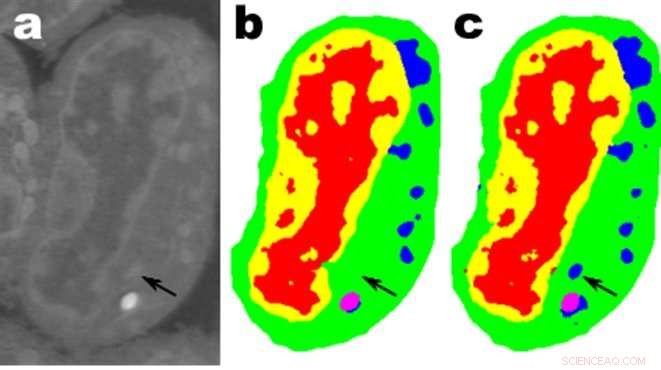
Images d'une tranche de cellules lymphblastoïdes de souris ; une. sont les données brutes, b est la segmentation manuelle correspondante et c est la sortie d'un réseau MS-D à 100 couches. Crédit :Données de A. Ekman et C. Larabell, Centre national de tomographie par rayons X.
Les mathématiciens du Lawrence Berkeley National Laboratory (Berkeley Lab) du département de l'Énergie ont développé une nouvelle approche de l'apprentissage automatique visant les données d'imagerie expérimentales. Plutôt que de vous fier aux dizaines ou centaines de milliers d'images utilisées par les méthodes d'apprentissage automatique typiques, cette nouvelle approche « apprend » beaucoup plus rapidement et nécessite beaucoup moins d'images.
Daniël Pelt et James Sethian du Berkeley Lab's Center for Advanced Mathematics for Energy Research Applications (CAMERA) ont renversé la perspective habituelle de l'apprentissage automatique en développant ce qu'ils appellent un « réseau neuronal à convolution dense à échelle mixte (MS-D) » qui nécessite beaucoup moins de paramètres que les méthodes traditionnelles, converge rapidement, et a la capacité d'"apprendre" à partir d'un ensemble de formation remarquablement petit. Leur approche est déjà utilisée pour extraire la structure biologique des images cellulaires, et est sur le point de fournir un nouvel outil informatique majeur pour analyser les données dans un large éventail de domaines de recherche.
Comme les installations expérimentales génèrent des images de plus haute résolution à des vitesses plus élevées, les scientifiques peuvent avoir du mal à gérer et à analyser les données résultantes, ce qui est souvent fait minutieusement à la main. En 2014, Sethian a créé CAMERA à Berkeley Lab en tant que société intégrée, centre interdisciplinaire pour développer et fournir de nouvelles mathématiques fondamentales nécessaires pour capitaliser sur les recherches expérimentales dans les installations des utilisateurs du DOE Office of Science. CAMERA fait partie de la division de recherche informatique du laboratoire.
« Dans de nombreuses applications scientifiques, un travail manuel énorme est nécessaire pour annoter et étiqueter les images - cela peut prendre des semaines pour produire une poignée d'images soigneusement délimitées, " dit Sethian, qui est également professeur de mathématiques à l'Université de Californie, Berkeley. "Notre objectif était de développer une technique qui apprend à partir d'un très petit ensemble de données."
Les détails de l'algorithme ont été publiés le 26 décembre 2017 dans un article du Actes de l'Académie nationale des sciences .
« La percée a résulté de la prise de conscience que la réduction et la mise à l'échelle habituelles qui capturent des caractéristiques à différentes échelles d'image pourraient être remplacées par des convolutions mathématiques gérant plusieurs échelles au sein d'une seule couche, " dit Pelt, qui est également membre du Computational Imaging Group du Centrum Wiskunde &Informatica, l'institut national de recherche pour les mathématiques et l'informatique aux Pays-Bas.
Pour rendre l'algorithme accessible à un large éventail de chercheurs, une équipe de Berkeley dirigée par Olivia Jain et Simon Mo a construit un portail Web "Segmenting Labeled Image Data Engine (SlideCAM)" dans le cadre de la suite d'outils CAMERA pour les installations expérimentales du DOE.

