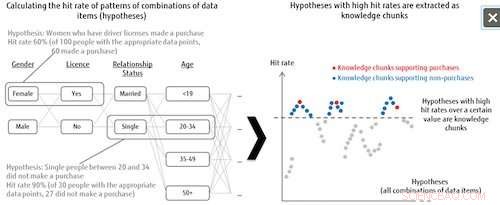
Figure 1 :Listage d'hypothèses et extraction de fragments de connaissances. Crédit :Fujitsu
Fujitsu Laboratories Ltd. a annoncé aujourd'hui le développement de "Wide Learning, " une technologie d'apprentissage automatique capable de jugements précis même lorsque les opérateurs ne peuvent pas obtenir le volume de données nécessaires à la formation. L'IA est maintenant souvent utilisée pour exploiter des données dans une variété de domaines, mais la précision de l'IA peut être affectée dans les cas où le volume de données à analyser est faible ou déséquilibré. La technologie Wide Learning de Fujitsu permet d'obtenir des jugements plus précisément qu'auparavant, et l'apprentissage est réalisé uniformément, quelle que soit l'hypothèse examinée, même lorsque les données sont déséquilibrées. Il y parvient en extrayant d'abord des hypothèses de haut degré d'importance, ayant fait un grand ensemble d'hypothèses formées par toutes les combinaisons de données, puis en contrôlant le degré d'impact de chaque hypothèse respective sur la base des relations de chevauchement des hypothèses. De plus, parce que les hypothèses sont enregistrées comme des expressions logiques, les humains peuvent également comprendre le raisonnement derrière un jugement. La nouvelle technologie Wide Learning de Fujitsu permet l'utilisation de l'IA même dans des domaines tels que la santé et le marketing, où les données nécessaires pour porter des jugements sont rares, soutenir les opérations et promouvoir l'automatisation des processus de travail à l'aide de l'IA.
Dans les années récentes, La technologie de l'IA a commencé à être utilisée dans une variété de domaines, y compris les soins de santé, commercialisation, et financier. Les attentes augmentent quant à l'utilisation de la prise de décision par l'IA pour soutenir les opérations et automatiser les tâches dans ces domaines. Un défi qui reste à réaliser le potentiel de ces technologies, cependant, est que les données peuvent être déséquilibrées. Spécifiquement, selon l'industrie, il peut être difficile d'obtenir des données suffisantes pour former l'IA sur les cibles sur lesquelles elle doit porter des jugements. Cette, en effet, laisse beaucoup de ces technologies incapables de produire des résultats avec une précision suffisante pour une utilisation pratique. Par ailleurs, l'une des principales raisons pour lesquelles le déploiement de l'IA ne progresse pas est que même lorsqu'une IA fournit des performances de reconnaissance ou de classification suffisamment précises, les experts et même les développeurs eux-mêmes ne peuvent souvent pas expliquer pourquoi l'IA a produit une certaine réponse, et s'ils ne peuvent pas s'acquitter de leur responsabilité d'expliquer les résultats aux premières lignes de l'industrie, alors l'IA ne peut pas être déployée.
Les technologies d'IA basées sur l'apprentissage profond font classiquement des jugements très précis en étant formées sur de gros volumes de données, y compris de nombreuses données cibles à évaluer. Dans des scénarios du monde réel, cependant, il existe de nombreux cas où les données sont insuffisantes, avec extrêmement peu de données cibles. Dans ces cas, face à des données inconnues, il devient difficile pour la technologie de l'IA de fournir des jugements très précis. De plus, le modèle d'apprentissage automatique pour l'IA existante basé sur l'apprentissage en profondeur est un modèle de boîte noire qui ne peut pas expliquer les raisons des jugements portés par l'IA, créer un problème de transparence. En tant que tel, à l'avenir, il sera nécessaire de développer une nouvelle technologie d'IA qui réalise des jugements très précis à partir de données déséquilibrées, et qui est également transparent afin de résoudre divers problèmes de société.
Compte tenu de ces défis, Fujitsu Laboratories a maintenant développé Wide Learning, une technologie d'apprentissage automatique capable de porter des jugements très précis même dans les cas où les données sont déséquilibrées. Les caractéristiques de la technologie Wide Learning comprennent les deux points suivants.
