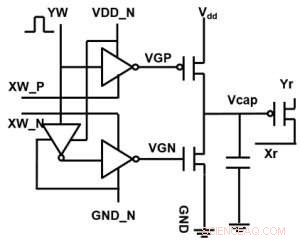
Figure 1. Schéma de cellule unitaire d'un réseau de points de croisement à base de condensateurs. Crédit :IBM
IBM va au-delà des technologies numériques avec un réseau de points de croisement à base de condensateurs pour les réseaux de neurones analogiques, présentant des améliorations potentielles d'ordres de grandeur dans les calculs d'apprentissage en profondeur. Les architectures informatiques analogiques exploitent la capacité de stockage et les attributs physiques de certains dispositifs de mémoire non seulement pour stocker des informations, mais aussi pour effectuer des calculs. Cela a le potentiel de réduire considérablement le temps et l'énergie requis par les ordinateurs, car les données n'ont pas besoin d'être transférées entre la mémoire et le processeur. L'inconvénient pourrait être une réduction de la précision de calcul, mais pour les systèmes qui ne nécessitent pas une grande précision, c'est le bon compromis.
Dans les réseaux de neurones analogiques (NN), Les matrices de points croisés basées sur la mémoire non volatile (NVM) ont obtenu des résultats prometteurs pour les tâches d'inférence. Cependant, la formation des NN à une haute précision est difficile pour les appareils NVM, étant donné que la réussite de l'entraînement dépend de la réduction des changements incrémentiels du poids NN (nécessitant environ 1, 000 états de mise à jour) et symétrique (de sorte que les mises à jour positives et négatives s'équilibrent en moyenne). Ces problèmes peuvent être résolus en utilisant des condensateurs. Puisque la charge peut être ajoutée ou soustraite en continu si le nombre d'électrons est élevé, une mise à jour du poids analogique et symétrique peut être réalisée. Nous avons présenté un réseau de points de croisement à base de condensateurs pour les réseaux de neurones analogiques au VLSI Technology Symposium 2018. La nouvelle architecture a atteint une symétrie et une linéarité record pour la mise à jour du poids.
La figure 1 montre le schéma de cellule unitaire d'un réseau de points de croisement à base de condensateurs. Le composant clé est le condensateur qui est connecté à un transistor à effet de champ (FET) de lecture. La charge sur le condensateur représente le poids synaptique et le condensateur est chargé et déchargé avec deux FET de source de courant. La figure 2 montre le changement mesuré de la conductance du FET de lecture d'une seule cellule, et la tension de condensateur correspondante respectivement, en appliquant dix cycles de 400 mises à jour positives suivies de 400 mises à jour négatives. La figure 3 compare les facteurs expérimentaux de mise à jour de non-linéarité pour notre synapse analogique à condensateur par rapport à d'autres technologies NVM. La cellule unitaire à condensateur offre la meilleure symétrie et linéarité démontrée à ce jour. La figure 4 illustre la mise à jour du poids parallèle sur un tableau 2 × 2.
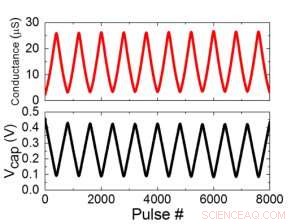
Figure 2. (a) Résultats expérimentaux pour la mise à jour d'une cellule unique avec 8000 impulsions. (b) Changement de tension du condensateur correspondant. Largeur d'impulsion 50 ns, période :500 ns. Crédit :IBM
Même si les condensateurs sont volatils, la fuite pourrait être compensée lors de la mise à jour du poids. Étant donné que la formation se poursuit à plusieurs reprises, cycles de mise à jour en arrière et poids, les poids après la décroissance du cycle précédent sont utilisés dans l'entraînement pour le cycle suivant et sont mis à jour. Par conséquent, aucun cycle de rafraîchissement intentionnel n'est nécessaire. Nous avons testé l'effet du temps de rétention sur l'entraînement, en utilisant un réseau entièrement connecté. Il a une couche d'entrée, deux couches cachées, et une couche de sortie (Figure 5) et a été formé sur l'ensemble de données MNIST par descente de gradient stochastique et rétropropagation. En supposant que la longueur du cycle d'entraînement par couche (avant + arrière + mise à jour) est de 200 ns et que le poids synaptique décroît avec la constante de temps RC τ, nous avons constaté que la pénalité dans la précision de la formation due à la perte de charge du condensateur devient négligeable lorsque τ> 106 × la durée du cycle d'entraînement (Figure 6). Nous avons également testé l'exigence de temps de rétention pour un réseau convolutif. Notre réseau de test comporte deux couches convolutives avec deux couches de mise en commun et deux couches entièrement connectées (Figure 7). En raison du partage du poids (réutilisation) dans les couches convolutives, les exigences de rétention pour un réseau de neurones convolutifs (CNN) sont environ 600 plus grandes (Figure 8).
Nous estimons l'évolutivité de ce réseau à base de condensateurs en fonction des fuites pour les réseaux de neurones entièrement connectés et convolutifs (Figure 9). Les points de données du cercle montrent que le condensateur évolue linéairement avec la fuite du transistor de passage. Les points de données carrés montrent que lorsque la fuite est importante, la surface de la cellule est dominée par les condensateurs; lorsque le courant de fuite est faible, la zone sera dominée par les FET dans la cellule. Pour la technologie DRAM avec une fuite de 1 fA/cellule nécessite un condensateur <1fF/cellule pour un réseau neuronal entièrement connecté et ~ 100 fF/cellule pour CNN. L'évolutivité vers une entrée plus importante et plus de couches nécessite une étude plus approfondie. Même s'il peut avoir besoin d'un plus gros condensateur lorsque l'entrée devient plus grande, nos résultats préliminaires (à publier) montrent que l'optimisation réseau/algorithme pourrait réduire les besoins en condensateurs.
