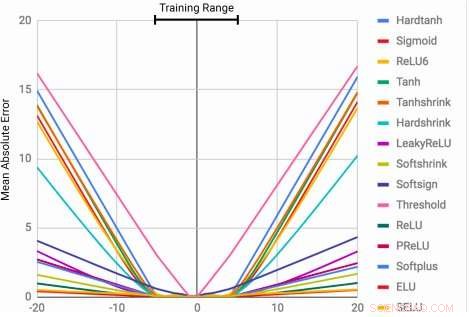
Les MLP apprennent la fonction d'identité uniquement pour les valeurs de plage sur lesquelles ils sont entraînés. L'erreur moyenne augmente considérablement à la fois en dessous et au-dessus de la plage de nombres observée pendant l'entraînement. Crédit :Trask et al.
La capacité de représenter et de manipuler des quantités numériques peut être observée chez de nombreuses espèces, y compris les insectes, mammifères et humains. Cela suggère que le raisonnement quantitatif de base est une composante importante de l'intelligence, qui a plusieurs avantages évolutifs.
Cette capacité pourrait être très précieuse dans les machines, permettant une exécution plus rapide et plus efficace des tâches impliquant la manipulation de nombres. Encore, jusque là, les réseaux de neurones formés pour représenter et manipuler des informations numériques ont rarement été capables de se généraliser bien en dehors de la plage de valeurs rencontrées au cours du processus d'apprentissage.
Une équipe de chercheurs de Google DeepMind a récemment développé une nouvelle architecture qui répond à cette limitation, parvenir à une meilleure généralisation à la fois à l'intérieur et à l'extérieur de la plage de valeurs numériques sur laquelle le réseau de neurones a été formé. Leur étude, qui a été prépublié sur arXiv, pourrait éclairer le développement d'outils d'apprentissage automatique plus avancés pour effectuer des tâches de raisonnement quantitatif.
"Lorsque les architectures neuronales standard sont entraînées à compter jusqu'à un nombre, ils ont souvent du mal à compter jusqu'à un plus haut, " André Trask, chercheur principal sur le projet, a déclaré Tech Xplore. "Nous avons exploré cette limitation et constaté qu'elle s'étend également à d'autres fonctions arithmétiques, menant à notre hypothèse que les réseaux de neurones apprennent les nombres de la même manière qu'ils apprennent les mots, comme un vocabulaire fini. Cela les empêche d'extrapoler correctement des fonctions nécessitant des nombres (plus élevés) auparavant jamais vus. Notre objectif était de proposer une nouvelle architecture permettant une meilleure extrapolation."

L'accumulateur neuronal (NAC) est une transformation linéaire de ses entrées. La matrice de transformation est le produit élément par élément de tanh (Wˆ ) et σ(Mˆ ). L'unité logique arithmétique neuronale (NALU) utilise deux NAC avec des poids liés pour permettre l'addition/soustraction (cellule violette plus petite) et la multiplication/division (cellule violette plus grande), commandé par un portail (cellule orange). Crédit :Trask et al.
Les chercheurs ont conçu une architecture qui encourage une extrapolation plus systématique des nombres en représentant des quantités numériques sous forme d'activations linéaires qui sont manipulées à l'aide d'opérateurs arithmétiques primitifs, qui sont contrôlés par des portes apprises. Ils ont appelé ce nouveau module l'unité logique arithmétique neuronale (NALU), inspiré de l'unité arithmétique et logique des processeurs traditionnels.
« Les nombres sont généralement encodés dans des réseaux de neurones en utilisant des représentations uniques ou distribuées, et les fonctions sur les nombres sont apprises dans une série de couches avec des activations non linéaires, " expliqua Trask. " Nous proposons que les nombres soient plutôt stockés sous forme de scalaires, stocker un seul nombre dans chaque neurone. Par exemple, si vous vouliez mémoriser le nombre 42, vous devriez juste avoir un neurone contenant une activation d'exactement '42, ' au lieu d'une série de 0-1 neurones qui l'encodent."
Les chercheurs ont également changé la façon dont le réseau de neurones apprend les fonctions sur ces nombres. Plutôt que d'utiliser des architectures standards, qui peut apprendre n'importe quelle fonction, ils ont conçu une architecture qui propage vers l'avant un ensemble prédéfini de fonctions qui sont considérées comme potentiellement utiles (par exemple, l'ajout, multiplication ou division), en utilisant des architectures neuronales qui apprennent les mécanismes d'attention sur ces fonctions.
"Ces mécanismes d'attention décident alors quand et où chaque fonction potentiellement utile peut être appliquée au lieu d'apprendre cette fonction elle-même, " Trask a déclaré. "C'est un principe général pour créer des réseaux de neurones profonds avec un biais d'apprentissage souhaitable sur les fonctions numériques."

(ci-dessus) Images de la tâche de suivi du temps gridworld. L'agent (gris) doit se déplacer vers la destination (rouge) à une heure spécifiée. (ci-dessous) NAC améliore la capacité d'extrapolation apprise par les agents A3C pour la tâche de datation. Crédit :Trask et al.
Leur test a révélé que les réseaux de neurones améliorés par NALU pouvaient apprendre à effectuer une variété de tâches, comme le suivi du temps, exécuter des fonctions arithmétiques sur des images de nombres, traduire le langage numérique en scalaires à valeur réelle, exécuter du code informatique et compter des objets dans des images.
Par rapport aux architectures conventionnelles, leur module a atteint une généralisation significativement meilleure à la fois à l'intérieur et à l'extérieur de la plage de valeurs numériques qui lui a été présentée pendant la formation. Bien que NALU ne soit pas la solution idéale pour chaque tâche, leur étude fournit une stratégie de conception générale pour créer des modèles qui fonctionnent bien sur une classe particulière de fonctions.
« La notion selon laquelle un réseau de neurones profonds doit sélectionner parmi un ensemble prédéfini de fonctions et apprendre les mécanismes d'attention régissant leur utilisation est une idée très extensible, " expliqua Trask. " Dans ce travail, nous avons exploré des fonctions arithmétiques simples (addition, soustraction, Multiplication et division), mais nous sommes enthousiasmés par le potentiel d'apprendre les mécanismes d'attention sur des fonctions beaucoup plus puissantes à l'avenir, apportant peut-être les mêmes résultats d'extrapolation que nous avons observés dans une grande variété de domaines."
© 2018 Tech Xplore