Images tomographiques d'un mini-composite renforcé de fibres, reconstruit en utilisant 1024 projections (a) et 120 projections (b). En (c), la sortie d'un réseau MS-D avec l'image (b) comme entrée est représentée. Une petite région indiquée par un carré rouge est agrandie dans le coin inférieur droit de chaque image. Crédit :Daniël Pelt et James Sethian, Laboratoire de Berkeley
Une application prometteuse est la compréhension de la structure interne des cellules biologiques et un projet dans lequel la méthode MS-D de Pelt et Sethian n'avait besoin que des données de sept cellules pour déterminer la structure cellulaire.
« Dans notre laboratoire, nous travaillons à comprendre comment la structure et la morphologie cellulaires influencent ou contrôlent le comportement cellulaire. Nous passons d'innombrables heures à segmenter manuellement les cellules afin d'en extraire la structure, et identifier, par exemple, différences entre les cellules saines et les cellules malades, " a déclaré Carolyn Larabell, Directeur du National Center for X-ray Tomography et professeur à la faculté de médecine de l'Université de Californie à San Francisco. « Cette nouvelle approche a le potentiel de transformer radicalement notre capacité à comprendre la maladie, et est un outil clé dans notre nouveau projet parrainé par Chan-Zuckerberg pour établir un Atlas des cellules humaines, une collaboration mondiale pour cartographier et caractériser toutes les cellules d'un corps humain sain."
Obtenir plus de science avec moins de données
Les images sont partout. Les téléphones intelligents et les capteurs ont produit un trésor d'images, beaucoup étiquetés avec des informations pertinentes identifiant le contenu. Grâce à cette vaste base de données d'images croisées, les réseaux de neurones convolutifs et d'autres méthodes d'apprentissage automatique ont révolutionné notre capacité à identifier rapidement des images naturelles qui ressemblent à celles déjà vues et cataloguées.
Ces méthodes « apprennent » en réglant un ensemble étonnamment grand de paramètres internes cachés, guidé par des millions d'images taguées, et nécessitant de grandes quantités de temps de supercalculateur. Mais que faire si vous n'avez pas autant d'images taguées ? Dans de nombreux domaines, une telle base de données est un luxe inatteignable. Les biologistes enregistrent des images cellulaires et dessinent minutieusement les frontières et la structure à la main :il n'est pas rare qu'une personne passe des semaines à créer une seule image entièrement tridimensionnelle. Les scientifiques des matériaux utilisent la reconstruction tomographique pour scruter l'intérieur des roches et des matériaux, puis retrousser leurs manches pour étiqueter différentes régions, identifier les fissures, fractures, et vide à la main. Les contrastes entre des structures différentes mais importantes sont souvent très faibles et le "bruit" dans les données peut masquer des caractéristiques et confondre le meilleur des algorithmes (et des humains).
Ces précieuses images sélectionnées à la main sont loin d'être suffisantes pour les méthodes traditionnelles d'apprentissage automatique. Pour relever ce défi, les mathématiciens de CAMERA ont attaqué le problème de l'apprentissage automatique à partir de quantités très limitées de données. Essayer de faire "plus avec moins, " leur objectif était de comprendre comment construire un ensemble efficace d'"opérateurs" mathématiques qui pourraient réduire considérablement le nombre de paramètres. Ces opérateurs mathématiques pourraient naturellement incorporer des contraintes clés pour aider à l'identification, comme en incluant des exigences sur des formes et des motifs scientifiquement plausibles.
