est une tâche particulièrement difficile mais importante, correspondant à trouver la configuration la plus probable (ou maximiser la probabilité) sur un sous-ensemble de variables, appelées variables MAP, après avoir marginalisé (ou additionné) le reste du modèle.
L'inférence MMAP survient dans de nombreuses situations, notamment dans les tâches de diagnostic et de planification, dans laquelle la spécification la plus naturelle du modèle contient de nombreuses variables dont on ne se soucie pas de prédire les valeurs, mais qui créent une interdépendance entre les variables d'intérêt. Par exemple, dans une tâche de diagnostic basée sur un modèle, donné des observations, nous cherchons à optimiser sur un sous-ensemble de variables de diagnostic représentant des composants potentiellement défaillants dans un système.
Pour illustration, considérons le réseau bayésien illustré à la figure 1, qui décrit un problème de diagnostic simple pour un système informatique. Le modèle capture les dépendances causales directes entre six variables aléatoires utilisées pour décrire ce problème. Spécifiquement, un plantage du système peut être causé par une panne matérielle, une défaillance du système d'exploitation, ou la présence de Malware dans le système. De la même manière, une panne de courant peut être une cause fréquente de panne du matériel et du système d'exploitation, et le temps orageux peut provoquer une panne de courant. Une requête MMAP possible serait de calculer la configuration la plus probable des pannes matérielles et du système d'exploitation, étant donné que nous observons le temps orageux, quel que soit l'état des autres variables (Malware, Crash du système, ou panne de courant).
Les cadres de planification stochastiques tels que les processus de décision de Markov sont largement utilisés pour modéliser et résoudre des tâches de planification dans des conditions d'incertitude. La planification à horizon fini peut être capturée à l'aide d'un réseau bayésien dynamique (DBN) où les variables d'état et d'action à chaque pas de temps sont représentées explicitement et les distributions de probabilité conditionnelles des variables sont données par les probabilités de transition. Dans la planification hors ligne, la tâche consiste à calculer une politique qui optimise la récompense à long terme. En revanche, dans la planification en ligne, nous recevons un temps limité fixe t par étape et ne pouvons pas calculer une politique à l'avance. Au lieu, étant donné l'état actuel, l'algorithme doit décider de la prochaine action dans le temps t. Ensuite, l'action est effectuée, une transition et une récompense sont observées et l'algorithme est présenté avec l'état suivant. Ce processus se répète et les performances à long terme de l'algorithme sont évaluées.
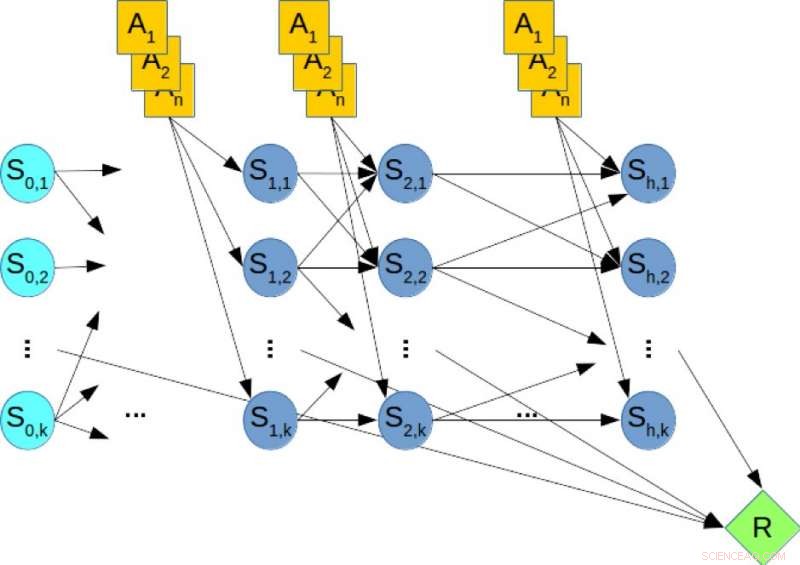
Figure 2. Un réseau bayésien dynamique (DBN) pour la planification stochastique. Crédit :IBM
Pour illustration, considérer la figure 2, qui montre le DBN correspondant à un problème de planification hypothétique, où les nœuds oranges représentent les variables d'action, les nœuds bleus désignent les variables d'état, et le nœud vert désigne la récompense cumulative qui doit être maximisée. Par conséquent, calculer la politique optimale du problème de planification équivaut à résoudre une requête MMAP sur le DBN, où nous maximisons les variables d'action et marginalisons les variables d'état.
Notre évaluation expérimentale d'instances de problèmes MMAP difficiles montre de manière concluante que le schéma AGS s'améliore par rapport aux performances à tout moment des algorithmes de pointe sur les problèmes MMAP avec des sous-problèmes de sommation dure, parfois jusqu'à un ordre de grandeur. Nous pensons que ces liens entre la planification et l'inférence peuvent être explorés plus avant pour apporter des améliorations dans les deux domaines.
Cette histoire est republiée avec l'aimable autorisation d'IBM Research. Lisez l'histoire originale ici.