IBM travaille maintenant sur une nouvelle mémoire idéale avec un comportement analogique optimisé. Ces condensateurs permettront de mettre en œuvre le cœur d'IA analogique selon un calendrier accéléré, puisque la technologie et le processus sont disponibles.
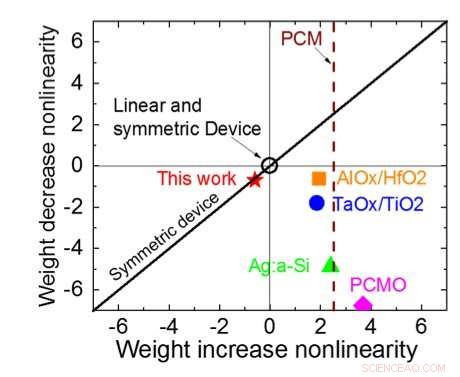
Figure 3. Non-linéarité de conductance de ce travail par rapport à d'autres technologies NVM. Crédit :IBM
En plus de notre approche condensateur, IBM explore d'autres éléments nouveaux pour la mémoire et le calcul analogiques tels que la mémoire à changement de phase (PCM) et la RAM résistive (RRAM). Ces éléments varient en termes de surfaces cellulaires, rétention, symétrie, et maturité. Les accélérateurs analogiques sont un composant du pipeline d'accélérateurs matériels d'IA d'IBM Research AI. Le pipeline commence par tirer le meilleur parti des accélérateurs GPU existants, suivis par des cœurs d'IA numériques innovants exploitant le calcul approximatif.
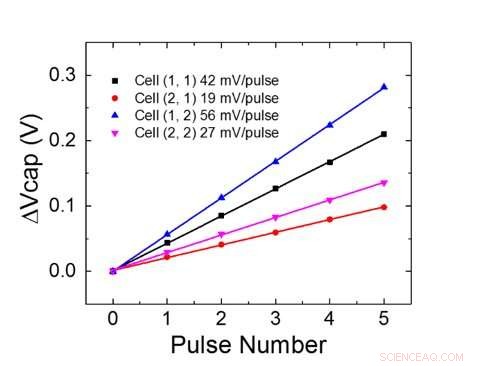
Figure 4. Mise à jour du poids parallèle sur une matrice 2×2. Crédit :IBM
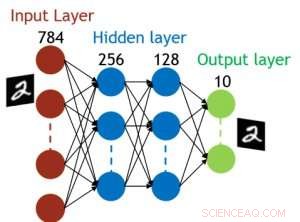
Figure 5. Structure simulée pour un réseau de neurones entièrement connecté. Crédit :IBM
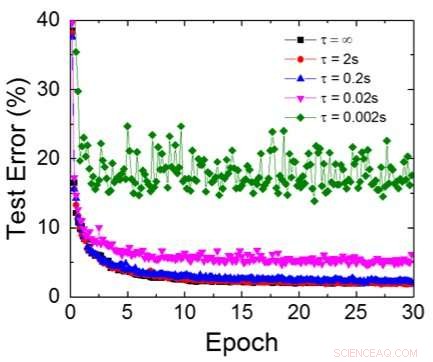
Figure 6. Erreur de test simulée de l'ensemble de données MNIST, en supposant que les poids décroissent continuellement avec une constante de temps RC différente τ, Durée du cycle d'entraînement de 200 ns. Crédit :IBM
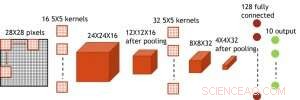
Figure 7. Structure simulée pour réseau de neurones convolutifs. Crédit :IBM
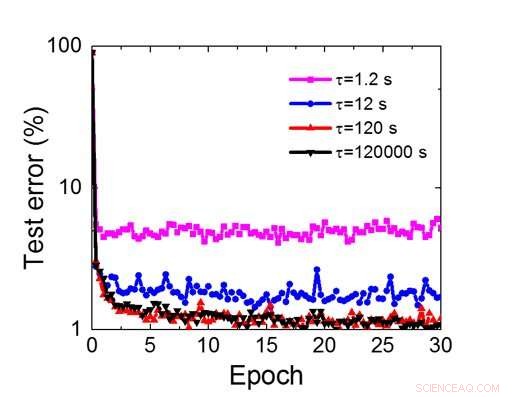
Figure 8. Temps de rétention simulé requis pour ce réseau à base de condensateurs pour former un réseau de neurones convolutifs. Crédit :IBM
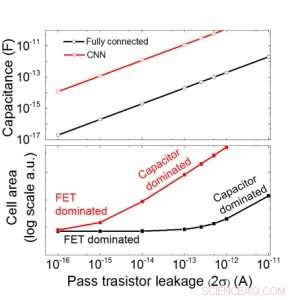
Figure 9. Évolutivité de ce réseau à base de condensateurs en fonction des fuites pour les réseaux de neurones entièrement connectés et convolutifs. Crédit :IBM