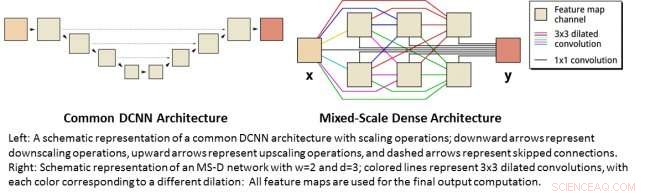
À gauche :une représentation schématique d'une architecture DCNN commune avec des opérations de mise à l'échelle ; les flèches vers le bas représentent les opérations de réduction d'échelle, les flèches vers le haut représentent les opérations de mise à l'échelle et les flèches en pointillés représentent les connexions ignorées. A droite :représentation schématique d'un réseau MS-D avec w=2 et d=3 ; les lignes colorées représentent 3x3 circonvolutions dilatées, avec chaque couleur correspondant à une dilatation différente :Toutes les cartes de caractéristiques sont utilisées pour le calcul de sortie final. Crédit :Daniël Pelt et James Sethian, Laboratoire de Berkeley
Réseaux de neurones à convolution dense à échelle mixte
De nombreuses applications de l'apprentissage automatique aux problèmes d'imagerie utilisent des réseaux de neurones à convolution profonde (DCNN), dans lequel l'image d'entrée et les images intermédiaires sont convoluées en un grand nombre de couches successives, permettant au réseau d'apprendre des caractéristiques hautement non linéaires. Pour obtenir des résultats précis pour les problèmes de traitement d'image difficiles, Les DCNN reposent généralement sur des combinaisons d'opérations et de connexions supplémentaires, notamment :par exemple, opérations de mise à l'échelle et de mise à l'échelle pour capturer des caractéristiques à différentes échelles d'image. Pour former des réseaux plus profonds et plus puissants, des types de couches et des connexions supplémentaires sont souvent nécessaires. Finalement, Les DCNN utilisent généralement un grand nombre d'images intermédiaires et de paramètres entraînables, souvent plus de 100 millions, pour obtenir des résultats pour des problèmes difficiles.
Au lieu, la nouvelle architecture de réseau "Mixed-Scale Dense" évite bon nombre de ces complications et calcule des convolutions dilatées comme substitut aux opérations de mise à l'échelle pour capturer des caractéristiques à différentes plages spatiales, en utilisant plusieurs échelles au sein d'une seule couche, et reliant de manière dense toutes les images intermédiaires. Le nouvel algorithme permet d'obtenir des résultats précis avec peu d'images et de paramètres intermédiaires, éliminant à la fois le besoin de régler les hyperparamètres et les couches ou connexions supplémentaires pour permettre la formation.
Obtenir de la science à haute résolution à partir de données à basse résolution
Un autre défi consiste à produire des images haute résolution à partir d'une entrée basse résolution. Comme tous ceux qui ont essayé d'agrandir une petite photo et ont trouvé qu'elle ne faisait qu'empirer à mesure qu'elle grandissait, cela semble presque impossible. Mais un petit ensemble d'images d'entraînement traitées avec un réseau dense à échelle mixte peut fournir un réel progrès. Par exemple, imaginez essayer de débruiter des reconstructions tomographiques d'un matériau mini-composite renforcé de fibres. Dans une expérience décrite dans l'article, les images ont été reconstruites en utilisant 1, 024 projections de rayons X acquises pour obtenir des images avec des quantités de bruit relativement faibles. Des images bruitées du même objet ont ensuite été obtenues par reconstruction à l'aide de 128 projections. Les entrées d'entraînement étaient des images bruitées, avec des images sans bruit correspondantes utilisées comme sortie cible pendant l'entraînement. Le réseau formé a ensuite été capable de prendre efficacement des données d'entrée bruitées et de reconstruire des images à plus haute résolution.
Nouvelles applications
Pelt et Sethian abordent une multitude de nouveaux domaines, telles que l'analyse rapide en temps réel des images provenant de sources de lumière synchrotron et les problèmes de reconstruction dans la reconstruction biologique comme pour les cellules et la cartographie du cerveau.
"Ces nouvelles approches sont vraiment passionnantes, car ils permettront l'application de l'apprentissage automatique à une bien plus grande variété de problèmes d'imagerie qu'il n'est actuellement possible, " Pelt a déclaré. " En réduisant la quantité d'images d'entraînement requises et en augmentant la taille des images qui peuvent être traitées, la nouvelle architecture peut être utilisée pour répondre à des questions importantes dans de nombreux domaines de recherche."