1. Crée des combinaisons d'éléments de données pour extraire de grands volumes d'hypothèses
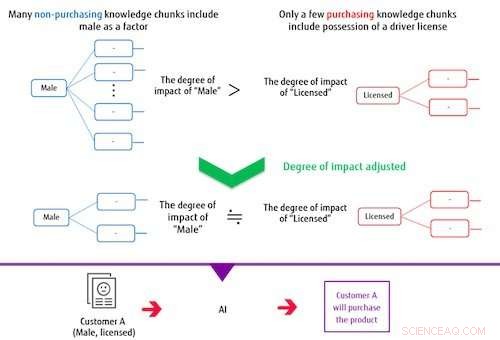
Figure 2 :Lors de la création d'un modèle de classification, les morceaux de connaissances ont un impact sur l'ajustement. Crédit :Fujitsu
Cette technologie traite tous les modèles de combinaison d'éléments de données comme des hypothèses, puis détermine le degré d'importance de chaque hypothèse en fonction du taux de réussite pour la catégorie d'étiquette. Par exemple, lors de l'analyse des tendances concernant les acheteurs de certains produits, le système combine toutes sortes de modèles à partir des éléments de données pour ceux qui ont fait ou non des achats (l'étiquette de catégorie), comme les femmes célibataires entre 20 et 34 ans qui ont un permis de conduire, puis analyse le nombre de visites qu'il obtient dans les données de ceux qui ont réellement effectué des achats lorsque ces modèles de combinaison sont considérés comme des hypothèses. Les hypothèses qui atteignent un taux de réussite supérieur à un certain niveau sont définies comme des hypothèses importantes, appelés « morceaux de connaissances ». Cela signifie que même lorsque les données cibles sont insuffisantes, le système peut extraire toutes les hypothèses intéressantes, ce qui peut aussi contribuer à la découverte d'explications jusqu'alors inconsidérées.
2. Ajuste le degré d'impact des morceaux de connaissances pour créer un modèle de classification précis
Le système construit un modèle de classification basé sur plusieurs fragments de connaissances extraits et sur l'étiquette cible. Dans ce processus, si les éléments constituant un bloc de connaissances se chevauchent fréquemment avec les éléments constituant d'autres blocs de connaissances, le système contrôle leur degré d'impact afin de réduire le poids de leur influence sur le modèle de classification. De cette façon, le système peut entraîner un modèle capable de classifications précises même lorsque l'étiquette cible ou les données marquées comme correctes sont déséquilibrées. Par exemple, dans un cas où les hommes qui n'ont pas effectué d'achat constituent la grande majorité d'un ensemble de données d'achat d'articles, si l'IA est entraînée sans contrôler le degré d'impact, puis le morceau de connaissances qui comprend si une personne a ou non une licence, indépendant du sexe, n'aura pas beaucoup d'influence sur le classement. Avec cette nouvelle méthode, le degré d'impact des morceaux de connaissances, y compris les hommes en tant que facteur, est limité en raison du chevauchement de cet élément, tandis que l'impact du plus petit nombre de morceaux de connaissances qui incluent si une personne a une licence devient relativement plus important dans la formation, construire un modèle capable de catégoriser correctement à la fois les hommes et la possession d'un permis.
Les Laboratoires Fujitsu ont mené un essai de cette technologie, en l'appliquant aux données dans des domaines tels que le marketing numérique et les soins de santé. Dans un test utilisant des données de référence dans les domaines du marketing et de la santé du référentiel d'apprentissage automatique de l'UC Irvine, cette technologie a amélioré la précision d'environ 10 à 20 % par rapport à l'apprentissage en profondeur. Il a réussi à réduire d'environ 20 à 50 % la probabilité que le système néglige les clients susceptibles de s'abonner à un service ou les patients atteints d'une maladie. Dans les données marketing, sur les 5 environ, 000 entrées de données client utilisées dans le test, seulement environ 230 étaient destinés à l'achat de clients, créant un ensemble déséquilibré. Cette technologie a réduit le nombre de clients potentiels exclus des promotions des ventes de 120, le résultat d'une analyse d'apprentissage en profondeur, à 74. De plus, comme les morceaux de connaissances qui constituent la base de cette technologie ont un format d'expression logique, la capacité d'expliquer le raisonnement derrière un jugement est également utile dans la mise en œuvre de cette technologie dans la société. Même lorsqu'il est déterminé que des corrections à un modèle sont nécessaires, sur la base des résultats de nouvelles données, il est possible de faire des révisions plus appropriées, car les utilisateurs peuvent comprendre les raisons des résultats.
Les laboratoires Fujitsu continueront d'appliquer cette technologie aux tâches qui exigent le raisonnement derrière les jugements de l'IA, comme dans les transactions financières et les diagnostics médicaux, et aux tâches qui gèrent les phénomènes de basse fréquence, comme la fraude et les pannes d'équipement, dans le but de la commercialiser en tant que nouvelle technologie d'apprentissage automatique prenant en charge Fujitsu Human Centric AI Zinrai de Fujitsu Limited au cours de l'exercice 2019. Fujitsu Laboratories utilisera également efficacement la capacité d'explication caractéristique de cette technologie, poursuivre la recherche et le développement sur des sujets tels qu'un meilleur soutien pour prendre des décisions et prendre des décisions dans les tâches auxquelles il est appliqué, et dans la conception globale du système, y compris la collaboration avec les humains.