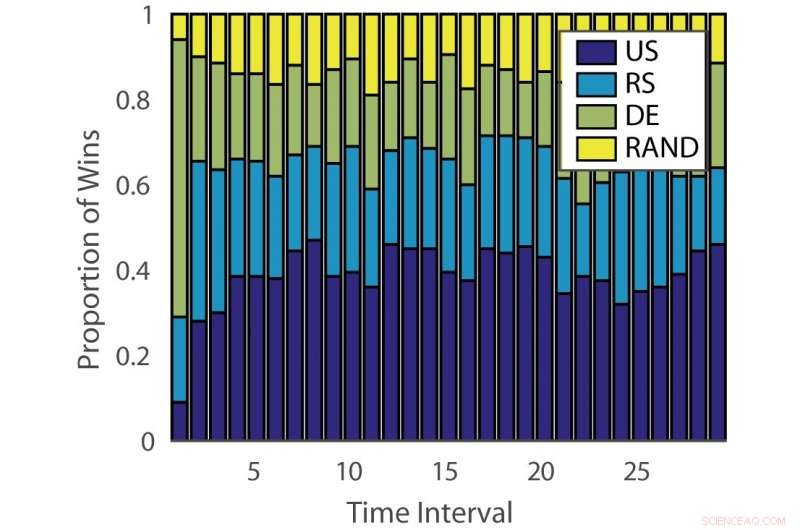
Proportion de victoires :« ILPD ». Crédit :Pang et al.
Chercheurs de l'Université d'Édimbourg, L'University College London (UCL) et le Nara Institute of Science and Technology ont développé une nouvelle approche d'apprentissage actif d'ensemble basée sur un bandit multi-bras non stationnaire et un algorithme de conseil d'experts. Leur méthode, présenté dans un article pré-publié sur arXiv, pourrait réduire le temps et les efforts investis dans l'annotation manuelle des données.
"L'apprentissage automatique supervisé conventionnel est gourmand en données, et les données étiquetées peuvent être un goulot d'étranglement lorsque l'annotation des données est coûteuse, " Timothée Hospedales, l'un des chercheurs qui a mené l'étude a déclaré à Tech Xplore. "L'apprentissage actif prend en charge l'apprentissage supervisé en prédisant les points de données les plus informatifs à annoter afin que de bons modèles puissent être entraînés avec un budget d'annotation réduit."
L'apprentissage actif est un domaine particulier de l'apprentissage automatique dans lequel un algorithme d'apprentissage peut choisir activement les données à partir desquelles il souhaite apprendre. Cela se traduit généralement par de meilleures performances, avec des ensembles de données d'entraînement beaucoup plus petits.
Les chercheurs ont développé une variété d'algorithmes d'apprentissage actif qui pourraient réduire les coûts d'annotation, mais si loin, aucune de ces solutions ne s'est avérée efficace pour tous les problèmes. D'autres études ont donc utilisé des algorithmes de bandit pour identifier le meilleur algorithme d'apprentissage actif pour un ensemble de données donné.
"Le terme 'bandit' fait référence à une machine à sous bandit à plusieurs bras, qui est une abstraction mathématique pratique pour les problèmes d'exploration/exploitation, " a expliqué Hospedales. " Un algorithme de bandit trouve un bon équilibre entre les efforts consacrés à l'exploration de toutes les machines à sous pour savoir laquelle est la plus payante, avec des efforts consacrés à l'exploitation de la meilleure machine à sous trouvée jusqu'à présent."
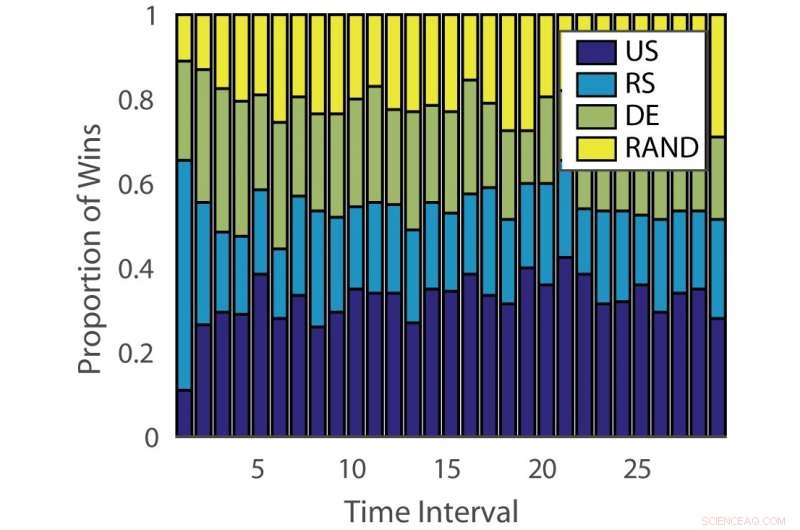
Proportion de victoires :« allemand ». Crédit :Pang et al.
L'efficacité des algorithmes d'apprentissage actif varie à la fois selon les problèmes et dans le temps à différentes étapes de l'apprentissage. Cette observation est analogue à jouer aux machines à sous, où la probabilité de paiement change au fil du temps.
"Le but de notre étude était de développer un nouvel algorithme de bandit qui améliore les performances en tenant compte de cet aspect du problème d'apprentissage actif, ", a déclaré Hospedales.
Pour faire face à cette limitation, les chercheurs ont proposé un apprenant actif d'ensemble dynamique (DEAL) basé sur un bandit non stationnaire. Cet apprenant construit en ligne une estimation de l'efficacité de chaque algorithme d'apprentissage actif, sur la base de la récompense (précision pondérée par l'importance) obtenue après chaque annotation de données.
