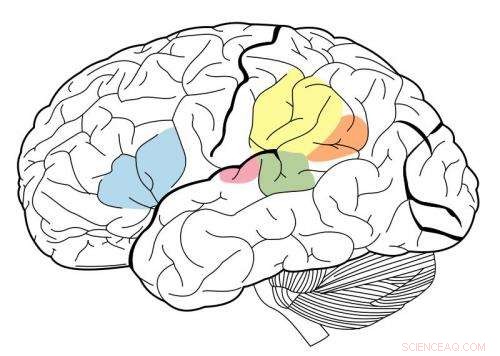
Le cortex auditif primaire est surligné en magenta, et est connu pour interagir avec toutes les zones mises en évidence sur cette carte neuronale. Crédit :Wikipédia.
En utilisant un système d'apprentissage automatique connu sous le nom de réseau de neurones profonds, Des chercheurs du MIT ont créé le premier modèle capable de reproduire la performance humaine sur des tâches auditives telles que l'identification d'un genre musical.
Ce modèle, qui se compose de nombreuses couches d'unités de traitement de l'information qui peuvent être formées sur d'énormes volumes de données pour effectuer des tâches spécifiques, a été utilisé par les chercheurs pour faire la lumière sur la façon dont le cerveau humain peut effectuer les mêmes tâches.
"Ce que ces modèles nous donnent, pour la première fois, sont des systèmes de machines qui peuvent effectuer des tâches sensorielles importantes pour les humains et qui le font à des niveaux humains, " dit Josh McDermott, Frederick A. et Carole J. Middleton professeur adjoint de neurosciences au département des sciences du cerveau et des sciences cognitives du MIT et auteur principal de l'étude. « Historiquement, ce type de traitement sensoriel a été difficile à comprendre, en partie parce que nous n'avons pas vraiment de fondement théorique très clair et un bon moyen de développer des modèles de ce qui pourrait se passer. »
L'étude, qui paraît dans le numéro du 19 avril de Neurone , offre également la preuve que le cortex auditif humain est organisé dans une organisation hiérarchique, un peu comme le cortex visuel. Dans ce type d'aménagement, les informations sensorielles passent par des étapes successives de traitement, avec des informations de base traitées plus tôt et des fonctionnalités plus avancées telles que le sens des mots extraits à des étapes ultérieures.
Alexander Kell, étudiant diplômé du MIT, et Daniel Yamins, professeur adjoint à l'Université de Stanford, sont les principaux auteurs de l'article. Les autres auteurs sont l'ancienne étudiante invitée du MIT Erica Shook et l'ancien postdoctorant du MIT Sam Norman-Haignere.
Modéliser le cerveau
Lorsque les réseaux de neurones profonds ont été développés pour la première fois dans les années 1980, les neuroscientifiques espéraient que de tels systèmes pourraient être utilisés pour modéliser le cerveau humain. Cependant, les ordinateurs de cette époque n'étaient pas assez puissants pour construire des modèles assez grands pour effectuer des tâches du monde réel telles que la reconnaissance d'objets ou la reconnaissance vocale.
Au cours des cinq dernières années, les progrès de la puissance de calcul et de la technologie des réseaux neuronaux ont permis d'utiliser les réseaux neuronaux pour effectuer des tâches difficiles du monde réel, et ils sont devenus l'approche standard dans de nombreuses applications d'ingénierie. En parallèle, certains neuroscientifiques ont réexaminé la possibilité que ces systèmes puissent être utilisés pour modéliser le cerveau humain.
« Cela a été une opportunité passionnante pour les neurosciences, en ce que nous pouvons réellement créer des systèmes qui peuvent faire certaines des choses que les gens peuvent faire, et nous pouvons alors interroger les modèles et les comparer au cerveau, " dit Kell.
Les chercheurs du MIT ont entraîné leur réseau de neurones à effectuer deux tâches auditives, l'un impliquant la parole et l'autre impliquant la musique. Pour la tâche de parole, les chercheurs ont donné au modèle des milliers d'enregistrements de deux secondes d'une personne parlant. La tâche consistait à identifier le mot au milieu du clip. Pour la tâche musicale, le modèle a été invité à identifier le genre d'un clip de musique de deux secondes. Chaque clip incluait également un bruit de fond pour rendre la tâche plus réaliste (et plus difficile).
