Figure 1 :Extension des quartiers à partir du nœud marron du milieu. Première extension :verte; deuxième :jaune; troisième :rouge.
Une structure de graphe est extrêmement utile pour prédire les propriétés de ses constituants. Le moyen le plus efficace d'effectuer cette prédiction consiste à mapper chaque entité à un vecteur grâce à l'utilisation de réseaux de neurones profonds. On peut déduire la similitude de deux entités sur la base de la proximité vectorielle. Un défi pour l'apprentissage en profondeur, cependant, est que l'on a besoin de rassembler des informations entre une entité et son voisinage étendu à travers les couches du réseau de neurones. Le quartier s'agrandit rapidement, rendant le calcul très coûteux. Pour résoudre ce défi, nous proposons une nouvelle approche, validé par des preuves mathématiques et des résultats expérimentaux, cela suggère qu'il suffit de rassembler les informations de seulement une poignée d'entités aléatoires dans chaque expansion de quartier. Cette réduction substantielle de la taille du quartier rend la même qualité de prédiction que les réseaux de neurones profonds de pointe, mais réduit les coûts de formation par des ordres de grandeur (par exemple, 10x à 100x moins de temps de calcul et de ressources), conduisant à une évolutivité attrayante. Notre article décrivant ce travail, "FastGCN :apprentissage rapide avec les réseaux convolutionnels de graphes via l'échantillonnage d'importance, " sera présenté à ICLR 2018. Mes co-auteurs sont Tengfei Ma et Cao Xiao.
Complexité de l'analyse graphique
Les graphiques sont des représentations universelles des relations par paires. Dans les applications du monde réel, ils se présentent sous diverses formes, comprenant par exemple, réseaux sociaux, réseaux d'expression génique, et des graphiques de connaissances. Un sujet tendance dans l'apprentissage en profondeur est d'étendre le succès remarquable des architectures de réseaux de neurones bien établies pour les données structurées euclidiennes (telles que les images et les textes) aux données irrégulièrement structurées, y compris les graphiques. Le réseau convolutif de graphe, GCN, est l'un de ces excellents exemples. Il généralise le concept de convolution pour les images, qui peut être considéré comme une grille de pixels, à des graphiques qui ne ressemblent plus à une grille régulière.
L'idée derrière GCN est très simple. Ceux d'entre nous qui ont suivi un cours de traitement du signal 101 ou un cours de vision par ordinateur de base sont déjà familiers avec le concept d'un filtre à convolution. Pour les images, c'est une petite matrice de nombres, à multiplier élément par élément avec une fenêtre mobile de l'image, avec la somme de produit résultante remplaçant le numéro central de la fenêtre. Pour les graphiques, c'est similaire. Une bonne combinaison des filtres peut détecter des structures locales primitives, comme des lignes sous différents angles, bords, coins, et des taches d'une certaine couleur. Pour les graphiques, les circonvolutions sont similaires. Imaginez que chaque nœud du graphe soit initialement attaché à un vecteur. Pour chaque nœud, les vecteurs des voisins y sont additionnés (avec certains poids et transformations). D'où, tous les nœuds sont mis à jour simultanément, effectuer une couche de propagation vers l'avant. Des convolutions de graphe peuvent être utilisées pour propager des informations à travers des quartiers de sorte que des informations globales soient diffusées à chaque nœud de graphe.
Le problème de GCN est que pour un réseau à plusieurs couches, le quartier s'agrandit rapidement, impliquant de nombreux vecteurs à additionner, même pour un seul nœud. Un tel calcul est d'un coût prohibitif pour des graphes avec un grand nombre de nœuds. Quelle sera la taille d'un quartier élargi ? Dans l'analyse des réseaux sociaux, il existe un concept célèbre appelé « six degrés de séparation, " qui stipule que l'on peut atteindre n'importe quelle autre personne sur la Terre à travers six connexions intermédiaires ! La figure 1 illustre qu'en partant du nœud marron au centre, agrandissant le quartier trois fois (dans l'ordre du vert, jaune, et rouge) touchera presque tout le graphique. En d'autres termes, mettre à jour le vecteur du nœud brun seul est gênant pour un GCN avec aussi peu que trois couches.
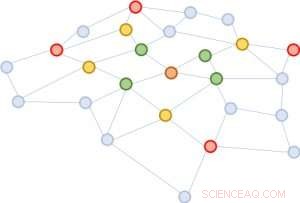
Figure 2 :En partant du même nœud marron, dans chaque extension de quartier, nous échantillonnons seulement quatre nœuds.
Simplifier pour l'évolutivité
Nous proposons une solution simple mais puissante, appelé FastGCN. Si l'expansion complète du quartier coûte cher, pourquoi ne pas étendre sur seulement quelques voisins à chaque fois ? La figure 2 illustre le concept. En partant du nœud marron, dans chaque expansion, nous choisissons un nombre constant (quatre) de nœuds et faisons la somme sur les vecteurs à partir d'eux uniquement. L'échantillonnage réduit considérablement le coût de formation du réseau de neurones, en réduisant le temps de formation par des ordres de grandeur sur des ensembles de données de référence couramment utilisés par les chercheurs. Encore, les prédictions restent d'une précision comparable. La taille de ces graphes de référence va de quelques milliers de nœuds à quelques centaines de milliers de nœuds, confirmant l'évolutivité de notre méthode.
Derrière cette approche intuitive se cache une théorie mathématique pour l'approximation de la fonction de perte. Une couche du réseau peut se résumer par une multiplication matricielle :H'=s(AHW), où A est la matrice d'adjacence du graphe, chaque ligne de H est le vecteur attaché aux nœuds, W est une transformation linéaire des vecteurs (également interprétée comme le paramètre du modèle à apprendre), et les lignes de H' contiennent les vecteurs mis à jour. On généralise cette multiplication matricielle à une transformée intégrale h'(v)=s(òA(v, u)h(u)W dP(u)) sous une mesure de probabilité P. Alors, l'échantillonnage d'un nombre fixe de voisins dans chaque développement n'est rien d'autre qu'une approximation de Monte Carlo de l'intégrale sous la mesure P. L'approximation de Monte Carlo donne un estimateur cohérent de la fonction de perte ; Par conséquent, en prenant la pente, nous pouvons utiliser une méthode d'optimisation standard (telle que la descente de gradient stochastique) pour entraîner le réseau de neurones.
Un éventail d'applications d'apprentissage en profondeur
Notre approche répond à un défi clé dans l'apprentissage en profondeur pour les graphiques à grande échelle. Il s'applique non seulement au GCN mais également à de nombreux autres réseaux de neurones graphiques construits sur le concept d'expansion de voisinage, une composante essentielle de l'apprentissage de la représentation graphique. Nous prévoyons que la résolution du défi dans cette structure de données fondamentale - les graphes - sera adoptée dans un large éventail d'applications, y compris l'analyse des réseaux sociaux, la connaissance approfondie des interactions protéine-protéine pour la découverte de médicaments, et la conservation et la découverte d'informations dans des bases de connaissances.