"Il le fait en utilisant la préférence exprimée pour ce point par chaque algorithme d'apprentissage actif, " Kunkun Pang, un autre chercheur qui a mené l'étude, a déclaré Tech Xplore. « Pour faire face à la question de l'évolution de l'efficacité des apprenants actifs au fil du temps, nous redémarrons périodiquement l'algorithme d'apprentissage pour actualiser sa préférence d'apprenant actif. Avec cette capacité, si l'algorithme d'apprentissage actif le plus efficace change entre les premiers et derniers stades de l'apprentissage, nous pouvons nous adapter rapidement à ce changement."
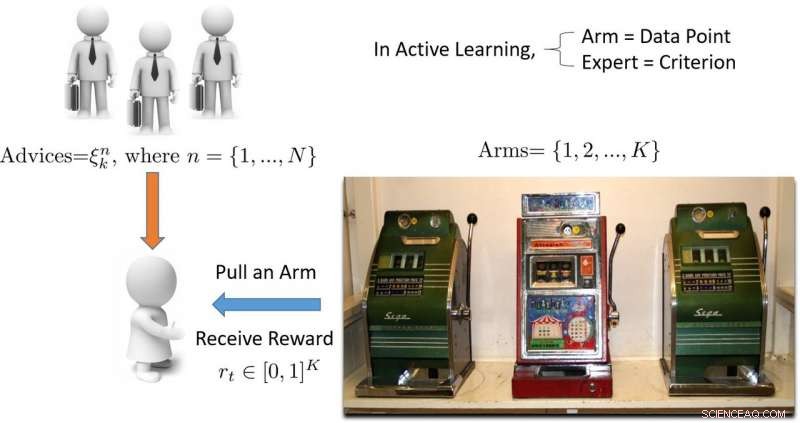
Illustration d'une approche d'apprentissage actif basée sur des bandits armés. Crédit :Pang et al.
Les chercheurs ont testé leur approche sur 13 ensembles de données populaires, obtenir des résultats très encourageants. Leur algorithme DEAL a une garantie de performance mathématique, ce qui signifie qu'il existe un degré élevé de confiance dans son bon fonctionnement.
"La garantie concerne les performances de notre algorithme, qui est celui d'un oracle idéal qui connaît toujours le bon choix pour l'apprenant actif, " Hospedales a expliqué. " Il fournit une limite sur l'écart de performance entre un tel algorithme du meilleur des cas et le nôtre. "
L'évaluation empirique réalisée par Hospedales et ses collègues a confirmé que leur algorithme DEAL améliore les performances d'apprentissage actif sur une série de références. Pour ce faire, il identifie en permanence l'algorithme d'apprentissage actif le plus efficace pour différentes tâches et à différentes étapes de la formation.
"Aujourd'hui, tandis que l'apprentissage actif est attrayant, son impact sur les pratiques d'apprentissage automatique est limité en raison de la difficulté de faire correspondre les algorithmes aux problèmes et aux étapes d'apprentissage, " Hospedales a déclaré. "DEAL élimine cette difficulté et fournit une approche pour s'attaquer à de nombreux problèmes et à toutes les étapes de l'apprentissage. En facilitant l'utilisation de l'apprentissage actif, nous espérons que cela pourra avoir un impact plus important sur la réduction des coûts d'annotation dans la pratique de l'apprentissage automatique."
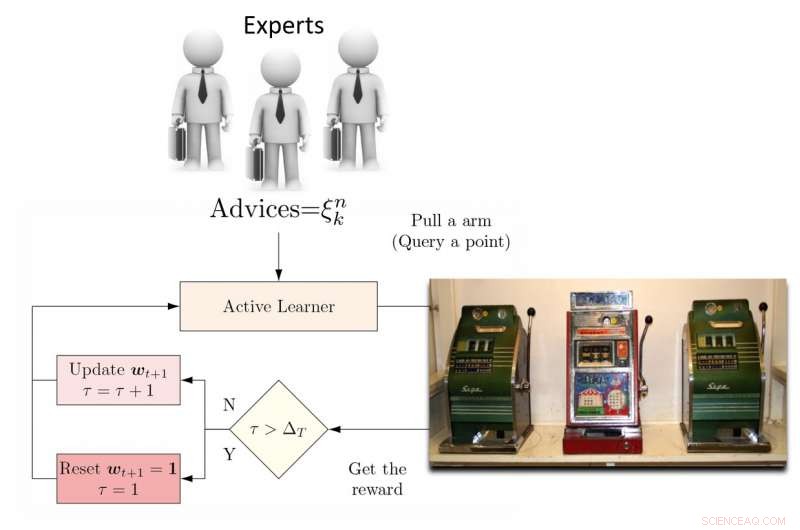
Illustration de l'algorithme DEAL REXP4. Crédit :Pang et al.
Malgré les résultats très prometteurs, la technique mise au point par les chercheurs présente encore une limite importante. DEAL fait tout l'apprentissage au sein d'un seul problème et cela se traduit par un « démarrage à froid, ' ce qui signifie que l'algorithme aborde tous les nouveaux problèmes avec une ardoise vierge.
« Dans les travaux en cours, nous apprenons à annoter de nombreux problèmes différents et éventuellement à transférer ces connaissances à un nouveau problème, afin d'effectuer une annotation efficace immédiatement sans exigence de préchauffage, ", a déclaré Pang. "Nos travaux préliminaires sur ce sujet ont été publiés et ont également remporté le prix du meilleur article lors de l'atelier AutoML 2018 de l'ICML."
© 2018 Réseau Science X