Après plusieurs milliers d'exemples, le modèle a appris à effectuer la tâche avec la même précision qu'un auditeur humain.
"L'idée est qu'avec le temps, le modèle s'améliore de plus en plus dans la tâche, " dit Kell. " L'espoir est qu'il apprend quelque chose de général, donc si vous présentez un nouveau son que le modèle n'a jamais entendu auparavant, ça ira bien, et dans la pratique c'est souvent le cas."
Le modèle avait également tendance à faire des erreurs sur les mêmes clips sur lesquels les humains ont fait le plus d'erreurs.
Les unités de traitement qui composent un réseau de neurones peuvent être combinées de diverses manières, formant différentes architectures qui affectent les performances du modèle.
L'équipe du MIT a découvert que le meilleur modèle pour ces deux tâches était celui qui divisait le traitement en deux ensembles d'étapes. La première série d'étapes a été partagée entre les tâches, mais après ça, il s'est divisé en deux branches pour une analyse plus approfondie - une branche pour la tâche de parole, et un pour la tâche de genre musical.
Preuve de la hiérarchie
Les chercheurs ont ensuite utilisé leur modèle pour explorer une question de longue date sur la structure du cortex auditif :s'il est organisé hiérarchiquement.
Dans un système hiérarchique, une série de régions du cerveau effectue différents types de calculs sur les informations sensorielles lorsqu'elles circulent dans le système. Il a été bien documenté que le cortex visuel a ce type d'organisation. Régions antérieures, connu comme le cortex visuel primaire, répondre à des caractéristiques simples telles que la couleur ou l'orientation. Les étapes ultérieures permettent des tâches plus complexes telles que la reconnaissance d'objets.
Cependant, il a été difficile de tester si ce type d'organisation existe également dans le cortex auditif, en partie parce qu'il n'y a pas eu de bons modèles qui peuvent reproduire le comportement auditif humain.
« Nous avons pensé que si nous pouvions construire un modèle qui pourrait faire certaines des mêmes choses que les gens font, nous pourrions alors être en mesure de comparer différentes étapes du modèle à différentes parties du cerveau et d'obtenir des preuves pour savoir si ces parties du cerveau pourraient être organisées hiérarchiquement, " dit McDermott.
Les chercheurs ont découvert que dans leur modèle, les caractéristiques de base du son telles que la fréquence sont plus faciles à extraire au début. Au fur et à mesure que l'information est traitée et se déplace plus loin le long du réseau, il devient plus difficile d'extraire la fréquence mais plus facile d'extraire des informations de niveau supérieur telles que des mots.
Pour voir si les étapes du modèle pourraient reproduire la façon dont le cortex auditif humain traite les informations sonores, les chercheurs ont utilisé l'imagerie par résonance magnétique fonctionnelle (IRMf) pour mesurer différentes régions du cortex auditif pendant que le cerveau traite les sons du monde réel. Ils ont ensuite comparé les réponses du cerveau aux réponses du modèle lorsqu'il traitait les mêmes sons.
Ils ont constaté que les stades intermédiaires du modèle correspondaient le mieux à l'activité du cortex auditif primaire, et les stades ultérieurs correspondaient le mieux à l'activité en dehors du cortex primaire. Cela prouve que le cortex auditif pourrait être organisé de manière hiérarchique, semblable au cortex visuel, disent les chercheurs.
"Ce que nous voyons très clairement, c'est une distinction entre le cortex auditif primaire et tout le reste, " dit McDermott.
Les auteurs envisagent maintenant de développer des modèles capables d'effectuer d'autres types de tâches auditives, comme déterminer l'emplacement d'où provient un son particulier, pour explorer si ces tâches peuvent être effectuées par les voies identifiées dans ce modèle ou si elles nécessitent des voies distinctes, qui pourrait ensuite être étudié dans le cerveau.