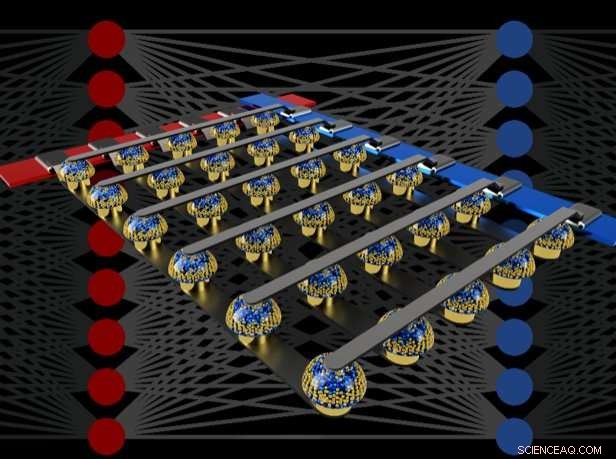
Les réseaux crossbar de mémoires non volatiles peuvent accélérer la formation de réseaux de neurones entièrement connectés en effectuant des calculs à l'emplacement des données. Crédit :IBM
Imaginez une Intelligence Artificielle (IA) personnalisée, où votre smartphone devient plus comme un assistant intelligent - reconnaissant votre voix même dans une pièce bruyante, comprendre le contexte de différentes situations sociales ou ne présenter que les informations qui vous concernent vraiment, arrachés au flot de données qui arrivent chaque jour. De telles capacités pourraient bientôt être à notre portée, mais pour y parvenir, il faudra rapidement, puissant, accélérateurs matériels d'IA écoénergétiques.
Dans un article récent publié dans La nature , notre équipe IBM Research AI a démontré une formation en réseau de neurones profonds (DNN) avec de grandes matrices de périphériques de mémoire analogiques avec la même précision qu'un système basé sur une unité de traitement graphique (GPU). Nous pensons qu'il s'agit d'une étape majeure sur la voie du type d'accélérateurs matériels nécessaires aux prochaines percées de l'IA. Pourquoi? Parce que livrer l'avenir de l'IA nécessitera d'étendre considérablement l'échelle des calculs de l'IA.
Les DNN doivent devenir plus gros et plus rapides, à la fois dans le cloud et à la périphérie, ce qui signifie que l'efficacité énergétique doit s'améliorer considérablement. Alors que de meilleurs GPU ou autres accélérateurs numériques peuvent aider dans une certaine mesure, de tels systèmes passent inévitablement beaucoup de temps et d'énergie à déplacer les données de la mémoire vers le traitement et inversement. Nous pouvons améliorer à la fois la vitesse et l'efficacité énergétique en effectuant des calculs d'IA dans le domaine analogique directement à l'emplacement des données - mais cela n'a de sens que si les réseaux de neurones résultants sont tout aussi intelligents que ceux mis en œuvre avec du matériel numérique conventionnel.
Techniques analogiques, impliquant des signaux variables en continu plutôt que des 0 et des 1 binaires, ont des limites inhérentes à leur précision, c'est pourquoi les ordinateurs modernes sont généralement des ordinateurs numériques. Cependant, Les chercheurs en IA ont commencé à se rendre compte que leurs modèles DNN fonctionnent toujours bien même lorsque la précision numérique est réduite à des niveaux qui seraient bien trop bas pour presque toutes les autres applications informatiques. Ainsi, pour les DNN, il est possible que le calcul analogique puisse également fonctionner.
Cependant, jusqu'à maintenant, personne n'avait prouvé de manière concluante que de telles approches analogiques pouvaient faire le même travail que les logiciels d'aujourd'hui fonctionnant sur du matériel numérique conventionnel. C'est-à-dire, Les DNN peuvent-ils vraiment être entraînés à des précisions équivalentes avec ces techniques ? Il y a peu d'intérêt à être plus rapide ou plus économe en énergie dans la formation d'un DNN si les précisions de classification résultantes vont toujours être trop faibles.
