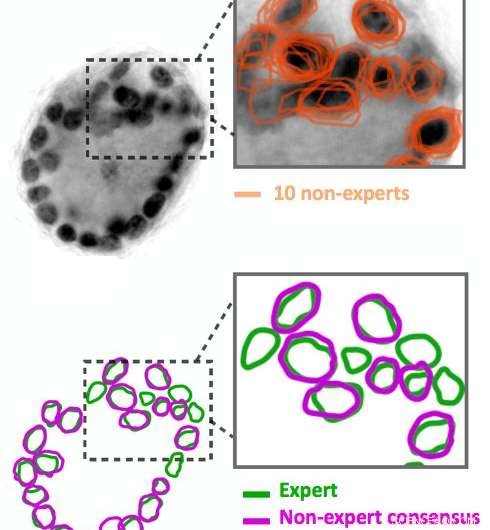
Les annotations d'images non expertes sont bruyantes. Dix non-experts ont décrit les cercles noirs foncés dans l'image, qui sont des noyaux cellulaires. Leurs résultats (affichés en orange) ne correspondent pas exactement. Nos algorithmes sont capables de déduire un contour consensuel (affiché en violet) à partir des données bruitées. Comparez ce consensus avec l'annotation d'experts de la même image (affichée en vert). Crédit :IBM
Aujourd'hui, mon équipe IBM et mes collègues du laboratoire UCSF Gartner ont rapporté dans Méthodes naturelles une approche innovante pour générer des ensembles de données à partir de non-experts et les utiliser pour la formation en apprentissage automatique. Notre approche est conçue pour permettre aux systèmes d'IA d'apprendre aussi bien des non-experts que des données de formation générées par des experts. Nous avons développé une plateforme, appelé Quanti.us, qui permet aux non-experts d'analyser des images (une tâche courante dans la recherche biomédicale) et de créer un ensemble de données annotées. La plateforme est complétée par un ensemble d'algorithmes spécifiquement conçus pour interpréter correctement ce type de données "bruyantes" et incomplètes. Utilisé ensemble, ces technologies peuvent étendre les applications de l'apprentissage automatique dans la recherche biomédicale.
Non-spécialistes et données bruitées
La disponibilité limitée d'ensembles de données annotés de haute qualité est un goulot d'étranglement pour faire progresser l'apprentissage automatique. En créant des algorithmes capables de fournir des résultats précis à partir d'annotations de qualité inférieure, et un système permettant de collecter rapidement ces données, nous pouvons contribuer à réduire le goulot d'étranglement. L'analyse des images pour les caractéristiques d'intérêt est un excellent exemple. L'annotation d'images par des experts est précise mais prend du temps, et les techniques d'analyse automatisées telles que la segmentation basée sur le contraste et la détection des contours fonctionnent bien dans des conditions définies, mais sont sensibles aux changements de configuration expérimentale et peuvent produire des résultats peu fiables.
Entrez dans le crowdsourcing. En utilisant Quanti.us, nous avons obtenu des annotations d'images issues du crowdsourcing 10 à 50 fois plus rapidement qu'il n'aurait fallu à un seul expert pour analyser les mêmes images. Mais, comme on pouvait s'y attendre, les annotations de non-spécialistes étaient bruyantes :certaines identifiaient correctement une caractéristique et d'autres étaient hors cible. Nous avons développé des algorithmes pour traiter les données bruitées, déduire l'emplacement correct d'une entité à partir de l'agrégation des hits sur et hors cible. Lorsque nous avons formé un réseau de régression convolutive profonde à l'aide de l'ensemble de données crowdsourcé, il a presque aussi bien fonctionné qu'un réseau formé aux annotations d'experts, en ce qui concerne la précision et le rappel. En plus du document décrivant notre approche et notre stratégie, nous avons publié le code source de notre algorithme.
Applications en ingénierie cellulaire
L'analyse d'images est au cœur de nombreux domaines de la biologie quantitative et de la médecine. Il y a quelques années, nous et nos collaborateurs avons annoncé le Center for Cellular Construction (CCC), financé par la NSF, un centre scientifique et technologique pionnier dans la nouvelle discipline scientifique de l'ingénierie cellulaire. CCC facilite une collaboration étroite entre les experts de différentes disciplines, comme l'apprentissage automatique, la physique, l'informatique, biologie cellulaire et moléculaire, et génomique, pour faire progresser l'ingénierie cellulaire. Nous visons à étudier et créer des cellules pouvant être utilisées comme des machines automatisées, ou des capteurs ad hoc, pour apprendre des informations nouvelles et vitales sur une variété d'entités biologiques et leur relation avec l'environnement dans lequel elles vivent. Nous utilisons l'analyse d'images pour localiser la position et la taille des composants cellulaires internes. Mais même avec des techniques d'imagerie avancées, l'inférence exacte des sous-structures cellulaires peut être incroyablement bruyante, rendant difficile l'intervention sur les composants de la cellule. Notre technique peut utiliser ces données bruitées pour prédire correctement où peuvent se trouver les structures cellulaires pertinentes, permettant une meilleure identification des organites impliqués dans la production de produits chimiques importants ou de cibles médicamenteuses potentielles dans une maladie.
Nous pensons que nos algorithmes sont une première étape importante vers des plateformes d'IA plus complexes. De tels systèmes peuvent utiliser des paradigmes supplémentaires "humains dans la boucle", en impliquant un biologiste pour corriger les erreurs lors de la phase de formation, par exemple, pour améliorer encore les performances. Nous voyons également une opportunité d'appliquer notre méthode au-delà de la biologie à d'autres domaines où les ensembles de données annotées de haute qualité peuvent être rares.
Cette histoire est republiée avec l'aimable autorisation d'IBM Research. Lisez l'histoire originale ici.