L'interface LIQUIDE. Crédit :Laboratoire national du Nord-Ouest du Pacifique
Les lipides jouent un rôle clé dans de nombreuses maladies métaboliques, y compris l'hypertension, Diabète, et accident vasculaire cérébral. Il est donc important d'avoir un profil complet des lipides du corps – son « lipidome » – est important.
Les études de lipidomique sont souvent basées sur la chromatographie liquide couplée à la spectrométrie de masse en tandem (LC-MS/MS). Mais les chercheurs ont du mal à traiter les données assez rapidement, et ils sont incapables d'identifier et de quantifier avec précision les espèces lipidiques détectées.
Des identifications incorrectes peuvent entraîner des interprétations biologiques trompeuses. Pourtant, les outils existants ne sont pas conçus pour la vérification à grand volume des identifications et doivent être vérifiés manuellement pour garantir l'exactitude. Étant donné que les scientifiques souhaitent de plus en plus des études lipidomiques à plus grande échelle, les analystes ont besoin d'un logiciel amélioré pour identifier les lipides.
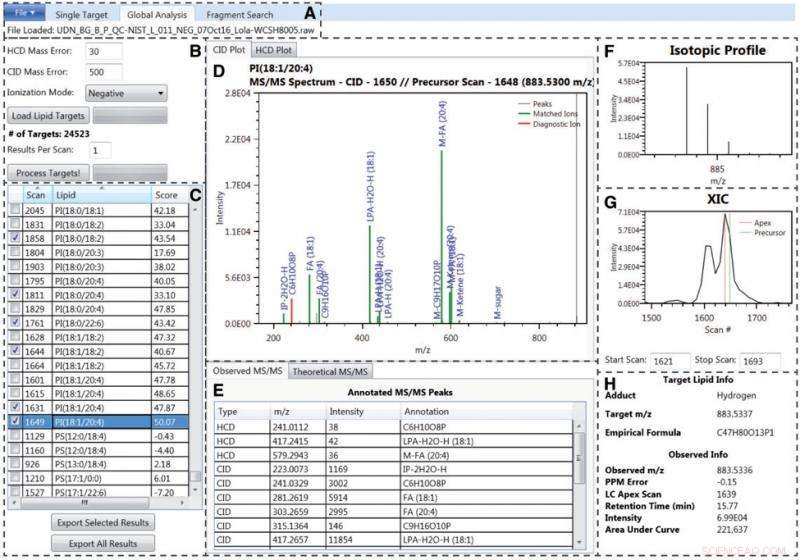
Un article récent de l'auteur principal Jennifer E. Kyle et de huit co-auteurs du Pacific Northwest National Laboratory (PNNL) présente un logiciel d'identification des lipides open source, Quantification et identification des lipides (LIQUIDE). La notation est entraînable, la base de recherche est personnalisable, et plusieurs éléments de preuve sont affichés, permettant des identifications sûres. LIQUID met également à disposition des recherches sur cible unique et globale, ainsi que des recherches de modèle de fragment. Tout cela permet aux chercheurs de suivre des modèles similaires et répétés de spectres MS/MS.
Par rapport à d'autres logiciels gratuits couramment utilisés pour identifier les lipides et autres petites molécules, LIQUID a un temps de traitement rapide qui peut générer un plus grand nombre d'identifications lipidiques validées plus rapidement. Sa base de données de référence comprend plus de 21, 200 cibles lipidiques uniques dans six catégories de lipides, 24 cours, et 63 sous-classes.
LIQUID est capable d'identifier en toute confiance plus d'espèces lipidiques avec un temps de traitement et de validation combiné plus rapide que tout autre logiciel dans son domaine.
Et après?
Les développeurs de LIQUID augmenteront la bibliothèque de référence pour inclure des lipides qui peuvent être uniques à des états pathologiques particuliers ou à des organismes de niches environnementales sélectionnées. Cela signifie que les chercheurs seront en mesure de caractériser une gamme plus diversifiée d'échantillons et donc d'améliorer la compréhension des systèmes biologiques et environnementaux d'intérêt.