Dans notre papier, nous décrivons comment les mémoires non volatiles analogiques (NVM) peuvent accélérer efficacement l'algorithme de « rétropropagation » au cœur de nombreuses avancées récentes de l'IA. Ces mémoires permettent de paralléliser dans le domaine analogique les opérations "multiplier-accumuler" utilisées tout au long de ces algorithmes, à l'emplacement des données de poids, en utilisant la physique sous-jacente. Au lieu de grands circuits pour multiplier et additionner des nombres numériques, nous passons simplement un petit courant à travers une résistance dans un fil, puis connectez plusieurs de ces fils ensemble pour laisser les courants s'accumuler. Cela nous permet d'effectuer plusieurs calculs en même temps, plutôt que l'un après l'autre. Et au lieu d'expédier des données numériques sur de longs trajets entre les puces de mémoire numérique et les puces de traitement, nous pouvons effectuer tous les calculs à l'intérieur de la puce de mémoire analogique.
Cependant, en raison de diverses imperfections inhérentes aux dispositifs de mémoire analogique d'aujourd'hui, les démonstrations précédentes de la formation DNN effectuées directement sur de grands réseaux de dispositifs NVM réels n'ont pas réussi à atteindre des précisions de classification correspondant à celles des réseaux formés par logiciel.
En combinant le stockage à long terme dans des dispositifs de mémoire à changement de phase (PCM), mise à jour quasi-linéaire des condensateurs conventionnels à semi-conducteurs à oxyde métallique complémentaire (CMOS) et de nouvelles techniques pour annuler la variabilité d'un appareil à l'autre, nous avons affiné ces imperfections et obtenu des précisions DNN équivalentes au logiciel sur une variété de réseaux différents. Ces expériences ont utilisé une approche mixte matériel-logiciel, combinant des simulations logicielles d'éléments du système faciles à modéliser avec précision (tels que des dispositifs CMOS) avec une implémentation matérielle complète des dispositifs PCM. Il était essentiel d'utiliser de véritables dispositifs de mémoire analogique pour chaque poids dans nos réseaux de neurones, parce que les approches de modélisation pour ces nouveaux appareils échouent souvent à capturer toute la gamme de variabilité d'un appareil à l'autre qu'ils peuvent présenter.
En utilisant cette approche, nous avons vérifié que les puces complètes devaient bien offrir une précision équivalente, et ainsi faire le même travail qu'un accélérateur numérique - mais plus rapidement et à plus faible puissance. Face à ces résultats encourageants, nous avons déjà commencé à explorer la conception de prototypes de puces d'accélérateur matériel, dans le cadre d'un projet de l'IBM Research Frontiers Institute.
À partir de ces premiers efforts de conception, nous avons été en mesure de fournir, dans le cadre de notre article Nature, estimations initiales du potentiel de ces puces basées sur NVM pour la formation de couches entièrement connectées, en termes d'efficacité énergétique de calcul (28, 065 GOP/sec/W) et débit par zone (3,6 TOP/sec/mm2). Ces valeurs dépassent les spécifications des GPU d'aujourd'hui de deux ordres de grandeur. Par ailleurs, Les couches entièrement connectées sont un type de couche de réseau neuronal pour laquelle les performances réelles du GPU sont souvent bien inférieures aux spécifications nominales.
Cet article indique que notre approche basée sur la NVM peut fournir des précisions d'entraînement équivalentes au logiciel ainsi que des ordres de grandeur d'amélioration de l'accélération et de l'efficacité énergétique malgré les imperfections des dispositifs de mémoire analogique existants. Les prochaines étapes consisteront à démontrer cette même équivalence logicielle sur de plus grands réseaux nécessitant de grands, des couches entièrement connectées - telles que les réseaux de mémoire à long court terme (LSTM) et d'unités récurrentes fermées (GRU) connectés de manière récurrente à l'origine des récentes avancées en matière de traduction automatique, le sous-titrage et l'analyse de texte - et pour concevoir, implémenter et affiner ces techniques analogiques sur des prototypes d'accélérateurs matériels basés sur NVM. De nouvelles et meilleures formes de mémoire analogique, optimisé pour cette application, pourrait contribuer à améliorer encore la densité surfacique et l'efficacité énergétique.