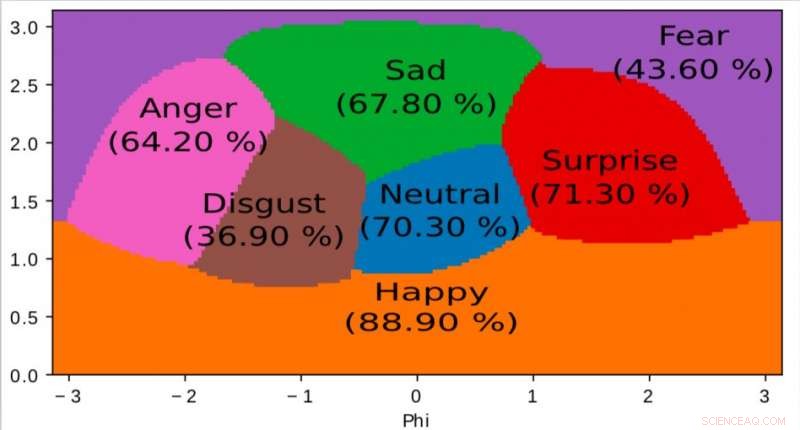
Une représentation de l'espace interne apprise par notre algorithme et utilisée pour mapper les émotions dans un espace continu 2D. Il est intéressant de noter que même si les données d'entraînement ne contiennent que des étiquettes d'émotion discrètes, le réseau apprend un espace continu, permettant non seulement de décrire finement l'état émotionnel des personnes mais aussi de positionner les émotions les unes par rapport aux autres. Cet espace présente une forte similitude avec l'espace de valence d'excitation défini par la psychologie moderne. Crédit :Jurie et al.
Des chercheurs d'Orange Labs et de l'Université de Normandie ont développé un nouveau modèle neuronal profond pour la reconnaissance des émotions audiovisuelles qui fonctionne bien avec de petits ensembles d'entraînement. Leur étude, qui a été prépublié sur arXiv , suit une philosophie de simplicité, limitant considérablement les paramètres que le modèle acquiert à partir des ensembles de données et en utilisant des techniques d'apprentissage simples.
Les réseaux de neurones pour la reconnaissance des émotions ont un certain nombre d'applications utiles dans le contexte des soins de santé, analyse client, surveillance, et même des animations. Alors que les algorithmes d'apprentissage en profondeur de pointe ont obtenu des résultats remarquables, la plupart sont encore incapables d'atteindre la même compréhension des émotions que les humains.
"Notre objectif global est de faciliter l'interaction homme-machine en rendant les ordinateurs capables de percevoir divers détails subtils exprimés par les humains, " Frédéric Jurie, l'un des chercheurs qui a mené l'étude, a déclaré TechXplore. "Percevoir les émotions contenues dans les images, vidéo, la voix et le son s'inscrivent dans ce contexte.
Récemment, des études ont rassemblé des ensembles de données multimodales et temporelles qui contiennent des vidéos annotées et des clips audiovisuels. Pourtant, ces ensembles de données contiennent généralement un nombre relativement faible d'échantillons annotés, tout en étant performant, la plupart des algorithmes d'apprentissage en profondeur existants nécessitent des ensembles de données plus volumineux.
Les chercheurs ont tenté de résoudre ce problème en développant un nouveau cadre pour la reconnaissance audiovisuelle des émotions, qui fusionne l'analyse de séquences visuelles et sonores, conservant un haut niveau de précision même avec des ensembles de données d'entraînement relativement petits. Ils ont entraîné leur modèle neuronal sur AFEW, un ensemble de données de 773 clips audiovisuels extraits de films et annotés d'émotions discrètes.

Illustration de la façon dont cet espace 2D peut être utilisé pour contrôler les émotions exprimées par les visages, de façon continue, à l'aide de réseaux génératifs contradictoires (GAN). Crédit :Jurie et al.
"On peut voir ce modèle comme une boîte noire traitant la vidéo et déduisant automatiquement l'état émotionnel des gens, " Jurie a expliqué. " Un grand avantage de ces modèles de neurones profonds est qu'ils apprennent par eux-mêmes comment traiter la vidéo en analysant des exemples, et n'exigent pas d'experts qu'ils fournissent des unités de traitement spécifiques. »
Le modèle imaginé par les chercheurs suit le principe philosophique du rasoir d'Occam, ce qui suggère qu'entre deux approches ou explications, le plus simple est le meilleur choix. Contrairement à d'autres modèles d'apprentissage profond pour la reconnaissance des émotions, donc, leur modèle est relativement simple. Le réseau de neurones apprend un nombre limité de paramètres à partir de l'ensemble de données et utilise des stratégies d'apprentissage de base.
"Le réseau proposé est constitué de couches de traitement en cascade faisant abstraction de l'information, du signal à son interprétation, " Jurie a déclaré. " L'audio et la vidéo sont traités par deux canaux différents du réseau et sont combinés dernièrement dans le processus, presque à la fin."
Une fois testé, leur modèle lumineux a atteint une précision de reconnaissance des émotions prometteuse de 60,64 %. Il a également été classé quatrième au défi 2018 Emotion Recognition in the Wild (EmotiW), tenue à la Conférence internationale ACM sur l'interaction multimodale (ICMI), dans le Colorado.

Illustration de la façon dont cet espace 2D peut être utilisé pour contrôler les émotions exprimées par les visages, de façon continue, à l'aide de réseaux génératifs contradictoires (GAN). Crédit :Jurie et al.
"Notre modèle est la preuve qu'en suivant le principe du rasoir d'Occam, c'est à dire., en choisissant toujours les alternatives les plus simples pour concevoir des réseaux de neurones, il est possible de limiter la taille des modèles et d'obtenir des réseaux de neurones très compacts mais à la pointe de la technologie, qui sont plus faciles à former, " Jurie a déclaré. "Cela contraste avec la tendance de la recherche de rendre les réseaux de neurones de plus en plus gros."
Les chercheurs vont maintenant continuer à explorer les moyens d'atteindre une grande précision dans la reconnaissance des émotions en analysant simultanément les données visuelles et auditives, en utilisant les ensembles de données d'entraînement annotés limités qui sont actuellement disponibles.
« Nous nous intéressons à plusieurs axes de recherche, comme comment mieux fusionner les différentes modalités, comment représenter l'émotion en compactant sémantiquement des descripteurs complets (et pas seulement des étiquettes de classe) ou comment rendre nos algorithmes capables d'apprendre avec moins, ou même sans, données annotées, ", a déclaré Jury.
© 2018 Tech Xplore