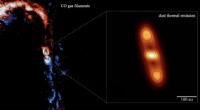
Cassiopée A, ou Cas A, est un vestige de supernova situé à 10, 000 années-lumière dans la constellation de Cassiopée, et est le vestige d'une étoile autrefois massive qui est morte dans une violente explosion il y a environ 340 ans. Cette image superpose l'infrarouge, visible, et des données de rayons X pour révéler des structures filamenteuses de poussière et de gaz. Cas A fait partie des 10 % de supernovae que les scientifiques peuvent étudier de près. Le nouveau projet d'apprentissage automatique de CfA aidera à classer des milliers, et finalement des millions, de supernovae potentiellement intéressantes qui pourraient autrement ne jamais être étudiées. Crédit :NASA/JPL-Caltech/STScI/CXC/SAO
L'intelligence artificielle classe les véritables explosions de supernova sans l'utilisation traditionnelle de spectres, grâce à une équipe d'astronomes du Centre d'Astrophysique | Harvard et Smithsonian. Les ensembles de données complets et les classifications résultantes sont accessibles au public pour une utilisation ouverte.
En entraînant un modèle d'apprentissage automatique pour catégoriser les supernovae en fonction de leurs caractéristiques visibles, les astronomes ont pu classer les données réelles du Pan-STARRS1 Medium Deep Survey pour 2, 315 supernovae avec un taux de précision de 82 % sans l'utilisation de spectres.
Les astronomes ont développé un logiciel qui classe différents types de supernovae en fonction de leurs courbes de lumière, ou comment leur luminosité change au fil du temps. "Nous en avons environ 2, 500 supernovae avec des courbes de lumière du Pan-STARRS1 Medium Deep Survey, et de ceux-là, 500 supernovae avec des spectres utilisables pour la classification, " dit Griffin Hosseinzadeh, chercheur postdoctoral au CfA et auteur principal du premier des deux articles publiés dans Le Journal d'Astrophysique . "Nous avons entraîné le classificateur en utilisant ces 500 supernovae pour classer les supernovae restantes où nous n'étions pas en mesure d'observer le spectre."
Edo Berger, un astronome du CfA a expliqué qu'en demandant à l'intelligence artificielle de répondre à des questions précises, les résultats deviennent de plus en plus précis. « Le machine learning recherche une corrélation avec les 500 marqueurs spectroscopiques originaux. Nous lui demandons de comparer les supernovae dans différentes catégories :couleur, vitesse d'évolution, ou la luminosité. En l'alimentant de véritables connaissances existantes, il conduit à la plus grande précision, entre 80 et 90 %."
Bien qu'il ne s'agisse pas du premier projet d'apprentissage automatique pour la classification des supernovae, c'est la première fois que des astronomes ont accès à un ensemble de données réel suffisamment grand pour former un classificateur de supernovae basé sur l'intelligence artificielle, permettant de créer des algorithmes d'apprentissage automatique sans l'utilisation de simulations.
"Si vous faites une courbe de lumière simulée, cela signifie que vous faites une hypothèse sur ce à quoi ressembleront les supernovae, et votre classificateur apprendra alors également ces hypothèses, " dit Hosseinzadeh. " La nature apportera toujours des complications supplémentaires dont vous n'avez pas tenu compte, ce qui signifie que votre classificateur ne fonctionnera pas aussi bien sur des données réelles que sur des données simulées. Parce que nous avons utilisé des données réelles pour former nos classificateurs, cela signifie que notre précision mesurée est probablement plus représentative de la façon dont nos classificateurs fonctionneront sur d'autres enquêtes. » Comme le classificateur catégorise les supernovae, dit Berger, "Nous pourrons les étudier à la fois rétrospectivement et en temps réel pour sélectionner les événements les plus intéressants pour un suivi détaillé. Nous utiliserons l'algorithme pour nous aider à choisir les aiguilles et également à regarder la botte de foin."
Le projet a des implications non seulement pour les données d'archives, mais aussi pour les données qui seront collectées par les futurs télescopes. L'Observatoire Vera C. Rubin devrait être mis en ligne en 2023, et conduira à la découverte de millions de nouvelles supernovae chaque année. Cela présente à la fois des opportunités et des défis pour les astrophysiciens, où le temps limité du télescope conduit à des classifications spectrales limitées.
« Lorsque l'Observatoire Rubin sera en ligne, notre taux de découverte de supernovae sera multiplié par 100, mais nos ressources spectroscopiques n'augmenteront pas, " a déclaré Ashley Villar, un Simons Junior Fellow à Columbia University et auteur principal du deuxième des deux articles, ajoutant que tandis qu'environ 10, 000 supernovae sont actuellement découvertes chaque année, les scientifiques ne prennent que des spectres d'environ 10 pour cent de ces objets. « Si cela est vrai, cela signifie que seulement 0,1 pour cent des supernovae découvertes par l'observatoire Rubin chaque année obtiendront une étiquette spectroscopique. Les 99,9 % des données restantes seront inutilisables sans des méthodes comme la nôtre."
Contrairement aux efforts passés, où les ensembles de données et les classifications n'étaient disponibles qu'à un nombre limité d'astronomes, les ensembles de données du nouvel algorithme d'apprentissage automatique seront rendus publics. Les astronomes ont créé des logiciel accessible, et a également publié toutes les données de Pan-STARRS1 Medium Deep Survey ainsi que les nouvelles classifications à utiliser dans d'autres projets. Hosseinzadeh a dit, "Il était vraiment important pour nous que ces projets soient utiles à l'ensemble de la communauté des supernovas, pas seulement pour notre groupe. Il y a tellement de projets qui peuvent être réalisés avec ces données que nous ne pourrions jamais tous les faire nous-mêmes. » Berger a ajouté, "Ces projets sont des données ouvertes pour une science ouverte."